Grundlagen einer Continuous Delivery-Pipeline
Erfahre, wie automatisierte Builds, Tests und Deployments zu einem einzigen Release-Workflow verbunden werden.

Juni Mukherjee
Developer Advocate
Was ist eine Continuous Delivery-Pipeline?
Eine Continuous-Delivery-Pipeline ist eine Reihe von automatisierten Schritten zur Auslieferung neuer Software. Es handelt sich um eine Implementierung des Continuous-Paradigmas, bei der automatisierte Builds, Tests und Deployments in einem einzigen Release-Workflow orchestriert werden. Kurz gesagt: Eine CD-Pipeline ist eine Reihe von Schritten, die deine Codeänderungen auf dem Weg zur Produktion durchlaufen.
Eine CD-Pipeline liefert gemäß den Geschäftsanforderungen regelmäßig, vorhersagbar und automatisch Qualitätsprodukte von der Test- zur Staging- und schließlich zur Produktionsumgebung.
Beschränken wir uns für den Anfang auf drei wichtige Begriffe: Qualität, Häufigkeit und Vorhersagbarkeit.
We emphasize quality to underscore that it’s not traded for speed. Business doesn’t want us to build a pipeline that can shoot faulty code to production at high speed. We will go through the principles of “Shift Left” and “DevSecOps”, and discuss how we can move quality and security upstream in the software development life cycle (SDLC). This will put to rest any concerns regarding continuous delivery pipelines posing risks to businesses.
Die Häufigkeit beschreibt, dass Pipelines jederzeit für Feature-Releases ausgeführt werden können, da sie so programmiert sind, dass sie mit Commits an die Codebasis ausgelöst werden. Sobald das MVP (Minimum Viable Product) der Pipeline vorhanden ist, kann diese so oft wie nötig ausgeführt werden. Dafür fallen regelmäßige Wartungskosten an. Dieser automatisierte Ansatz ermöglicht eine Skalierung, ohne das Team zu belasten. So können Teams zudem schrittweise kleinere Verbesserungen vornehmen, ohne Angst haben zu müssen, eine Katastrophe in der Produktion zu verursachen.
Lösung anzeigen
Hochwertige Software entwickeln und ausführen mit Open DevOps
Zugehöriges Material
Was ist die DevOps-Pipeline?
Oft hören wir den Satz "Irren ist menschlich" – aus gutem Grund. Manuelle Releases sorgen oft für Stress im Team, da sie mit fehleranfälligen Prozessen verbunden sind. Vorhersehbarkeit hingegen bedeutet, dass Releases planbar werden, wenn sie über eine Continuous-Delivery-Pipeline durchgeführt werden. Da es sich bei Pipelines um programmierbare Infrastruktur handelt, können sich Teams jedes Mal auf dasselbe gewünschte Verhalten einstellen. Wobei es natürlich Ausnahmen gibt, da keine Software fehlerfrei ist. Insgesamt sind Pipelines jedoch deutlich besser als manuelle, fehleranfällige Release-Prozesse, da Pipelines im Gegensatz zu Menschen nicht durch strikte Fristen unter Stress geraten.
Pipelines verfügen über Software-Gates, an denen automatisch entschieden wird, ob versionierte Artefakte passieren dürfen oder abgelehnt werden. Wird das Release-Protokoll nicht beachtet, bleiben die Software-Gates geschlossen und die Pipeline bricht ab. Es werden Warnungen generiert und Benachrichtigungen an eine Verteilerliste mit Teammitgliedern gesendet, die möglicherweise für den Fehler in der Pipeline verantwortlich sind.
Genauso funktioniert eine CD-Pipeline: Bei jeder erfolgreichen Ausführung der Pipeline geht ein Commit oder ein kleiner, inkrementeller Batch von Commits in Produktion. Später liefern die Teams Features und schließlich Produkte auf sichere, nachvollziehbare Weise aus.
