Nozioni di base sulla pipeline di continuous delivery
Scopri come le build, i test e le distribuzioni automatizzati sono concatenati in un unico flusso di lavoro di rilascio.

Juni Mukherjee
Developer Advocate
Cos'è una pipeline di continuous delivery?
Una pipeline di continuous delivery è una serie di processi automatizzati per la consegna di un nuovo software. È un'implementazione del paradigma continuo, in cui build, test e distribuzioni automatizzati vengono orchestrati come un unico flusso di lavoro di rilascio. In poche parole, una pipeline di CD è un insieme di passaggi attraverso i quali le modifiche al codice passano per arrivare alla produzione.
Una pipeline di CD offre, secondo le esigenze aziendali, prodotti di qualità in modo frequente e prevedibile dall'ambiente di test a quello di staging fino a quello di produzione sfruttando l'automazione.
Per iniziare, concentriamoci su tre concetti: qualità, frequenza e prevedibilità.
We emphasize quality to underscore that it’s not traded for speed. Business doesn’t want us to build a pipeline that can shoot faulty code to production at high speed. We will go through the principles of “Shift Left” and “DevSecOps”, and discuss how we can move quality and security upstream in the software development life cycle (SDLC). This will put to rest any concerns regarding continuous delivery pipelines posing risks to businesses.
La frequenza indica che le pipeline vengono eseguite in qualsiasi momento per il rilascio di funzioni poiché sono programmate per essere attivate con commit nella base di codice. Una volta installata, la pipeline MVP (Minimum Viable Product, prodotto minimo funzionante) può essere eseguita tutte le volte che è necessario, con costi di manutenzione periodici. Questo approccio automatizzato è scalabile senza rischio di burnout per il team. Ciò consente inoltre ai team di apportare piccoli miglioramenti incrementali ai propri prodotti senza temere eventi catastrofici nella produzione.
Scopri la soluzione
Compilare e gestire software con Open DevOps
Materiale correlato
Cos'è la pipeline DevOps?
Per quanto possa sembrare un cliché, il proverbio "sbagliare è umano" rimane valido. I team si preparano all'impatto durante i rilasci manuali poiché questi processi sono fragili. La prevedibilità implica che i rilasci siano di natura deterministica se effettuati tramite pipeline di continuous delivery. Dal momento che le pipeline sono un'infrastruttura programmabile, i team possono aspettarsi sempre il comportamento desiderato. Gli imprevisti possono ovviamente capitare poiché nessun software è privo di bug. Tuttavia, le pipeline sono sensibilmente migliori rispetto ai processi di rilascio manuali soggetti a errori poiché, a differenza degli esseri umani, le pipeline non vacillano di fronte a scadenze serrate.
Le pipeline dispongono di porte software che promuovono o rifiutano automaticamente il passaggio di artefatti con versione. Se il protocollo di rilascio non viene rispettato, le porte software rimangono chiuse e la pipeline si interrompe. Vengono generati degli avvisi e vengono inviate delle notifiche a una lista di distribuzione composta dai membri del team che avrebbero potuto potenzialmente interrompere la pipeline.
Una pipeline di CD funziona proprio così: un commit, o un piccolo batch incrementale di commit, arriva in produzione ogni volta che la pipeline viene eseguita correttamente. Alla fine, i team rilasciano funzioni e successivamente prodotti in modo sicuro e verificabile.
Fasi della pipeline di continuous delivery
L'architettura del prodotto che passa attraverso la pipeline è un fattore chiave per determinare l'anatomia della pipeline di continuous delivery. Un'architettura di prodotto fortemente accoppiata genera un modello grafico complesso in cui diverse pipeline si ostacolano a vicenda prima di arrivare in produzione.
L'architettura di prodotto influenza anche le diverse fasi della pipeline e gli artefatti prodotti in ciascuna fase. Esaminiamo le quattro fasi comuni della continuous delivery:
Anche se prevedi di implementare più o meno di quattro fasi nella tua organizzazione, i concetti descritti di seguito si applicano comunque.
Un malinteso comune è che queste fasi abbiano manifestazioni fisiche nella pipeline. Ma non deve essere per forza così. Queste sono fasi logiche e possono essere riconducibili a milestone degli ambienti di test, staging e produzione. Ad esempio, i componenti e i sottosistemi possono essere compilati, testati e distribuiti nell'ambiente di test. I sottosistemi o i sistemi possono essere assemblati, testati e distribuiti nell'ambiente di staging. I sottosistemi o i sistemi possono essere promossi all'ambiente di produzione come parte della fase di produzione.
Il costo dei difetti è basso se vengono rilevati nell'ambiente di test, medio se rilevati in quello di staging e alto se rilevati nell'ambiente di produzione. Con "Shift Left" ci si riferisce alle convalide inserite nelle prime fasi della pipeline. Ormai, la porta che collega l'ambiente di test a quello di staging dispone di molte più tecniche difensive integrate e di conseguenza l'ambiente di staging non deve più sembrare una scena del crimine!
