Notions fondamentales du pipeline de livraison continue
Découvrez comment les builds, les tests et les déploiements automatisés sont reliés entre eux pour former un workflow de livraison unique.

Juni Mukherjee
Expert en développement
Qu'est-ce qu'un pipeline de livraison continue ?
Un pipeline de livraison continue est une série de processus automatisés destinés à livrer de nouveaux logiciels. Il s'agit d'une implémentation du paradigme « Continuous Everything », où les builds, les tests et les déploiements automatisés sont orchestrés pour former un workflow de livraison unique. En d'autres termes, un pipeline CD est un ensemble d'étapes par lesquelles passent vos changements de code avant d'arriver en production.
Conformément aux besoins métier, un pipeline CD livre des produits de qualité de manière fréquente et prévisible, des tests à la production, de manière automatisée.
Pour commencer, concentrons-nous sur les trois concepts de qualité, fréquence et prévisibilité.
We emphasize quality to underscore that it’s not traded for speed. Business doesn’t want us to build a pipeline that can shoot faulty code to production at high speed. We will go through the principles of “Shift Left” and “DevSecOps”, and discuss how we can move quality and security upstream in the software development life cycle (SDLC). This will put to rest any concerns regarding continuous delivery pipelines posing risks to businesses.
Il est fréquent que les pipelines s'exécutent à tout moment pour livrer des fonctionnalités, puisqu'ils sont programmés pour se déclencher grâce aux commits dans la base de code. Une fois le pipeline MVP (produit minimum viable) en place, il peut être exécuté autant de fois que nécessaire à un coût de maintenance périodique. Cette approche automatisée évolue sans pousser l'équipe à bout. Cela permet également aux équipes d'apporter de petites améliorations incrémentielles à leurs produits sans craindre une catastrophe majeure en production.
Découvrir la solution
Développez et exploitez des logiciels grâce à Open DevOps
Matériel connexe
Qu'est-ce que le pipeline DevOps ?
Aussi cliché que cela puisse paraître, l'idée selon laquelle « l'erreur est humaine » est toujours d'actualité. Les équipes se tiennent prêtes pour les impacts lors de livraisons manuelles, car ces processus sont fragiles. La prévisibilité implique que les livraisons sont déterministes par nature lorsqu'elles sont réalisées via des pipelines de livraison continue. Puisque les pipelines sont des infrastructures programmables, les équipes peuvent s'attendre au comportement souhaité à chaque fois. Des accidents peuvent évidemment se produire, car aucun logiciel n'est exempt de bugs. Cependant, les pipelines sont exponentiellement plus efficaces que les processus de livraison manuels sujets aux erreurs, car contrairement aux humains, les pipelines ne faiblissent pas face à des échéances serrées.
Les pipelines sont dotés de portes logicielles qui autorisent ou bloquent automatiquement le passage des artefacts versionnés. Si le protocole de livraison n'est pas respecté, les portes logicielles restent fermées, et le pipeline s'annule. Des alertes sont générées et des notifications sont envoyées à une liste de distribution comprenant les membres de l'équipe susceptibles d'être à l'origine du problème sur le pipeline.
C'est ainsi que fonctionne un pipeline de livraison continue : un commit, ou un petit lot incrémentiel de commits, est mis en production à chaque fois que le pipeline s'exécute correctement. À la fin, les équipes livrent des fonctionnalités (et en bout de ligne, des produits) dans un contexte sécurisé et vérifiable.
Les différentes phases d'un pipeline de livraison continue
L'architecture du produit qui parcourt le pipeline est un facteur clé qui détermine l'anatomie du pipeline de livraison continue. Une architecture de produit à couplage fort génère un modèle graphique complexe de pipelines, dans lequel de multiples pipelines s'enchevêtrent avant que le produit ne soit finalement mis en production.
L'architecture du produit affecte également les différentes phases du pipeline et les artefacts produits dans chaque phase. Abordons à présent les quatre phases courantes de livraison continue :
Même si vous prévoyez plus ou moins de quatre phases dans votre organisation, les concepts décrits ci-dessous s'appliquent toujours.