Phasen einer Continuous Delivery-Pipeline
Die Architektur des Produkts, das die Pipeline durchläuft, ist ein wichtiger Faktor, nach dem sich die Anatomie der Continuous Delivery-Pipeline richtet. Bei einer hochgradig gekoppelten Produktarchitektur ergibt sich ein kompliziertes grafisches Pipelinemuster, in dem mehrere Pipelines auf komplexen Wegen schließlich zur Produktion führen.
Außerdem beeinflusst die Produktarchitektur die verschiedenen Phasen der Pipeline und die darin produzierten Artefakte. In der Regel umfasst Continuous Delivery die folgenden 4 Phasen:
Auch wenn dein Unternehmen mehr oder weniger als vier Phasen plant, finden die unten dargelegten Konzepte Anwendung.
Es ist ein weit verbreiteter Irrtum, dass diese Phasen immer physisch in der Pipeline erkennbar sind. Dies muss nicht unbedingt der Fall sein. Es handelt sich um logische Phasen, die Umgebungsmeilensteinen wie Test, Staging und Produktion zugeordnet werden können. So könnten beispielsweise Komponenten und Subsysteme erstellt, getestet und in einer Testumgebung bereitgestellt werden. Subsysteme oder Systeme könnten zusammengestellt, getestet und in einer Staging-Umgebung bereitgestellt werden oder sie könnten im Rahmen der Produktionsphase an die Produktion übermittelt werden.
Die durch Fehler verursachten Kosten sind in der Testphase gering, beim Staging mittelhoch und in der Produktion hoch. "Shift Left" bedeutet, dass Überprüfungen auf einen früheren Punkt der Pipeline verschoben werden. Das Gate zwischen Test und Staging ist heute mit deutlich mehr Abwehrtechniken ausgerüstet, sodass Staging nicht mehr wie ein Tatort aussehen muss.
Früher kam InfoSec am Ende des Softwareentwicklungszyklus zum Zuge, um Releases abzulehnen, die die Cybersicherheit des Unternehmens bedrohen könnten. Trotz der hehren Absichten führte dies zu Problemen und Verzögerungen. Bei "DevSecOps" besteht das Ziel darin, Sicherheitsmaßnahmen schon ab der Designphase in das Produkt zu integrieren, statt erst das (möglicherweise nicht sichere) fertige Produkt zur Evaluierung zu schicken.
Sehen wir uns einmal genauer an, wie "Shift Left" und "DevSecOps" im Continuous Delivery-Workflow berücksichtigt werden können. In den nächsten Abschnitten behandeln wir jede Phase im Detail.
CD-Komponentenphase
Die Pipeline erstellt zunächst die Komponenten – die kleinsten verteilbaren und testbaren Einheiten des Produkts. So kann zum Beispiel eine von der Pipeline erstellte Bibliothek als Komponente bezeichnet werden. Eine Komponente kann unter anderem durch Code-Reviews, Unit-Tests und statische Codeanalysen zertifiziert werden.
Codeüberprüfungen sind für Teams wichtig, um ein gemeinsames Verständnis der Features, Tests und Infrastrukturkomponenten zu entwickeln, die für die Markteinführung des Produkts benötigt werden. Vier Augen sehen mehr als zwei. Im Laufe der Jahre fällt uns fehlerhafter Code vielleicht nicht mehr auf, weil wir nicht mehr glauben, dass es sich um echte Fehler handelt. Ein neuer Blickwinkel kann uns zwingen, diese Schwachstellen noch einmal zu betrachten und sie bei Bedarf zu überarbeiten.
Unit-Tests sind in den meisten Fällen die ersten für den Code durchgeführten Softwaretests. Die Datenbank und das Netzwerk bleiben davon unberührt. Die Codeabdeckung zeigt, welcher prozentuale Anteil des Codes Unit-Tests durchlaufen hat. Sie lässt sich auf verschiedene Arten messen, beispielsweise in Form von Zeilenabdeckung, Klassenabdeckung oder Methodenabdeckung.
