CI/CD Git: 5 tips voor CI-vriendelijke Git-repo's
Bereid je voor op succes — het begint allemaal met je repository.

Sarah Goff-Dupont
Hoofdschrijver
Git en continue levering zijn net als één van die heerlijke combinaties van "chocolade en karamel" die we af en toe in de softwarewereld tegenkomen — twee geweldige smaken die samen nog lekkerder zijn. Daarom wil ik enkele tips geven om je builds in Bamboo goed te laten samenwerken met je Bitbucket-repository's. Het grootste deel van hun interactie vindt plaats in de build- en testfase van continue levering, dus je zult zien dat ik het vooral heb over de "CI", in plaats van de "CD".
1: Bewaar grote bestanden buiten je repo
Een van de dingen die je vaak over Git hoort, is dat je geen grote bestanden in je repository moet zetten: binaire bestanden, mediabestanden, gearchiveerde artefacten, enz. Dit komt omdat als je eenmaal een bestand hebt toegevoegd, het altijd aanwezig is in de geschiedenis van de repo, wat betekent dat elke keer dat de repo wordt gekloond, dat enorme zware bestand mee wordt gekloond.
Een bestand uit de geschiedenis van de repo halen is lastig – het is het equivalent van een frontale lobotomie uitvoeren op je codebase. En deze chirurgische extractie van dossiers verandert de hele geschiedenis van de repo, zodat je niet langer een duidelijk beeld hebt van welke wijzigingen zijn aangebracht en wanneer. Allemaal goede redenen om grote bestanden over het algemeen te vermijden. En...
Grote bestanden buiten je Git-repository's houden is extra belangrijk voor CI
Bij iedere build moet je CI-server je repo klonen naar de werkmap van de build. En als je repo vol zit met allerlei enorme artefacten, dan vertraagt dat proces en duurt het langer voor je ontwikkelaars om te wachten op de resultaten van de build.
Oké, prima. Maar wat als je build afhankelijk is van binaire bestanden van andere projecten of grote artefacten? Dat is een veel voorkomende situatie, en dat zal waarschijnlijk altijd zo blijven. De vraag is dus: hoe kunnen we dit effectief aanpakken?
Oplossing bekijken
Software bouwen en gebruiken met Open DevOps
Gerelateerd materiaal
Lees meer over trunk-gebaseerde ontwikkeling
Een extern opslagsysteem zoals Artifactory (dat een add-on maakt voor Bamboo), Nexus of Archiva kan helpen bij artefacten die worden gegenereerd door je team of de teams om je heen. De bestanden die je nodig hebt, kunnen aan het begin van je build naar de build-directory worden gehaald, net als de bibliotheken van derden via Maven of Gradle.
Pro tip: Als de artefacten regelmatig veranderen, vermijd dan de verleiding om elke avond je grote bestanden te synchroniseren met de build-server, zodat je ze alleen tijdens het schrijven van de build over de schijf hoeft te verplaatsen. Tussen je nachtelijke synchronisaties door bouw je uiteindelijk met oude versies van de artefacten. Bovendien hebben ontwikkelaars deze bestanden sowieso nodig voor builds op hun lokale werkstations. Dus over het algemeen is het het handigste om het downloaden van artefacten gewoon onderdeel van de build te maken.
Als je nog geen extern opslagsysteem op je netwerk hebt, is het het gemakkelijkst om te profiteren van Git Large File Support (LFS).
Git LFS is een extensie die pointers bewaart naar grote bestanden in je repository, in plaats van de bestanden zelf daar op te slaan. De bestanden zelf worden opgeslagen op een externe server. Zoals je je kunt voorstellen, verkort dit de tijd om te klonen aanzienlijk.
