CI/CD und Git: 5 Tipps für CI-freundliche Git-Repositorys
Gehe auf Erfolgskurs – der erste Schritt ist dein Repository.

Sarah Goff-Dupont
Principal Writer
Git und Continuous Delivery sind eine der seltenen Softwarekombinationen, bei denen zwei für sich schon hervorragende Komponenten zusammen eine ideale Lösung ergeben. Daher möchte ich dir in diesem Artikel Tipps dazu geben, wie du erreichen kannst, dass deine Builds in Bamboo optimal mit deinen Bitbucket-Repositorys ineinandergreifen. Da der überwiegende Teil der Interaktion zwischen den zwei Lösungen in der Build- und Testphase von Continuous Delivery erfolgt, schreibe ich hier eher über CI als über CD.
1: Speichere große Dateien nicht im Repository
Oft wird im Zusammenhang mit Git empfohlen, große Dateien wie Binär- und Mediendateien oder archivierte Artefakte nicht im Repository zu speichern. Der Grund dafür ist, dass eine einmal hinzugefügte Datei dauerhaft im Verlauf des Repositorys verbleibt. Bei jedem Klonen des Repositorys wird also die große Datei mitgeklont.
Eine Datei aus dem Verlauf des Repositorys zu entfernen ist extrem heikel und entspricht einer Lobotomie an deiner Codebasis. Dieser chirurgische Eingriff zur Extraktion einer Datei verändert den gesamten Verlauf des Repositorys, sodass du nicht mehr klar erkennen kannst, wann welche Änderungen vorgenommen wurden. Es gibt also gute Gründe, im Allgemeinen große Dateien zu meiden.
Besonders für CI ist es wichtig, große Dateien nicht in Git-Repositorys aufzunehmen
Jedes Mal, wenn ein Build läuft, muss dein CI-Server dein Repo in das Build-Arbeitsverzeichnis klonen. Bei einem aufgeblähten Repository mit einigen Riesenartefakten verlangsamt sich dieser Prozess und es entstehen für deine Entwickler längere Wartezeiten auf die Build-Ergebnisse.
So weit, so gut. Was aber, wenn deine Builds von Binärdateien anderer Projekte oder großer Artefakte abhängig sind? Dies kommt sehr häufig vor und daran wird sich wohl auch so schnell nichts ändern. Wie gehen wir also effizient damit um?
Lösung anzeigen
Hochwertige Software entwickeln und ausführen mit Open DevOps
Zugehöriges Material
Weitere Informationen über Trunk-basierte Entwicklung
Ein externes Storage-System wie Artifactory (das über ein Add-on für Bamboo verfügt), Nexus oder Archiva kann für Artefakte, die von deinem Team oder den Teams um dich herum generiert wurden, hilfreich sein. Die benötigten Dateien können zu Beginn deines Builds in das Build-Verzeichnis gepullt werden – genauso wie die Bibliotheken von Drittanbietern, die du über Maven oder Gradle pullst.
Profitipp: Wenn sich die Artefakte häufig ändern, bist du vielleicht versucht, deine großen Dateien jeweils nur abends mit dem Build-Server zu synchronisieren, damit du sie nur beim Build übertragen musst. Dies ist nicht empfehlenswert. Zwischen diesen abendlichen Synchronisationen arbeitest du dann nämlich mit statischen Versionen der Artefakte. Außerdem benötigen die Entwickler diese Dateien für Builds ohnehin auf ihren lokalen Rechnern. Die sauberste Lösung ist also, den Artefakt-Download zum Bestandteil deines Builds zu machen.
Wenn in deinem Netzwerk noch kein externes Storage-System vorhanden ist, bietet sich Git Large File Storage (LFS) als unkomplizierteste Lösung an.
Git LSF ist eine Erweiterung, die Verweise auf große Dateien statt der Dateien an sich im Repository speichert. Die Dateien selbst werden auf einem Remote-Server gespeichert. Wie du dir vorstellen kannst, reduziert dies die zum Klonen benötigte Zeit erheblich.