L'idée selon laquelle ces phases se manifestent matériellement dans votre pipeline est une méprise courante. En vérité, ce n'est pas le cas. Il s'agit de phases logiques qui peuvent être associées à des étapes importantes dans différents contextes (test, staging et production, par exemple). Par exemple, les composants et les sous-systèmes peuvent être développés, testés et déployés dans l'environnement de test. Les sous-systèmes ou les systèmes peuvent être assemblés, testés et déployés dans l'environnement de staging. Les sous-systèmes ou les systèmes peuvent être mis en production dans le cadre de la phase de production.
Le coût associé aux défauts est faible lorsque ces derniers sont détectés dans l'environnement de test, il est modéré lorsque les défauts sont détectés dans l'environnement de staging, et il est élevé en production. L'expression « Shift Left » signifie que les validations sont obtenues plus tôt dans le pipeline. De nos jours, la porte permettant au produit de passer de la phase de test à la phase de staging intègre des techniques défensives bien plus efficaces ; ainsi, la phase de staging ne ressemble plus à une scène de crime !
À l'origine, le service de sécurité informatique intervenait à la fin du cycle de vie de développement logiciel (SDLC) et rejetait les versions susceptibles de constituer une menace pour l'entreprise en termes de cybersécurité. Même si ses intentions étaient nobles, son action était source de frustration et de retards. Le principe « DevSecOps » préconise d'intégrer la sécurité dans les produits dès la phase de conception, au lieu d'envoyer pour évaluation un produit fini susceptible de présenter un danger.
Examinons de plus près la façon dont les concepts de « Shift Left » et de « DevSecOps » peuvent être traités dans le cadre d'un workflow de livraison continue. Dans les sections suivantes, nous aborderons en détail chacune des phases.
Phase Composant CD
Le pipeline développe d'abord les composants, à savoir, les plus petites unités distribuables et testables du produit. Par exemple, une bibliothèque développée par le pipeline peut être appelée composant. Un composant peut être certifié, entre autres, par des revues de code, des tests unitaires et des analyseurs de code statiques.
Les revues de code sont importantes pour que les équipes aient une compréhension commune des fonctionnalités, des tests et de l'infrastructure nécessaires à la mise en service du produit. Une deuxième paire d'yeux peut souvent faire des miracles. Au fil des ans, il se peut que nous nous soyons immunisés contre le mauvais code d'une manière telle que nous ne croyons plus qu'il est mauvais. De nouvelles perspectives peuvent nous obliger à réexaminer ces faiblesses et à les refactoriser généreusement au besoin.
Les tests unitaires sont presque toujours la première série de tests logiciels que nous exécutons sur notre code. Ils ne touchent ni la base de données ni le réseau. La couverture de code est le pourcentage de code qui a été touché par les tests unitaires. Il existe de nombreuses façons de mesurer la couverture, comme la couverture de ligne, la couverture de classe, la couverture de méthode, etc.
Bien qu'il soit formidable d'avoir une bonne couverture de code pour faciliter le refactoring, il est préjudiciable d'imposer des objectifs de couverture élevés. Contrairement à l'intuition, certaines équipes ayant une couverture de code élevée ont plus de pannes de production que les équipes ayant une couverture de code plus faible. Gardez également à l'esprit qu'il est facile de jouer avec les données liées à la couverture. Lorsqu'ils sont soumis à une forte pression, en particulier pendant les évaluations de performances, les développeurs peuvent recourir à des pratiques déloyales pour accroître la couverture de code. Je ne donnerai pas tous les détails ici !
Les analyses de code statiques détectent les problèmes dans le code sans l'exécuter. C'est un moyen de détection des problèmes peu coûteux. Comme les tests unitaires, ces tests sont exécutés sur le code source, et ce, rapidement. Les analyseurs statiques détectent les fuites de mémoire potentielles, ainsi que les indicateurs de qualité de code tels que la complexité cyclomatique et la duplication du code. Durant cette phase, le test dynamique de la sécurité des applications (SAST) est un moyen éprouvé de découvrir les failles de sécurité.