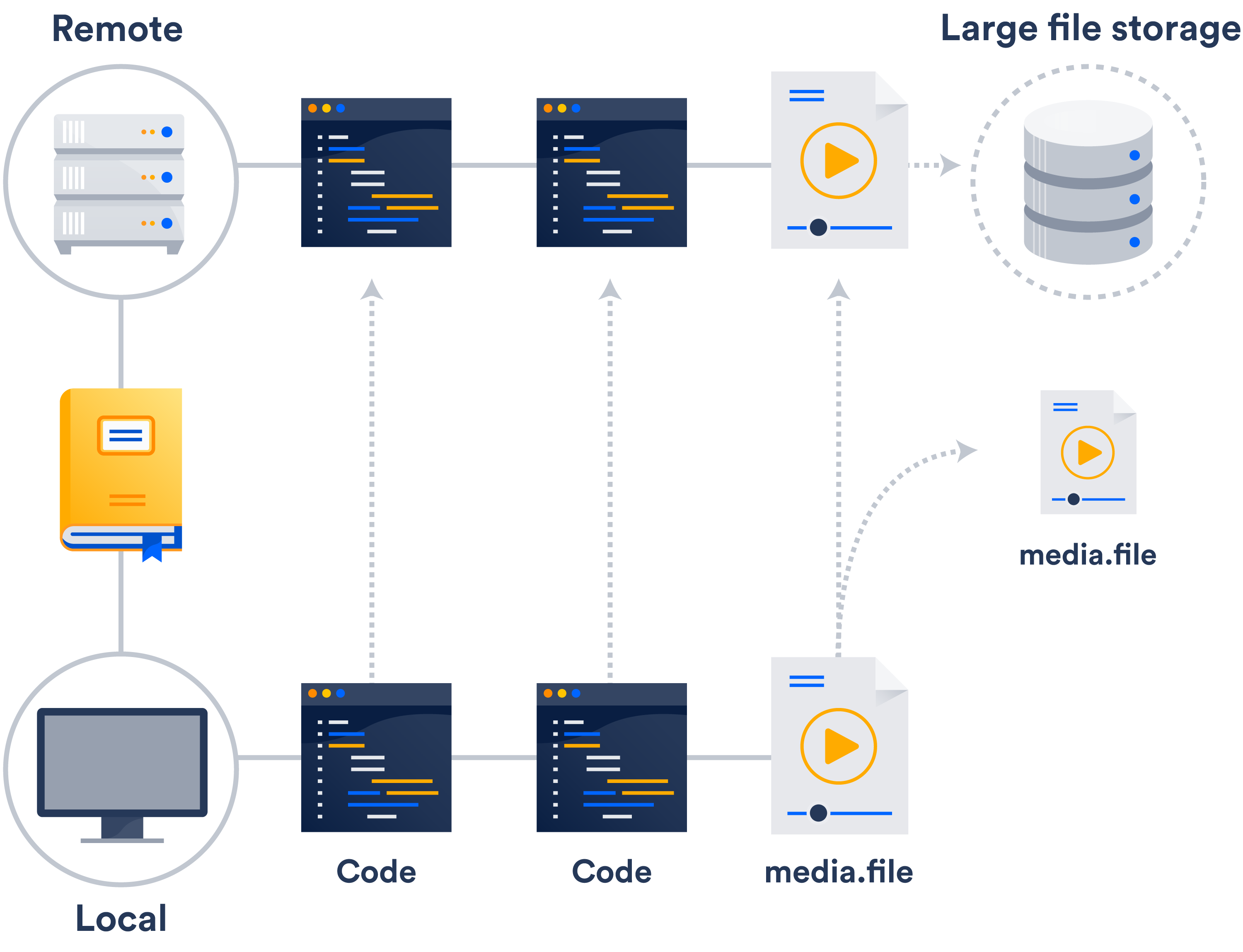
De kans is groot dat je al toegang hebt tot Git LFS – zowel Bitbucket als Github ondersteunen dit.
2: Gebruik oppervlakkige klonen voor CI
Elke keer dat er een build wordt uitgevoerd, kloont je build-server je repo naar de huidige werkmap. Zoals ik al eerder zei, als Git een repo kloont, wordt standaard de volledige geschiedenis van de repo meegekloond. Dus na verloop van tijd zal deze operatie uiteraard steeds langer duren.
Bij oppervlakkige klonen wordt alleen de huidige momentopname van je repo opgehaald. Dit kan dus heel handig zijn om de tijd tussen builds te verkorten, vooral als je met grote en/of oudere repository's werkt.