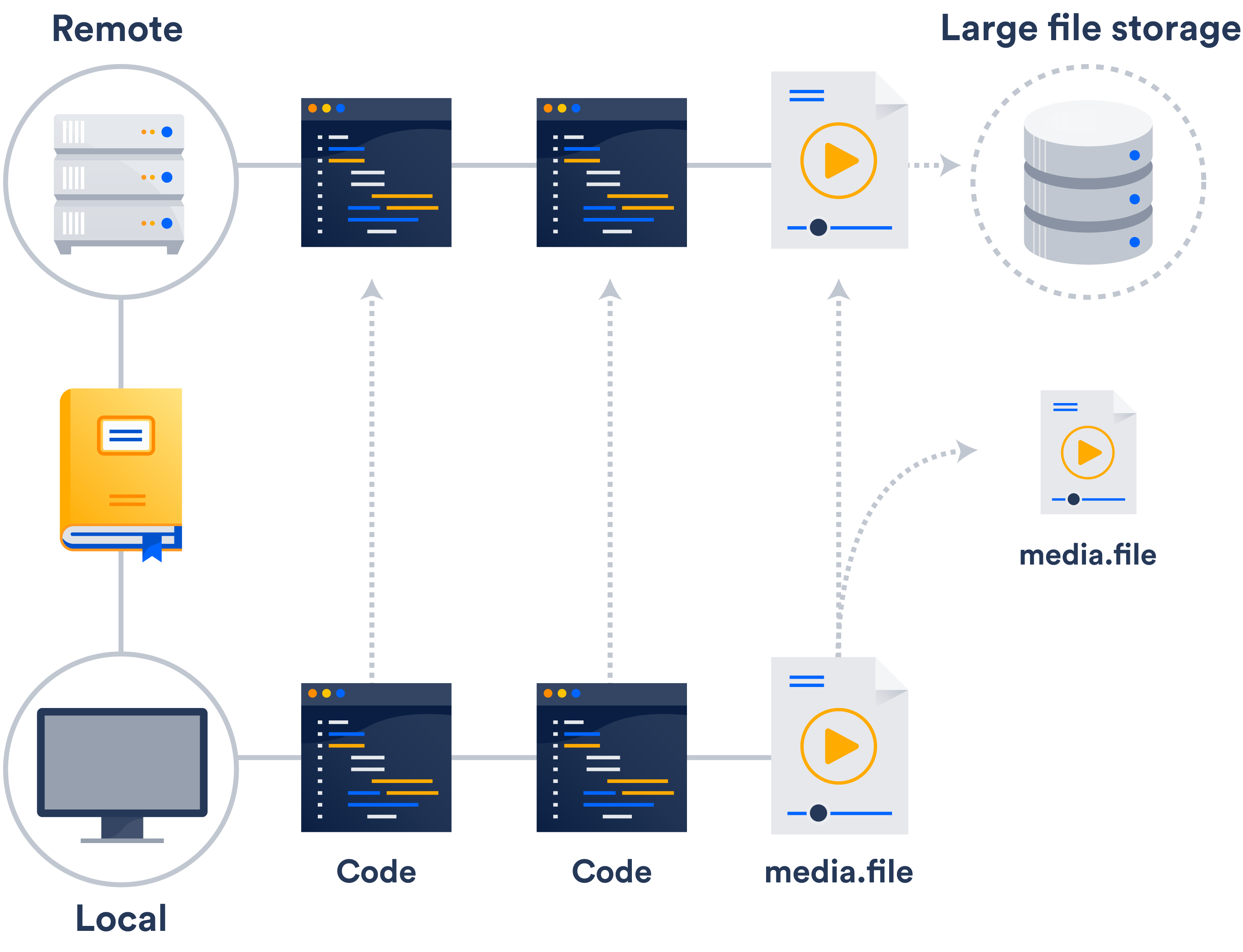
Wahrscheinlich hast du bereits Zugriff auf Git LFS, da es von Bitbucket und GitHub unterstützt wird.
2: Verwende für CI oberflächliche Klone
Jedes Mal, wenn ein Build ausgeführt wird, klont dein Build-Server dein Repo in das aktuelle Arbeitsverzeichnis. Wie ich bereits erwähnt habe, klont Git standardmäßig den gesamten Repository-Verlauf. Mit der Zeit dauert dies natürlich immer länger.
Mit oberflächlichen Klonen wird nur der aktuelle Snapshot deines Repos heruntergepullt. Dies kann sehr hilfreich zur Verkürzung von Build-Zeiten sein, insbesondere bei großen und/oder älteren Repositorys.