Eine hohe Codeabdeckung ist zwar für das Refactoring von Vorteil, festgelegte Ziele für eine hohe Abdeckung sind jedoch kontraproduktiv. Man würde es nicht vermuten, aber manche Teams mit einer hohen Codeabdeckung verzeichnen mehr Produktionsausfälle als Teams mit geringerer Codeabdeckung. Zudem lassen sich die Abdeckungszahlen leicht manipulieren. Unter akutem Druck, besonders bei Leistungsprüfungen, nutzen Entwickler unter Umständen unlautere Methoden zur Steigerung der Codeabdeckung. Näher möchte ich hier nicht darauf eingehen.
Die statische Codeanalyse erkennt Probleme im Code, ohne ihn auszuführen. Sie ist eine kostengünstige Methode für die Problemerkennung. Wie bei Unit-Tests werden die Tests mit dem Quellcode ausgeführt und haben eine niedrige Laufzeit. Bei statischen Analysen werden potenzielle Speicherlecks sowie Codequalitätsindikatoren wie zyklomatische Komplexität und Code-Duplizierung erkannt. In dieser Phase ist SAST (Static Analysis Security Testing) eine bewährte Methode, um Sicherheitsschwachstellen zu erkennen.
Definiere die Metriken, die deine Software-Gates steuern und den Übergang des Codes von der Komponentenphase in die Subsystemphase beeinflussen.
CD-Subsystemphase
Lose miteinander verbundene Komponenten bilden zusammen ein Subsystem, d. h. die kleinste bereitstellbare und ausführbare Einheit. Ein Server ist beispielsweise ein Subsystem. Auch ein in einem Container ausgeführter Mikroservice ist ein Beispiel für ein Subsystem. Im Gegensatz zu Komponenten können Subsysteme im Hinblick auf Use Cases bei Kunden überprüft werden.
Eine Node.js-UI und ein Java-API-Layer sind ebenso Subsysteme wie eine Datenbank. Manche IT-Abteilungen verwalten ein RDBMS (relationales Datenbankmanagementsystem) manuell, obwohl es inzwischen neue Tools gibt, die das Änderungsmanagement für Datenbanken automatisieren und sich für Continuous Delivery bei Datenbanken bewährt haben. CD-Pipelines mit NoSQL-Datenbanken sind einfacher zu implementieren als RDBMS.
Subsysteme können durch Funktions-, Leistungs- und Sicherheitstests bereitgestellt und zertifiziert werden. Schauen wir uns an, wie diese unterschiedlichen Testtypen Produkte prüfen:
Funktionstests betreffen alle Use Cases bei Kunden im Zusammenhang mit Aspekten wie Internationalisierung (I18N), Lokalisierung (L10N), Datenqualität, Zugänglichkeit und Negativszenarien. Mit diesen Tests wird sichergestellt, dass dein Produkt den Kundenanforderungen entspricht, die Inklusion berücksichtigt und für den Zielmarkt geeignet ist.
Lege zusammen mit den Produktinhabern die Benchmarks für die Leistung fest. Integriere die Leistungstests in die Pipeline, wobei die Benchmarks darüber entscheiden, ob die Pipeline fortgesetzt oder abgebrochen wird. Einem verbreiteten Mythos zufolge müssen Leistungstests nicht in die Continuous-Delivery-Pipeline integriert werden. Dies widerspricht jedoch dem Prinzip der Kontinuität.
Verschiedene große Unternehmen sind in letzter Zeit Opfer von Hackerangriffen geworden und die Anzahl der Bedrohungen für die Cybersicherheit ist höher denn je. Wir müssen daher aufrüsten und dafür sorgen, dass unsere Produkte keinerlei Sicherheitsschwachstellen enthalten – sei es in unserem eigenen Code oder in Bibliotheken von Drittanbietern, die wir in unseren Code importieren. Tatsächlich wurden bei OSS (Open-Source-Software) bereits größere Sicherheitsverletzungen entdeckt. Wir müssen daher Tools und Techniken einsetzen, die diese Fehler erkennen und einen Abbruch der Pipeline erzwingen. DAST (Dynamic Analysis Security Testing) ist eine bewährte Methode zur Erkennung von Sicherheitsschwachstellen.