Définissez les métriques qui contrôlent vos portes logicielles et influencent la promotion du code de la phase Composant à la phase Sous-système.
Phase Sous-système CD
Les composants à couplage lâche constituent des sous-systèmes ; les plus petites unités déployables et exploitables. Par exemple, un serveur est un sous-système. Un microservice fonctionnant dans un conteneur est également un exemple de sous-système. Contrairement aux composants, les sous-systèmes peuvent être mis en place et validés en les comparant à des cas d'usage client.
Tout comme une interface utilisateur Node.js et une couche API Java sont des sous-systèmes, les bases de données sont aussi des sous-systèmes. Dans certaines organisations, les systèmes de gestion de bases de données relationnelles (SGBDR) sont gérés manuellement, même si une nouvelle génération d'outils a fait surface et automatise la gestion des changements de bases de données et assure la livraison continue des bases de données. Les pipelines CD impliquant des bases de données NoSQL sont plus faciles à implémenter que les SGBDR.
Les sous-systèmes peuvent être déployés et certifiés par des tests fonctionnels, de performance et de sécurité. Découvrons comment chacun de ces types de tests valide le produit.
Les tests fonctionnels incluent tous les cas d'usage client qui impliquent l'internationalisation (I18N), la localisation (L10N), la qualité des données, l'accessibilité, les scénarios négatifs, etc. Ces tests permettent de s'assurer que votre produit fonctionne conformément aux attentes du client, qu'il respecte l'inclusion et qu'il sert le marché pour lequel il a été conçu.
Déterminez vos benchmarks de performance avec vos Product Owners. Intégrez vos tests de performance au pipeline et utilisez les benchmarks pour adopter ou rejeter les pipelines. Un mythe répandu veut que les tests de performance n'ont pas besoin d'être intégrés aux pipelines de livraison continue, ce qui brise toutefois le paradigme de la continuité.