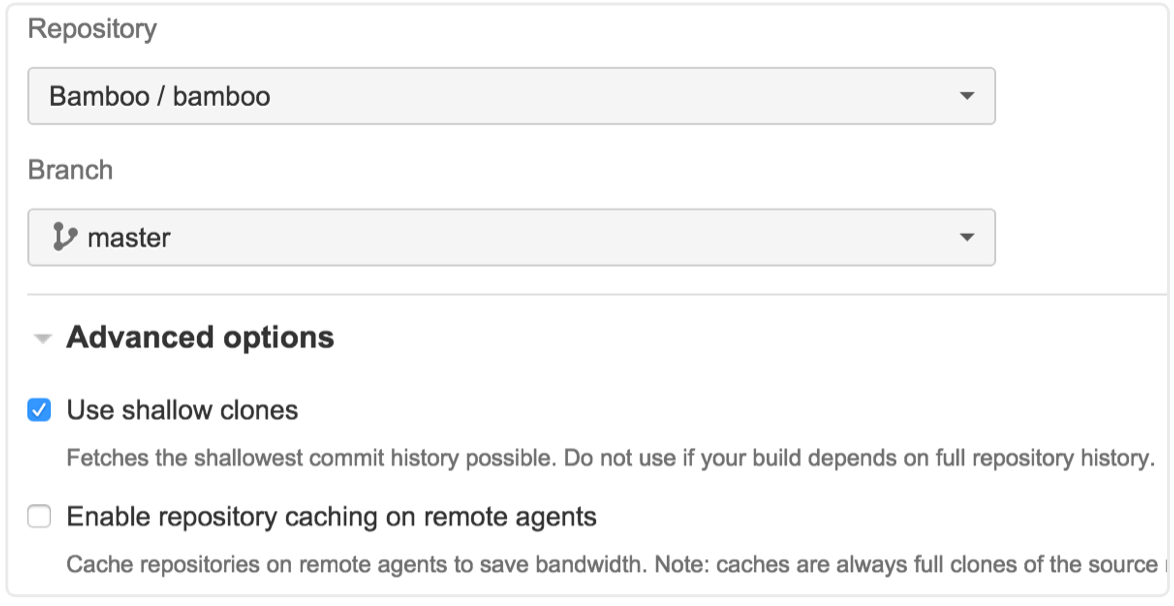
Angenommen, für deinen Build wird tatsächlich der vollständige Repository-Verlauf benötigt – beispielsweise, weil mit einem der Schritte in deinem Build die Versionsnummer im POM (o. ä.) aktualisiert wird oder weil du mit jedem Build zwei Branches mergst. In beiden Fällen muss Bamboo Änderungen an dein Repository zurück übermitteln.
Mit Git können einfache Änderungen an Dateien (zum Beispiel die Aktualisierung einer Versionsnummer) ohne den gesamten Verlauf gepusht werden. Für einen Merge ist jedoch weiterhin der komplette Verlauf des Repositorys erforderlich, da Git zurückblicken muss, um den gemeinsamen Vorfahren der beiden Branches zu finden – dies wird zum Problem, wenn dein Build oberflächliche Klone nutzt. Und hiermit kommen wir zu Tipp Nr. 3.
3: Cache das Repo in Build-Agenten
Dadurch wird auch der Klonvorgang erheblich beschleunigt, weshalb dies bei Bamboo Standard ist.