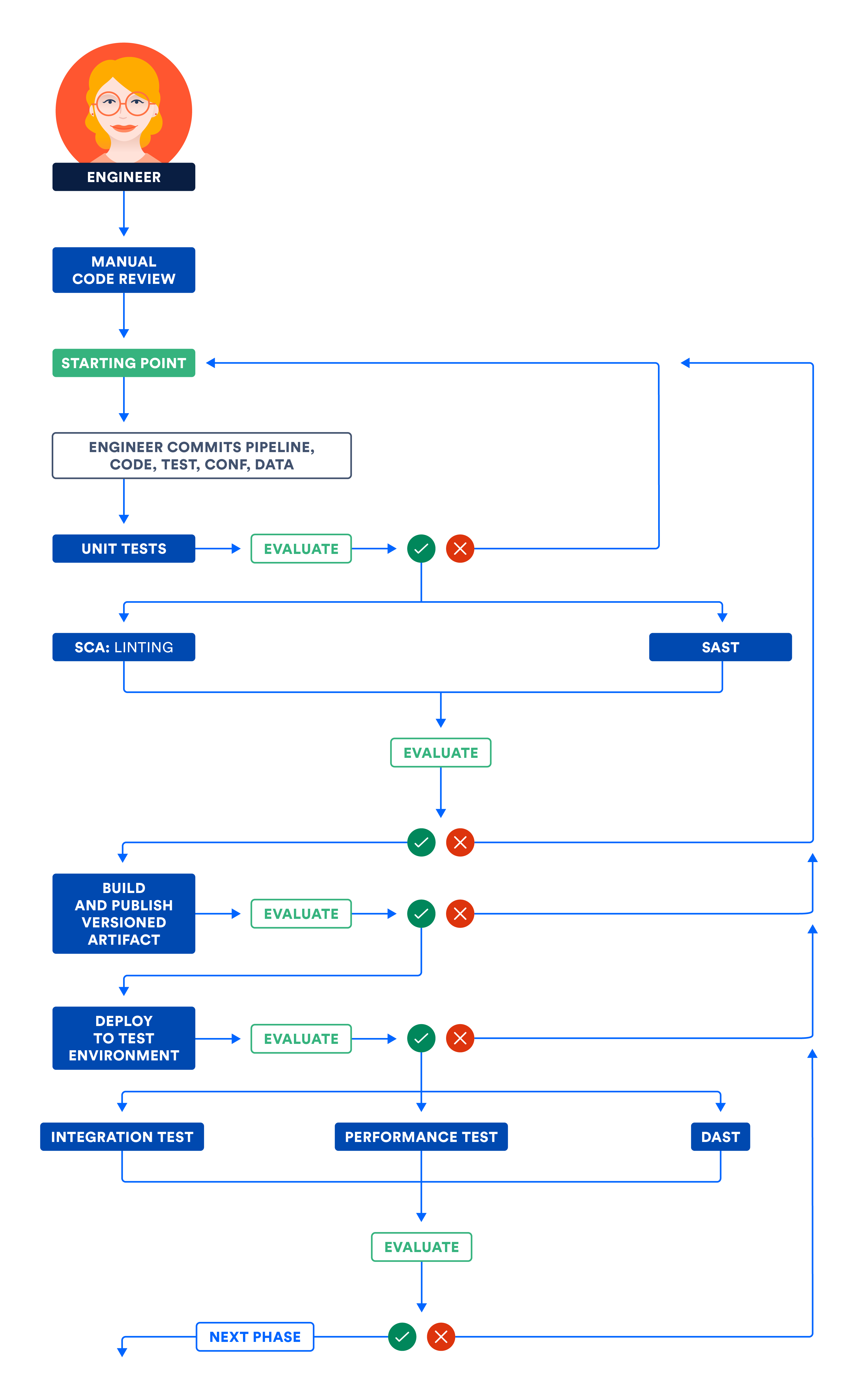
Die Abbildung unten verdeutlicht den im Zusammenhang mit der Komponenten- und Subsystemphase beschriebenen Workflow. Führe die voneinander unabhängigen Schritte parallel aus, um die Ausführungszeit der Pipeline insgesamt zu verkürzen und schneller Feedback zu erhalten.