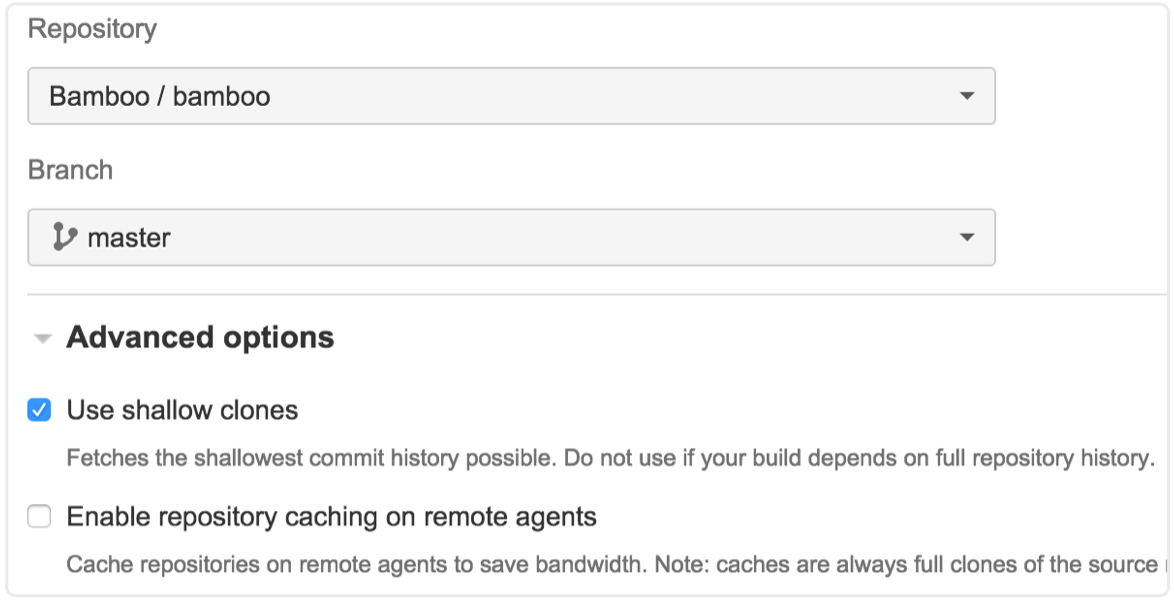
Maar stel dat je voor je build de volledige repogeschiedenis nodig hebt, bijvoorbeeld als in een van de stappen in je build het versienummer in je POM (of iets dergelijks) wordt bijgewerkt, of als je bij elke build twee branches samenvoegt. In beide gevallen is Bamboo nodig om wijzigingen te terug te pushen naar je repo.
Met Git kunnen eenvoudige wijzigingen in bestanden (zoals het updaten van een versienummer) worden doorgevoerd zonder dat de volledige geschiedenis aanwezig is. Maar voor mergen is nog steeds de geschiedenis van de repo nodig, want Git moet terugkijken en de gemeenschappelijke voorouder van de twee branches vinden – dat zal een probleem vormen als je build gebruikmaakt van oppervlakkig klonen. Dit brengt me op tip #3.