In passato, il reparto InfoSec interveniva alla fine del ciclo di vita di sviluppo del software, quando i rilasci rifiutati possono rappresentare minacce alla sicurezza informatica dell'azienda. Per quanto nobili fossero queste intenzioni, causavano frustrazioni e ritardi. "DevSecOps" sostiene l'integrazione della sicurezza nei prodotti fin dalla fase di progettazione, invece di inviare alla fase di valutazione un prodotto finito e possibilmente non sicuro.
Esaminiamo più da vicino come gli approcci "Shift Left" e "DevSecOps" possano essere implementati nel flusso di lavoro di continuous delivery. Nelle prossime sezioni ogni fase verrà descritta nei dettagli.
Fase dei componenti della CD
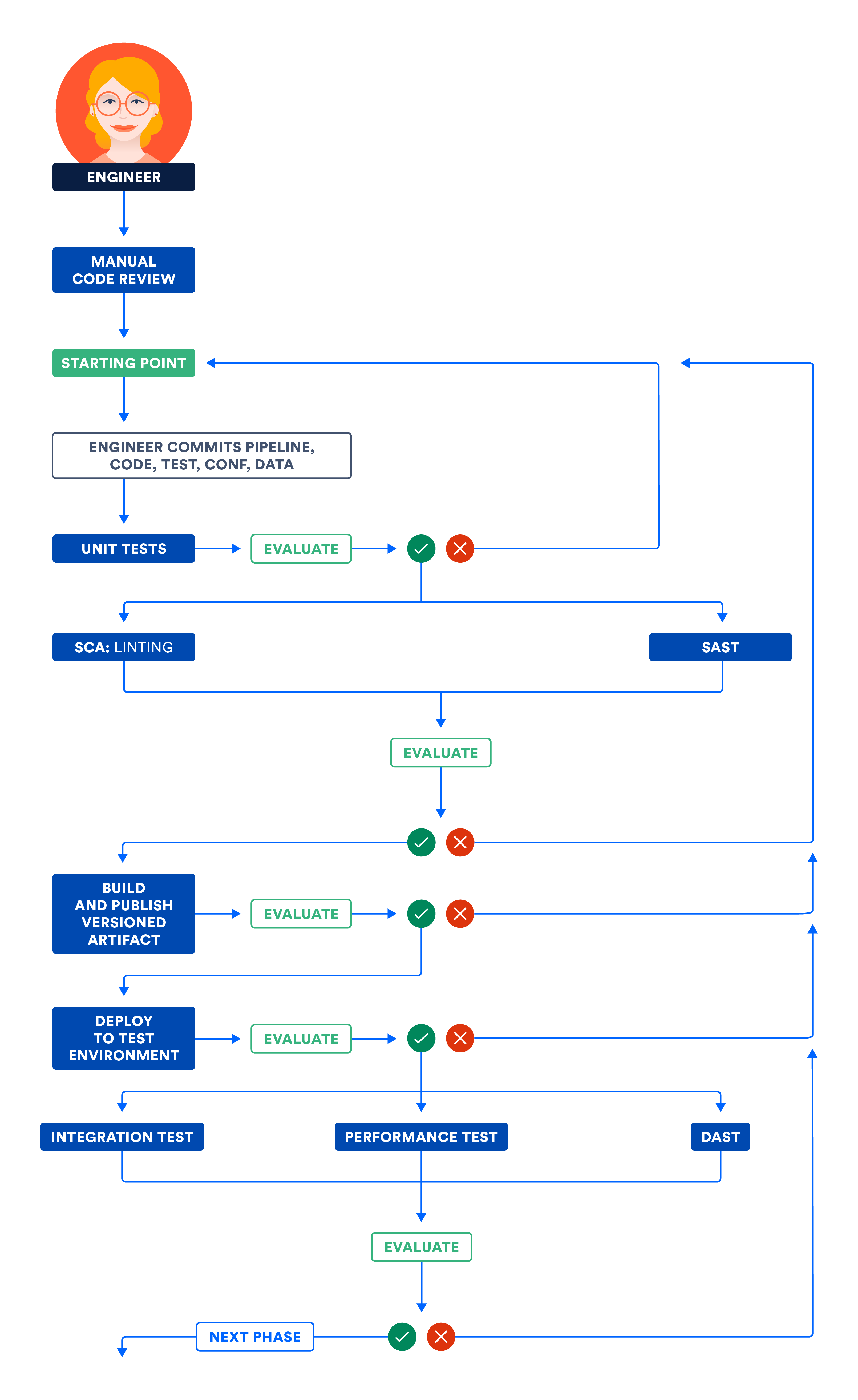
La pipeline crea innanzitutto i componenti, ossia le unità distribuibili e testabili più piccole del prodotto. Ad esempio, una raccolta creata dalla pipeline può essere definita un componente. Un componente può essere certificato, tra le altre cose, mediante revisioni del codice, unit test e analizzatori di codice statici.