A) Zertifizierung von Komponenten und/oder Subsystemen in der Testumgebung
CD-Systemphase
Sobald Subsysteme die Funktions-, Leistungs- und Sicherheitserwartungen erfüllen, könnte der Pipeline beigebracht werden, ein System aus lose gekoppelten Subsystemen zusammenzustellen, wenn das gesamte System als Ganzes releast wird. Das bedeutet, dass das schnellste Team mit der Geschwindigkeit des langsamsten Teams arbeiten kann. Oder wie es im Sprichwort heißt: "Eine Kette ist nur so stark wie ihr schwächstes Glied".
Wir raten von diesem Composition-Anti-Pattern ab, bei dem Subsysteme zu einem System zusammengeführt werden, das als Ganzes releast werden soll. Alle Subsysteme sind bei diesem Anti-Pattern untrennbar verbunden. Wenn du in unabhängig voneinander bereitstellbare Artefakte investiert, kannst du dieses Anti-Pattern jedoch vermeiden.
Wenn gesamte Systeme geprüft werden sollen, bietet sich die Zertifizierung mit Integrations-, Leistungs- und Sicherheitstests an. Anders als in der Subsystemphase sollten in dieser Phase keine Mocks oder Stubs verwendet werden. Außerdem solltest du dich hauptsächlich darauf konzentrieren, Schnittstellen und Netzwerke zu testen.
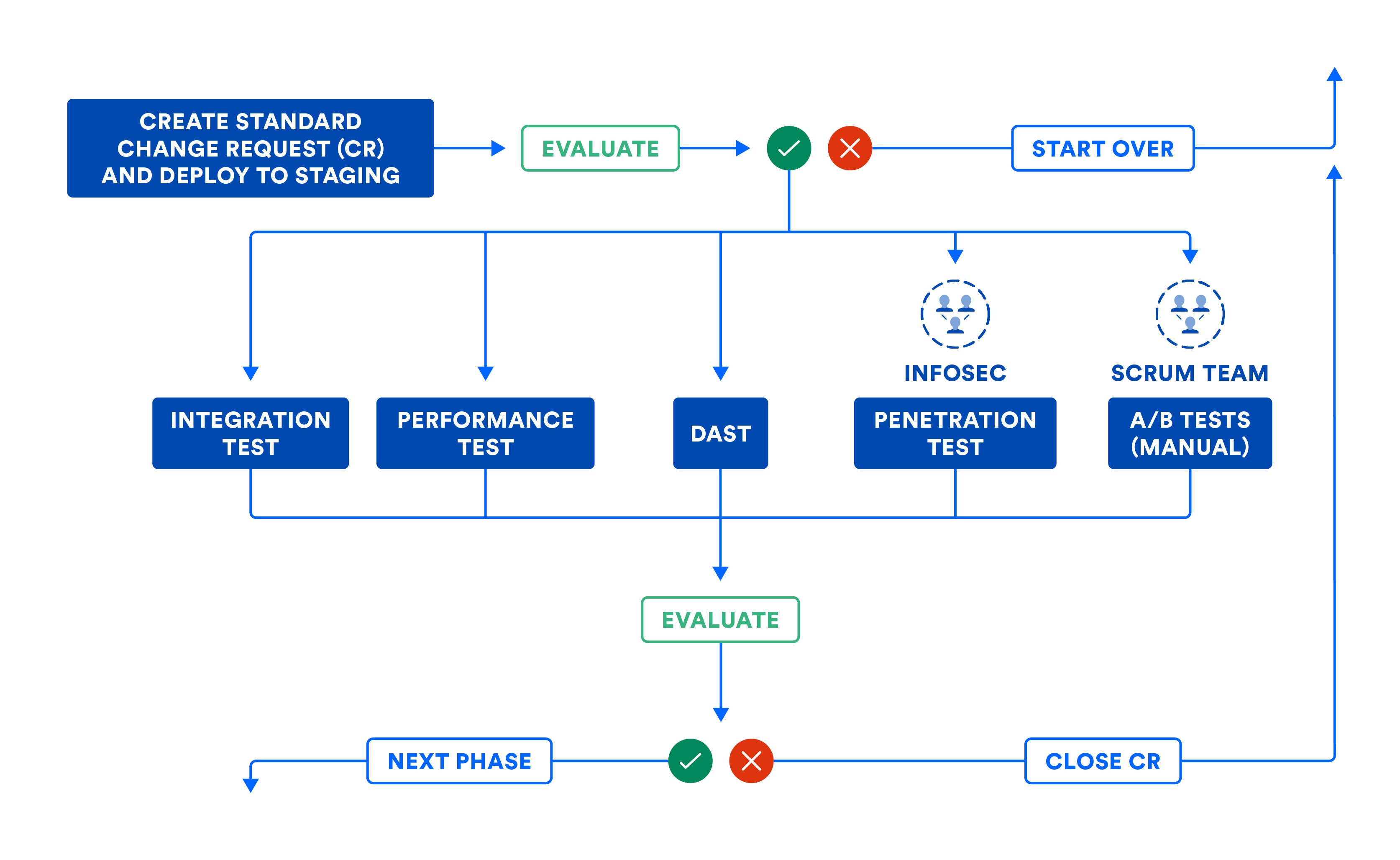
In der Abbildung unten ist der Workflow aus der Systemphase dargestellt, falls du deine Subsysteme per Komposition zusammenfügen musst. Auch wenn du deine Subsysteme direkt in Produktion gehen lassen kannst, hilft dir die Abbildung beim Einrichten von Software-Gates, die für den Übergang des Codes von dieser Phase in die nächste benötigt werden.