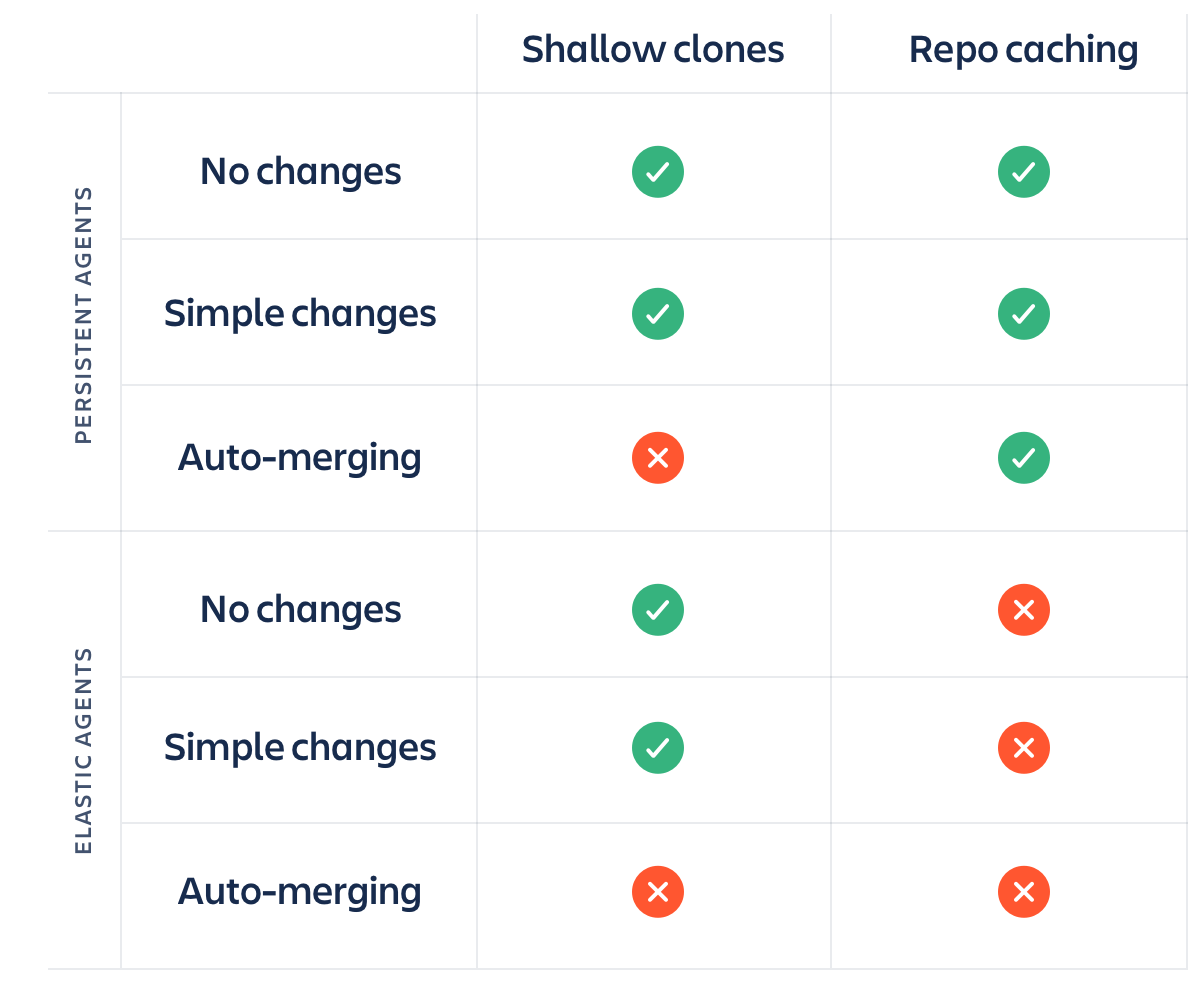
3: De repo van buildagents in de cache opslaan
Dit maakt het klonen ook veel sneller, en Bamboo doet dit zelfs standaard.
Houd er rekening mee dat repocaching je alleen ten goede komt als je agents gebruikt die van build tot build blijven bestaan. Als je buildagents aanmaakt en afbreekt elke keer dat een build draait op EC2 of een andere cloudprovider, maakt repocaching niet uit, omdat je dan met een lege build-map werkt en hoe dan ook elke keer een volledige kopie van de repo moet pullen.
Ondiepe klonen, plus repocaching, gedeeld door persistente versus elastische agents, komt uit op een interessant web van factoren. Hier is een kleine matrix om je te helpen bij het bepalen van je strategie.
4: Kies je triggers verstandig
Het spreekt (bijna) voor zich dat het een goed idee is om CI in al je actieve branches te gebruiken. Maar is het een goed idee om alle builds op alle branches met alle commits uit te voeren? Waarschijnlijk niet. Hier lees je waarom.
Neem bijvoorbeeld Atlassian. We hebben meer dan 800 ontwikkelaars, die elk meerdere keren per dag wijzigingen naar de repo pushen — meestal pushen ze naar hun eigen functie-branches. Dat zijn behoorlijk wat builds. En tenzij je je buildagents onmiddellijk en oneindig schaalt, betekent dat veel wachten in de rij.