Les lignes de sécurité de grandes organisations ont été récemment percées, et les menaces contre la cybersécurité sont à leur plus haut niveau. Nous devons nous assurer qu'il n'y a aucune faille de sécurité dans nos produits, que ce soit dans le code que nous programmons ou dans les bibliothèques tierces que nous importons dans notre code. En réalité, des violations majeures ont été découvertes dans les logiciels open source (OSS), et nous devons utiliser des outils et des techniques qui signalent ces erreurs et forcent le pipeline à s'annuler. Le test dynamique de la sécurité des applications (DAST) est un moyen éprouvé de découvrir les failles de sécurité.
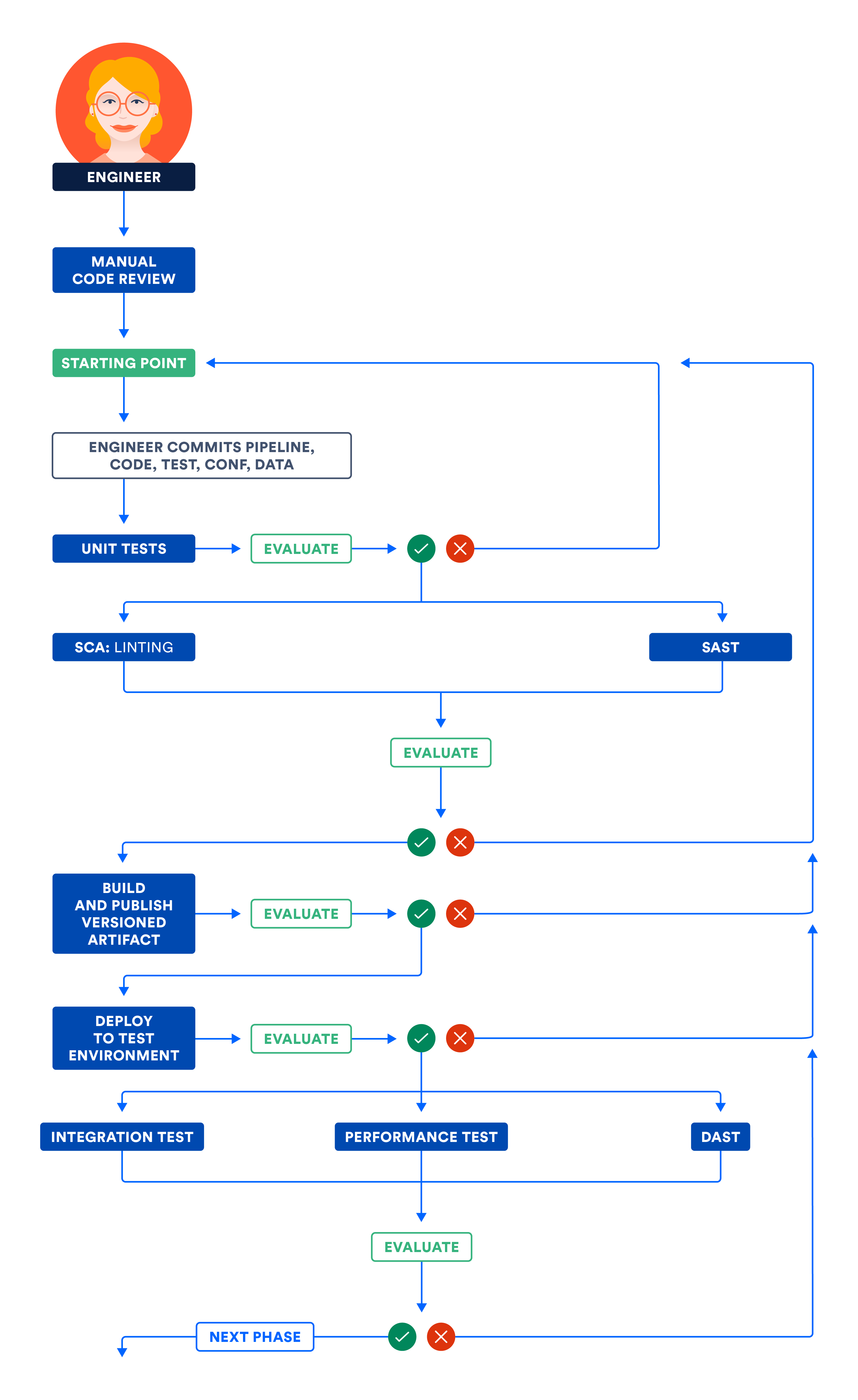
Le schéma suivant illustre le worklow décrit dans les phases Composant et Sous-système. Exécutez des étapes indépendantes en parallèle pour optimiser le temps total d'exécution du pipeline et obtenir un feedback rapide.
A) Certification des composants et/ou des sous-systèmes dans l'environnement de test
Phase Système CD
Une fois que les sous-systèmes répondent aux attentes en matière de fonctionnalité, de performance et de sécurité, le pipeline pourrait apprendre à assembler un système à partir de sous-systèmes à couplage lâche quand tout le système est livré en un bloc. Cela signifie que l'équipe la plus rapide peut s'adapter à la vitesse de l'équipe la plus lente. Cela me rappelle le vieux dicton : « La solidité d'une chaîne n'excède pas celle de son maillon le plus faible ».
Nous déconseillons cet anti-schéma où les sous-systèmes sont regroupés en un système à livrer en un bloc. En effet, pour que la livraison aboutisse dans cette approche, tous les sous-systèmes sont étroitement liés. Si vous investissez dans des artefacts déployables indépendamment, vous serez en mesure d'éviter cela.
Lorsque les systèmes doivent être validés de façon globale, ils peuvent être certifiés par des tests d'intégration, de performance et de sécurité. Contrairement à la phase Sous-système, n'utilisez pas de maquettes ou d'ébauches lors des tests dans cette phase. En outre, il est important de se concentrer sur le test des interfaces et du réseau.