Die Pipeline kann automatisch Änderungsanfragen übermitteln, um einen Audit-Trail zu hinterlassen. Die meisten Unternehmen nutzen diesen Workflow für Standardänderungen, also geplante Releases. Dieser Workflow sollte jedoch auch für Notfalländerungen oder ungeplante Releases verwendet werden, obwohl hier manche Teams gern eine Abkürzung nehmen. Achte darauf, dass Änderungsanfragen automatisch von der CD-Pipeline geschlossen werden, wenn ein Fehler einen Abbruch erzwingt. Dies sorgt dafür, dass Änderungsanfragen nicht während des Pipeline-Workflows aufgegeben werden.
Die Abbildung unten verdeutlicht den im Zusammenhang mit der CD-Systemphase beschriebenen Workflow. Ein Hinweis dazu: Bei einigen Schritten kann manuelles Eingreifen erforderlich sein. Diese manuellen Schritte können als Bestandteil manueller Gates in der Pipeline ausgeführt werden. Wenn wir die gesamte Pipeline visualisieren, ähnelt sie stark der Darstellung der Wertstromanalyse für das Produkt-Release.
B) Zertifizierung von Subsystemen und/oder Systemen in der Staging-Umgebung
Nach der Zertifizierung des zusammengestellten Systems wird die Zusammenstellung unverändert an die Produktion übermittelt.
CD-Produktionsphase
Unabhängig davon, ob die Subsysteme eigenständig bereitgestellt werden können oder zu einem System zusammengestellt werden müssen, werden die versionierten Artefakte im Zuge dieser finalen Phase in der Produktionsumgebung bereitgestellt.