Een van onze interne Bamboo-servers biedt plaats aan 935 verschillende build-plannen. We hebben 141 buildagents op deze server aangesloten en aanbevolen werkwijzen gebruikt, zoals het doorsturen van artefacten en parallellisatie van tests om elke build zo efficiënt mogelijk te maken. Toch werd het systeem door iedere push vertraagd.
In plaats van simpelweg nog een Bamboo-instantie op te zetten met nog eens 100 agents, deden we een stap terug en vroegen we ons af of dit echt nodig was. En het antwoord was nee.
Daarom gaven we de ontwikkelaars de optie om te kiezen of ze de build van hun branch wilden activeren, in plaats van deze altijd automatisch te activeren. Het is een goede manier om rigoureus testen af te stemmen op de beschikbare hulpbronnen, in branches vinden de meeste veranderingen plaats, dus daar zijn de mogelijkheden om te besparen.
Veel ontwikkelaars houden van de extra controle die deze keuzevrijheid biedt en binden dat dit op natuurlijke wijze in hun workflow past. Anderen denken liever niet na over wanneer ze een build moeten uitvoeren en houden het bij automatische triggers. Beide werkwijzen kunnen werken. Het belangrijkste is om je branches überhaupt te testen en ervoor te zorgen dat je een schone build hebt voordat je deze samenvoegt.

Kritieke branches, zoals de hoofd-branch en de branches van stabiele releases, zijn echter een ander verhaal. Deze builds worden automatisch geactiveerd, ofwel door in de repo te vragen naar wijzigingen, ofwel door een pushmelding van Bitbucket naar Bamboo te sturen. Aangezien we ontwikkelaars-branches gebruiken voor al ons werk in uitvoering, zouden (in theorie) de enige commits naar de hoofdversie moeten bestaan uit ontwikkelaars-branches die worden samengevoegd. Daarnaast zijn dit de coderegels die we releasen en waar we onze ontwikkelaars-branches van maken. Het is dus echt belangrijk dat we voor elke samenvoeging tijdig testresultaten krijgen.
5: Zeg nee tegen polls, zeg ja tegen hooks
Iedere paar minuten een poll uitvoeren in je repo om op zoek te gaan naar wijzigingen is een vrij goedkope operatie voor Bamboo. Maar als je opschaalt naar honderden builds tegen duizenden branches met tientallen repo's, loopt het snel op. In plaats van Bamboo te belasten met al die polls, kun je Bitbucket laten aangeven wanneer er een wijziging is doorgevoerd en moet worden doorgevoerd.
Meestal doe je dit door een hook toe te voegen aan je repository, maar toevallig regelt de integratie tussen Bitbucket en Bamboo alles al achter de schermen. Zodra ze achter de schermen zijn gekoppeld, activeert een repo-gestuurde build Just Work™ automatisch. Geen hooks of speciale configuraties nodig.
Ongeacht de tools hebben repo-gestuurde triggers het voordeel dat ze automatisch verdwijnen de doel-branch inactief wordt. Met andere woorden, je zult nooit de CPU-cycli van je CI-systeem verspillen aan honderden verlaten branches. Ook bespaar je jezelf tijd door branches niet handmatig uit te hoeven zetten. (Het is het benomen waard dat Bamboo eenvoudig kan worden geconfigureerd om branches te negeren na X dagen inactiviteit, als je nog steeds de voorkeur geeft aan polls.)
De sleutel tot het gebruik van Git met CI is ...
... gewoon attent te zijn. Al die dingen die goed werkten toen je CI gebruikte met een gecentraliseerd VCS? Sommigen zullen minder goed werken met Git. Dus controleer je veronderstellingen — dat is de eerste stap. Voor klanten van Atlassian is de tweede stap de integratie van Bamboo met Bitbucket. Bekijk onze documentatie voor meer informatie en veel plezier met bouwen!
Deel dit artikel
Volgend onderwerp
Aanbevolen artikelen
Bookmark deze resources voor meer informatie over soorten DevOps-teams of voor voortdurende updates over DevOps bij Atlassian.

DevOps-community

Blog lezen