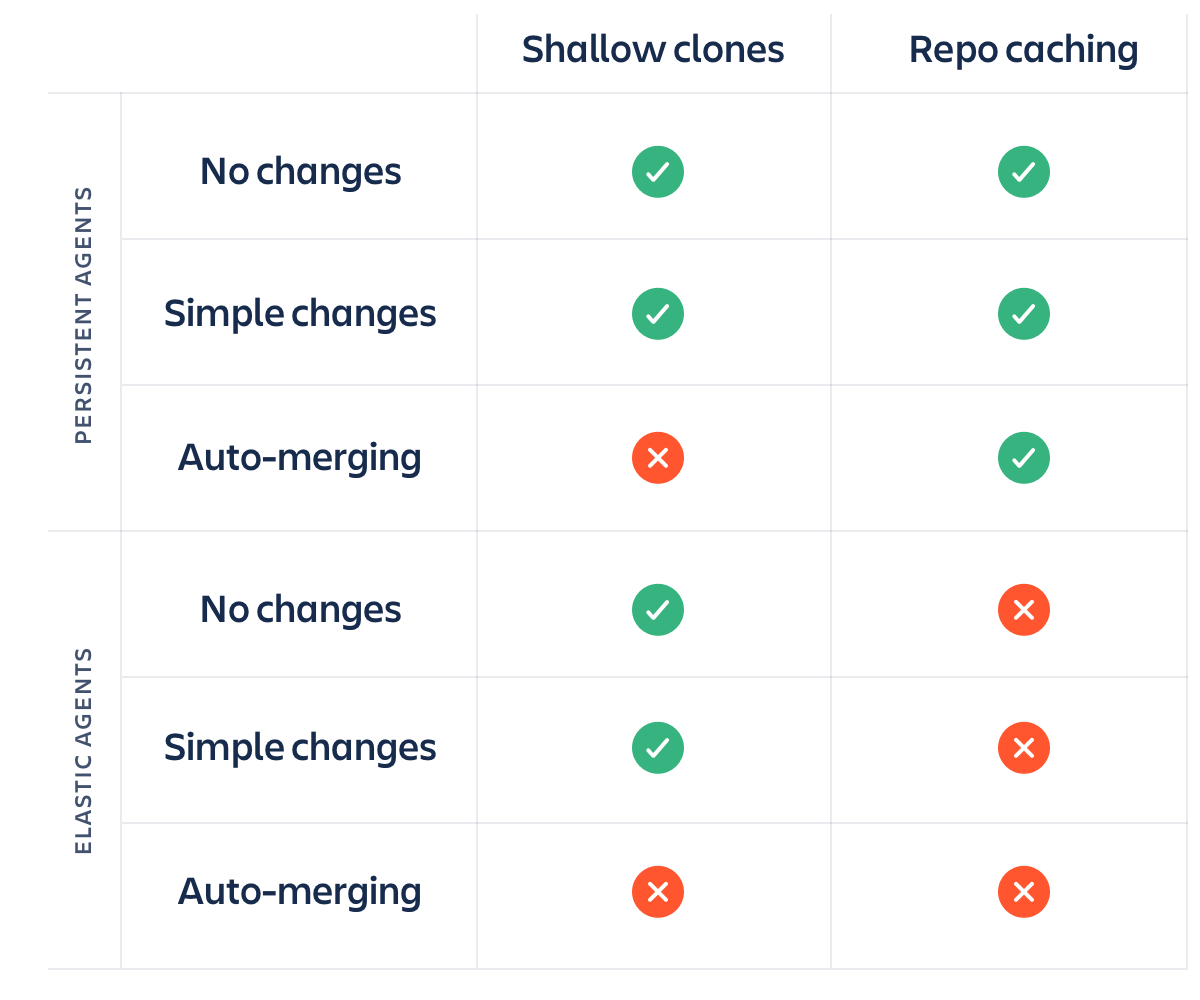
Ein Hinweis: Repository-Caching ist nur von Vorteil, wenn deine Agenten von Build zu Build erhalten bleiben. Wenn du Agenten auf EC2 oder bei einem anderen Cloud-Anbieter bei jedem Build neu erstellst und später wieder entfernst, hat das Repository-Caching keinen Nutzen, weil du dann mit einem leeren Build-Verzeichnis arbeitest und ohnehin jedes Mal eine vollständige Kopie des Repositorys abrufen musst.
Flache Klone plus Repository-Caching, geteilt durch bleibende Agenten gegenüber elastischen Agenten ergibt ein spannendes Netz aus Faktoren. Hier eine kleine Matrix, die dir beim Entwickeln einer Strategie hilft.
4: Wähle deine Trigger mit Bedacht
Es ist (nahezu) selbstredend, dass die Ausführung von CI in allen aktiven Branches eine gute Idee ist. Aber ist es sinnvoll, bei jedem Commit die Builds für alle Branches laufen zu lassen? Eher nicht. Und zwar aus folgendem Grund.
Nehmen wir zum Beispiel Atlassian. Bei uns arbeiten über 800 Entwickler, die alle mehrmals täglich ihre Änderungen in das Repository pushen – meistens in ihre Feature-Branches. Das sind eine Menge Builds. Wenn die Zahl an Build-Agenten nicht umgehend ins Unermessliche erhöht wird, sind lange Wartezeiten vorprogrammiert.
Einer unserer internen Bamboo-Server beherbergt 935 verschiedene Build-Pläne. Wir hatten 141 Build-Agenten an diesen Server angeschlossen und nutzten Best Practices wie das Weiterleiten von Artefakten und Paralleltests, um jeden Build so effizient wie möglich zu gestalten. Trotzdem führten die Builds nach jedem Push zu Engpässen.