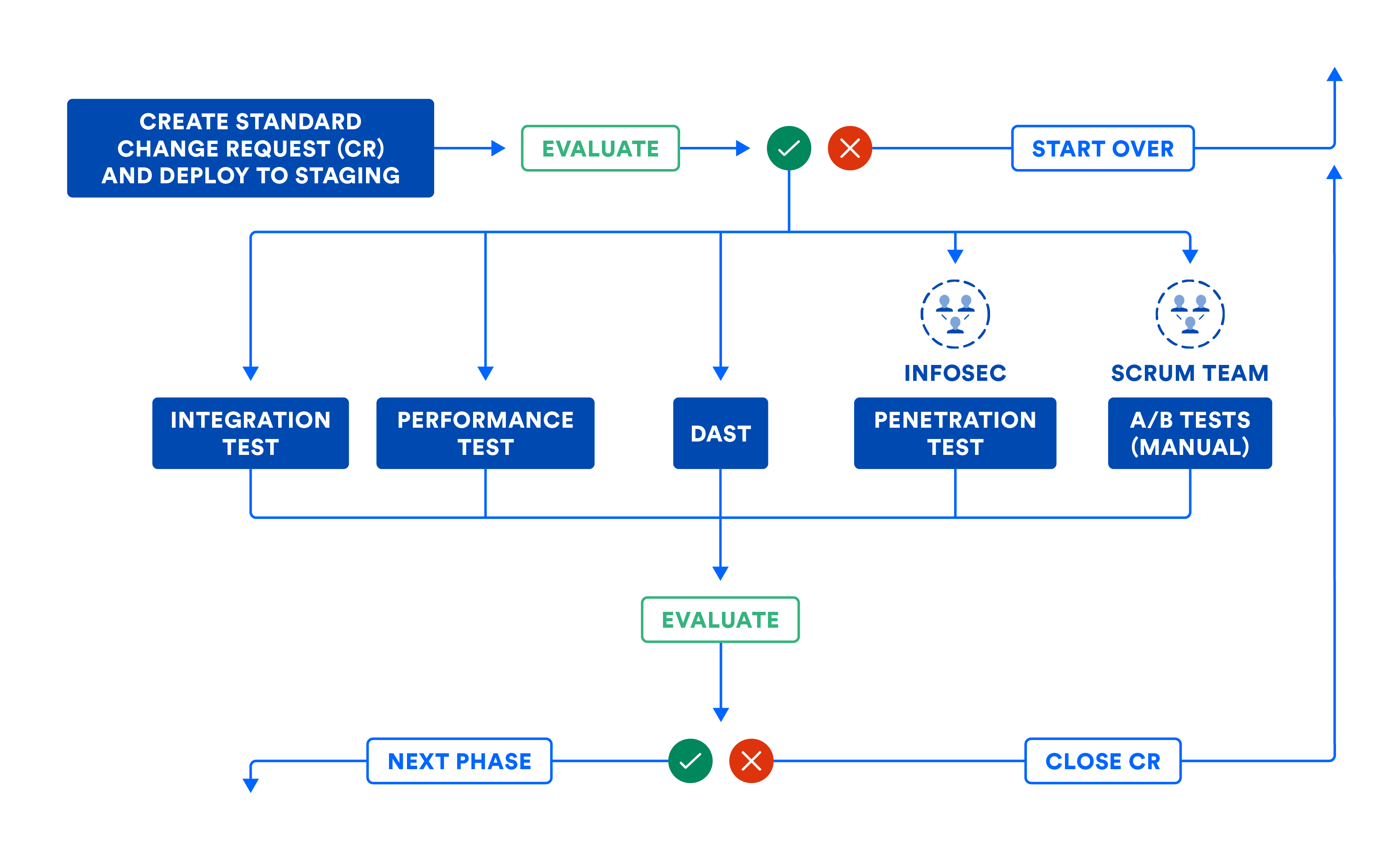
Si vous devez assembler vos sous-systèmes par composition, le schéma suivant résume le workflow de la phase Système. Même si vous pouvez faire passer vos sous-systèmes en production, l'illustration suivante vous aide à établir les portes logicielles nécessaires pour promouvoir le code de cette phase à la suivante.