Zero Downtime Deployment (ZDD), also Deployment ohne Ausfallzeit, verhindert Ausfälle für die Kunden und sollte von den Tests über das Staging bis hin zur Produktion praktiziert werden. Eine beliebte ZDD-Technik ist Blue Green Deployment. Dabei werden die neuen Bestandteile für eine kleine Schnittmenge von Kunden ("Green") bereitgestellt, während der große Rest ("Blue") mit den alten Bestandteilen davon unberührt bleibt. Wenn es hart auf hart kommt, kannst du einfach alles auf "Blue" zurücksetzen, sodass nur bei sehr wenigen Kunden (wenn überhaupt) Störungen auftreten. Sieht bei "Green" alles gut aus, kannst du nach und nach alles von "Blue" auf "Green" umstellen.
In einigen Unternehmen werden manuelle Gates jedoch meiner Meinung nach missbraucht. Sie schreiben vor, dass die Teams in einem CAB-Meeting (Change Approval Board) eine manuelle Genehmigung einholen müssen. Dies ist in vielen Fällen auf eine Fehlinterpretation der Funktionstrennung oder "Separation of Concerns" zurückzuführen. Es erfolgt eine Übergabe von einer Abteilung an eine andere, um die Genehmigung zum Fortfahren zu erhalten. Ich habe auch schon erlebt, dass es den Genehmigern aus dem CAB an technischen Kenntnissen über die in Produktion gehenden Änderungen mangelte, wodurch der manuelle Genehmigungsprozess langsam und schwerfällig wurde.
Dies ist ein guter Zeitpunkt, um die Unterschiede zwischen Continuous Delivery und Continuous Deployment zu erklären. Bei Continuous Delivery können manuelle Gates eingesetzt werden, bei Continuous Deployment nicht. Beide Begriffe werden als CD abgekürzt, aber Continuous Deployment erfordert mehr Disziplin und Genauigkeit, da die Pipeline ohne menschlichen Eingriff abläuft.