Anstatt einfach eine weitere Bamboo-Instanz mit mindestens 100 zusätzlichen Agenten einzurichten, sind wir in uns gegangen und haben uns gefragt, ob dies wirklich nötig ist. Die Antwort darauf lautete schließlich: Nein, ist es nicht.
Also haben wir Entwicklern die Möglichkeit gegeben, ihre Branch-Builds selbst zu kontrollieren, statt sie immer automatisch triggern zu lassen. Dies ist ein guter Weg, um ein ausgewogenes Verhältnis zwischen strikten Tests und Ressourcenschonung zu erzielen. Da die meisten Änderungsaktivitäten in Branches stattfinden, ist das Einsparpotenzial dort am größten.
Viele Entwickler wissen die stärkere Kontrolle bei nicht-automatischen Builds zu schätzen und finden, dass sich diese Builds gut in ihren Workflow einfügen. Andere Entwickler möchten lieber nicht selbst über den optimalen Zeitpunkt zum Erstellen eines Builds entscheiden und behalten die automatischen Trigger bei. Beide Ansätze können funktionieren. Wichtig ist nur, die Branches zunächst zu testen und so sicherzustellen, dass dein Build sauber ist, bevor du ihn upstream mergst.

Wichtige Branches wie der Haupt-Branch und stabile Release-Branches sind allerdings ein ganz anderes Thema. Dort werden Builds automatisch ausgelöst – entweder durch das Abrufen von Änderungen aus dem Repository oder durch das Senden einer Push-Benachrichtigung von Bitbucket an Bamboo. Da wir Entwicklungs-Branches für alle laufenden Arbeiten nutzen, sollten (theoretisch) auch nur Entwicklungs-Branches und keine anderen Commits in den Haupt-Branch gemergt werden. Dies sind außerdem die Codezeilen, auf denen unsere Releases und Entwicklungs-Branches basieren. Es ist daher sehr wichtig, frühzeitig Testergebnisse zu jedem Merge zu erhalten.
5: Vergiss Abfragen, Hooks sind angesagt
Für Bamboo ist es kein Problem, das Repository alle paar Minuten auf Änderungen abzufragen. Wenn jedoch mehrere Hundert Builds und mehrere Tausend Branches mit Dutzenden Repositorys vorhanden sind, summieren sich die Prozesse schnell. Statt Bamboo mit all diesen Abfragen zu belasten, kannst du Bitbucket so einrichten, dass signalisiert wird, wenn eine Änderung gepusht wurde und ein Build erforderlich ist.
In der Regel musst du dein Repository dafür mit einem Hook versehen, doch die Integration von Bitbucket und Bamboo nimmt dir praktischerweise die gesamte Einrichtung ab. Sobald Bamboo und Bitbucket Server am Back-End verbunden sind, lassen sich Repository-orientierte Builds ohne weiteres Eingreifen auslösen. Es sind keine Hooks oder spezielle Konfigurationen erforderlich.
Unabhängig von den Tools haben Repository-orientierte Trigger den Vorteil, dass sie automatisch wieder verschwinden, sobald der Ziel-Branch nicht mehr aktiv ist. Anders gesagt wirst du so nie die CPU-Zyklen deines CI-Systems mit der Abfrage Hunderter stillgelegter Branches vergeuden. Oder deine eigene Zeit beim manuellen Stilllegen von Branch-Builds. (Es sei jedoch angemerkt, dass in Bamboo das Ignorieren von Branches nach einer bestimmten Anzahl von Tagen problemlos konfiguriert werden kann, falls du weiterhin Abfragen bevorzugst.)
Der Schlüssel zur Verwendung von Git mit CI
Du musst viele Aspekte berücksichtigen. Nicht alles, was bei CI mit einem zentralisierten VCS reibungslos funktioniert, lässt sich einfach auf Git übertragen. Im ersten Schritt solltest du deine Annahmen überprüfen. Atlassian-Kunden können im zweiten Schritt Bamboo mit Bitbucket integrieren. Nähere Informationen findest du in unserer Dokumentation. Viel Erfolg!
Diesen Artikel teilen
Nächstes Thema
Lesenswert
Füge diese Ressourcen deinen Lesezeichen hinzu, um mehr über DevOps-Teams und fortlaufende Updates zu DevOps bei Atlassian zu erfahren.

DevOps-Community

Blog lesen