Le pipeline peut automatiquement remplir la demande de changement (CR) pour donner une piste d'audit. La plupart des organisations utilisent ce workflow pour les changements standard, c'est-à-dire les livraisons planifiées. Ce workflow doit également être utilisé pour les changements urgents, ou les livraisons non planifiées, bien que certaines équipes aient tendance à brûler les étapes. Notez la manière dont la demande de changement (CR) est automatiquement clôturée par le pipeline CD lorsque des erreurs l'obligent à abandonner. Cela empêche d'abandonner les demandes de changement au beau milieu du workflow de pipeline.
Le schéma suivant illustre le worklow décrit dans la phase Système CD. Notez que certaines étapes peuvent nécessiter une intervention humaine et que ces étapes manuelles peuvent être exécutées dans le cadre de portes manuelles dans le pipeline. Lorsqu'elle est entièrement cartographiée, la visualisation du pipeline ressemble étroitement à la cartographie de la chaîne de valeur de vos livraisons de produits !
B) Certification des sous-systèmes et/ou du système dans l'environnement de staging
Une fois le système assemblé certifié, ne modifiez pas l'assembly et mettez-le en production.
Phase Production CD
Que les sous-systèmes puissent être déployés indépendamment ou qu'ils doivent être assemblés dans un système, ces artefacts versionnés sont déployés en production dans le cadre de cette phase finale.
Zero Downtime Deployment (ZDD) évite les temps d'arrêt pour les clients. Il doit être appliqué tout au long du processus, du test à la production en passant par le staging. Le Blue-Green Deployment est une technique ZDD populaire où les nouveaux bits sont déployés sur un petit échantillon représentatif de la population (appelé « green »), tandis que la majorité des utilisateurs ne sont pas au courant du « blue » qui contient les anciens bits. Le moment venu, tout le monde repasse au « blue », et très peu de clients, voire aucun, sont affectés. Si tout à l'air correct sur « green », faites lentement migrer tout le monde de « blue » vers « green ».