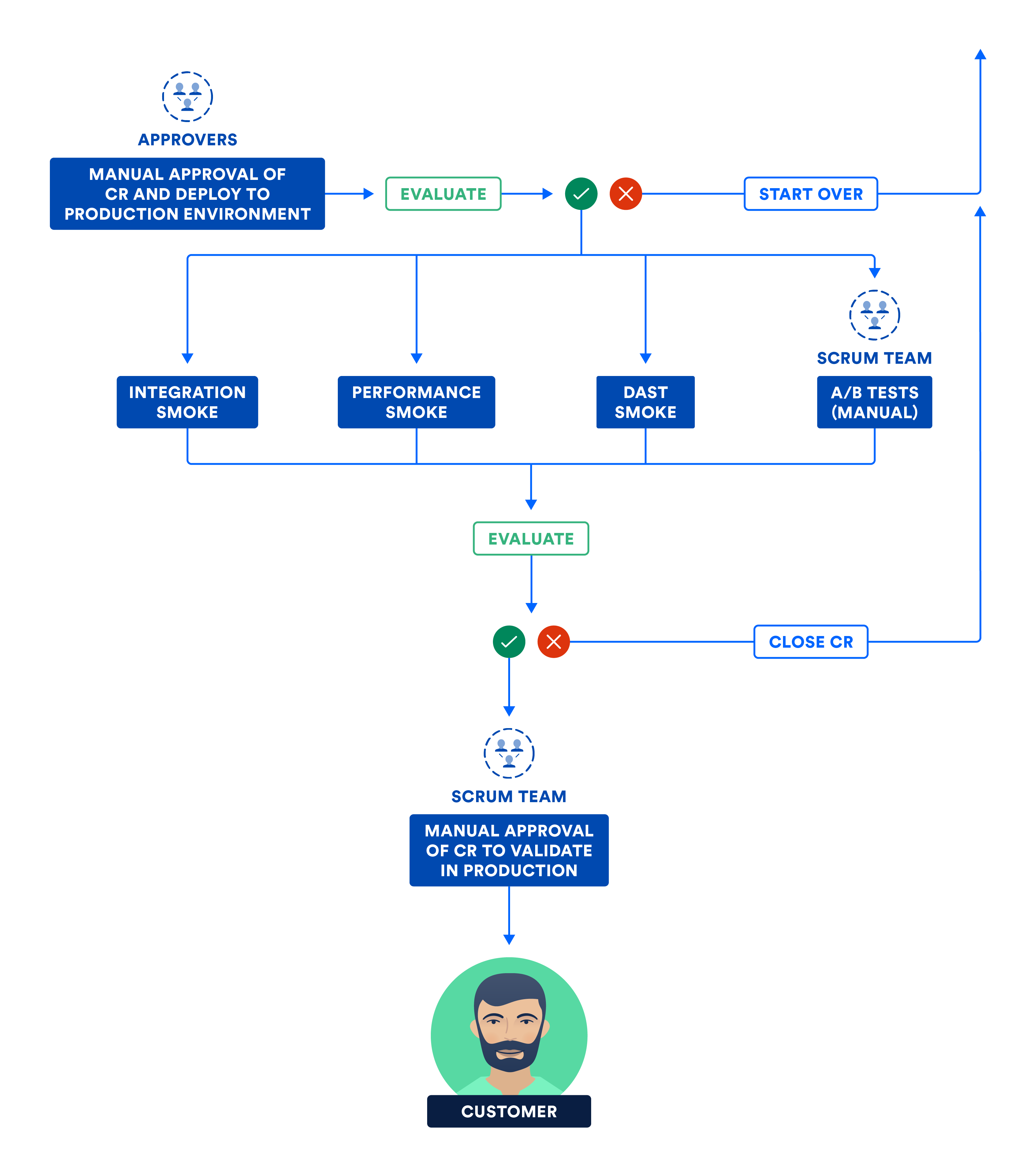
Es besteht ein Unterschied zwischen dem Verschieben und dem Aktivieren der Bestandteile. Du solltest Smoke-Tests in der Produktionsumgebung durchführen. Dabei handelt es sich um eine Untermenge der Integrations-, Leistungs- und Sicherheitstestsuites. Nach bestandenem Smoke-Test werden die Bestandteile aktiviert, woraufhin das Produkt für die Kunden verfügbar wird.
Das folgende Diagramm zeigt die Schritte, die das Team in der letzten Continuous-Delivery-Phase durchführt.
C) Zertifizierung von Subsystemen und/oder Systemen in der Produktionsumgebung
Continuous Delivery als neuer Standard
Wenn du mit Continuous Delivery oder Continuous Deployment Erfolg haben willst, sind auch Continuous Integration und Continuous Testing unverzichtbar. Eine solide Grundlage bringt an allen drei Fronten Vorteile: Qualität, Häufigkeit und Planbarkeit.
Eine Continuous-Delivery-Pipeline sorgt anhand mehrerer nachhaltiger Experimente dafür, dass deine Ideen zu Produkten werden können. Wenn du feststellst, dass eine Idee nicht so gut ist wie gedacht, kannst du ganz einfach eine neue Idee verfolgen. Pipelines beschleunigen außerdem mit einer niedrigeren mittleren Lösungszeit (MTTR, Mean Time To Resolve) die Behebung von Produktionsproblemen und sorgen so für geringere Ausfallzeiten beim Kunden. Continuous Delivery sorgt für produktive Teams und zufriedene Kunden – eine echte Win-win-Situation.
In unserem Tutorial zum Thema Continuous Delivery erfährst du mehr.
Diesen Artikel teilen
Nächstes Thema
Lesenswert
Füge diese Ressourcen deinen Lesezeichen hinzu, um mehr über DevOps-Teams und fortlaufende Updates zu DevOps bei Atlassian zu erfahren.

DevOps-Community

Blog lesen