Je constate cependant que certaines organisations abusent des portes manuelles. Elles exigent que les équipes obtiennent une approbation manuelle lors d'une réunion du comité d'approbation des changements (CAB). La raison est, le plus souvent, une mauvaise interprétation de la séparation des tâches ou de la séparation des problèmes, et un service qui passe la main à un autre pour obtenir l'approbation d'aller de l'avant. J'ai également vu certains approbateurs du CAB faire preuve d'une compréhension technique superficielle des changements en production, ce qui rend le processus d'approbation manuel lent et fastidieux.
C'est une bonne transition pour comprendre la différence entre la livraison continue et le déploiement continu. La livraison continue autorise les validations manuelles, contrairement au déploiement continu. Bien que les deux soient appelés CD, le déploiement continu nécessite plus de discipline et de rigueur puisqu'il n'y a pas d'intervention humaine dans le pipeline.
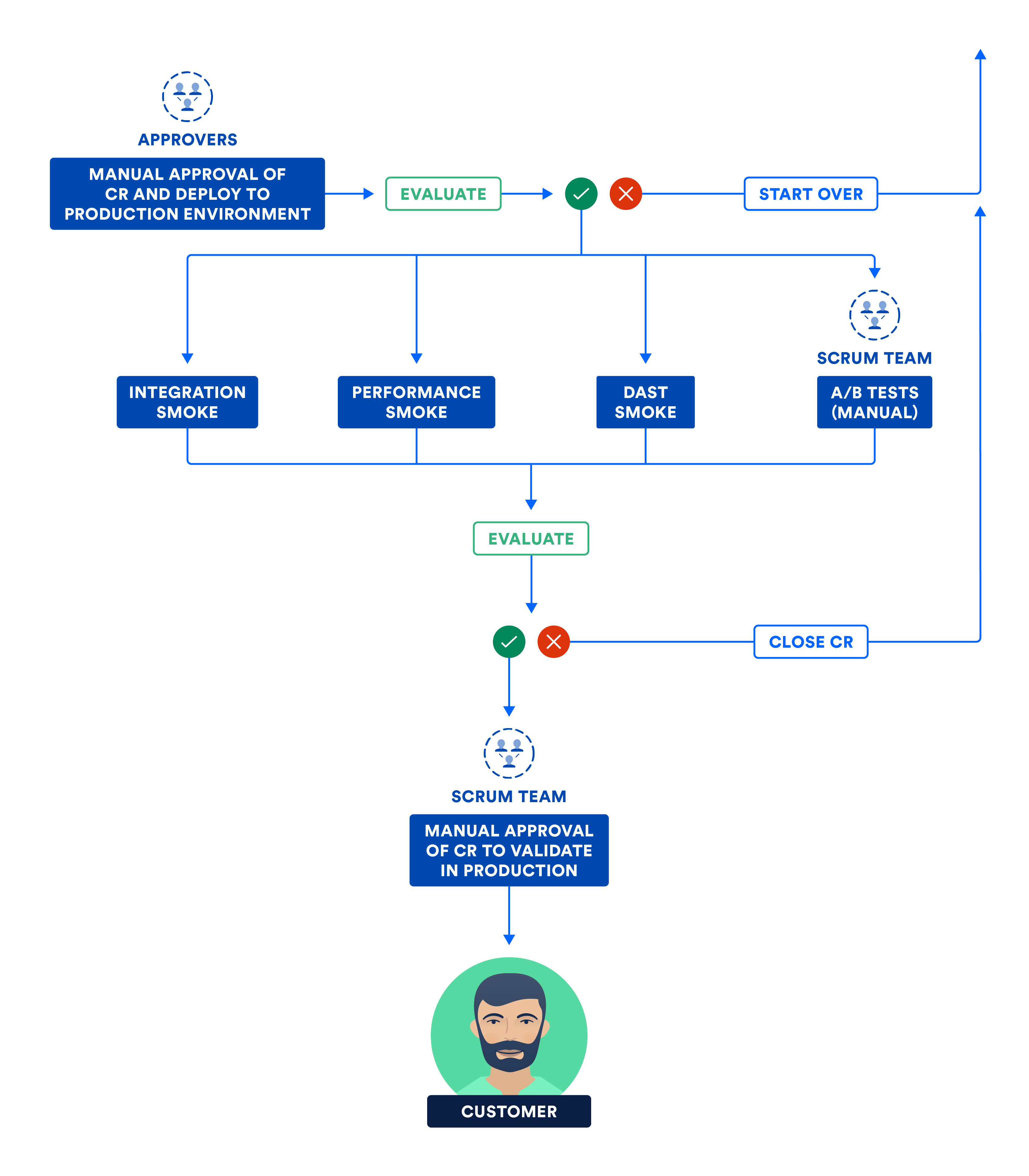
Il y a une différence entre déplacer les bits et les activer. Lors de la production, exécutez des smoke tests, qui sont un sous-ensemble des suites de tests d'intégration, de performance et de sécurité. Lorsque les résultats des smoke tests sont satisfaisants, le produit est mis à la disposition de nos clients !
Le diagramme suivant illustre les étapes réalisées par l'équipe dans cette phase finale de livraison continue.
C) Certification des sous-systèmes et/ou du système dans l'environnement de production
La livraison continue est la nouvelle norme
Pour réussir une livraison continue ou un déploiement continu, il est essentiel de bien effectuer l'intégration continue ainsi que les tests continus. Avec une base solide, vous gagnerez sur les trois fronts : qualité, fréquence et prévisibilité.
Un pipeline de livraison continue aide à concrétiser vos idées en produits grâce à une série d'expériences durables. Si vous vous rendez compte que votre idée n'est finalement pas si bonne, vous pouvez rapidement la remplacer par une meilleure. En outre, les pipelines réduisent la durée moyenne de résolution (MTTR) des problèmes de production, limitant ainsi les temps d'arrêt pour vos clients. Grâce à la livraison continue, vos équipes sont productives et vos clients satisfaits. Que souhaiter de mieux ?
Découvrez-en plus dans notre tutoriel sur la livraison continue.
Partager cet article
Thème suivant
Lectures recommandées
Ajoutez ces ressources à vos favoris pour en savoir plus sur les types d'équipes DevOps, ou pour les mises à jour continues de DevOps chez Atlassian.

Communauté DevOps

Lire le blog