Le revisioni del codice sono importanti perché consentono ai team di sviluppare una comprensione condivisa delle funzioni, dei test e dell'infrastruttura necessari per la messa in funzione del prodotto. Un secondo paio di occhi spesso può fare miracoli. Nel corso degli anni potremmo diventare immuni al codice errato in un modo che non crediamo più sia sbagliato. Nuove prospettive possono costringerci a riconsiderare questi punti deboli ed eseguirne il refactoring ovunque sia necessario.
Gli unit test costituiscono quasi sempre la prima serie di test del software che eseguiamo sul nostro codice. Non modificano il database né la rete. La code coverage è la percentuale di codice che è stato modificato dagli unit test. Esistono molti modi per misurare la copertura, ad esempio la copertura di linea, la copertura delle classi, la copertura dei metodi e così via.
Sebbene sia fantastico avere una buona copertura del codice per facilitare il refactoring, è dannoso imporre obiettivi di copertura elevati. Contrariamente a quanto si potrebbe intuire, alcuni team con un'elevata copertura del codice subiscono più interruzioni della produzione rispetto ai team con una copertura del codice inferiore. Inoltre, tieni presente che è facile manipolare i numeri relativi alla copertura. Sotto una forte pressione, soprattutto durante le revisioni delle prestazioni, gli sviluppatori possono ricorrere a pratiche sleali per aumentare la copertura del codice. E non parlerò di questi dettagli in questo articolo!
L'analisi statica del codice rileva i problemi nel codice senza eseguirlo. Si tratta di un modo economico per rilevare i problemi. Come i test unitari, questi test vengono eseguiti sul codice sorgente e hanno un tempo di esecuzione ridotto. Gli analizzatori statici rilevano potenziali perdite di memoria, insieme agli indicatori di qualità del codice come la complessità ciclomatica e la duplicazione del codice. Durante questa fase, il processo SAST (Static Analysis Security Testing, test statico di sicurezza o analisi statica) è un modo comprovato per individuare le vulnerabilità di sicurezza.
Definisci le metriche che controllano le porte software e influiscono sulla promozione del codice, dalla fase dei componenti a quella dei sottosistemi.
Fase del sottosistema di CD
I componenti debolmente accoppiati costituiscono i sottosistemi, ossia le unità distribuibili ed eseguibili più piccole. Alcuni esempi di sottosistemi sono i server e i microservizi in esecuzione in un container. A differenza dei componenti, i sottosistemi possono essere impostati e convalidati in base ai casi d'uso dei clienti.
I database sono dei sottosistemi proprio come l'interfaccia utente di Node.js e il livello API di Java. In alcune organizzazioni, i sistemi di gestione dei database relazionali (RDBMS, Relational Database Management System) vengono gestiti manualmente, anche se è adesso disponibile una nuova generazione di strumenti in grado di automatizzare la gestione delle modifiche del database e di eseguire correttamente la continuous delivery dei database. Le pipeline di CD che riguardano i database NoSQL sono più facili da implementare rispetto ai sistemi RDBMS.
I sottosistemi possono essere distribuiti e certificati mediante test funzionali, delle prestazioni e della sicurezza. Esaminiamo come convalidare il prodotto tramite ognuno di questi tipi di test.
I test funzionali includono tutti i casi d'uso dei clienti relativi all'internazionalizzazione (I18N), alla localizzazione (L10N), alla qualità dei dati, all'accessibilità, agli scenari negativi ecc... Questi test verificano che il prodotto funzioni in base alle aspettative dei clienti, che rispetti l'inclusione e serva il mercato per cui è stato creato.
Stabilisci i benchmark delle prestazioni insieme agli owner di prodotto. Integra i test delle prestazioni nella pipeline e usa i benchmark per superare o non superare le pipeline. C'è la convinzione comune che non sia necessario integrare i test delle prestazioni con le pipeline di continuous delivery; ma ciò interromperebbe il paradigma continuo.
Le organizzazioni più importanti hanno subito violazioni negli ultimi tempi e le minacce alla sicurezza informatica sono al livello massimo. Dobbiamo prepararci e assicurarci che non ci siano vulnerabilità di sicurezza nei nostri prodotti, sia nel codice che scriviamo che nelle librerie di terze parti che importiamo nel codice. In effetti, sono state rilevate gravi violazioni nel software open source (OSS) ed è necessario usare strumenti e tecniche che segnalino questi errori e forzino l'interruzione della pipeline. Il processo DAST (Dynamic Analysis Security Testing, test dinamico di sicurezza o analisi dinamica) è un modo comprovato per scoprire le vulnerabilità di sicurezza.
Nell'illustrazione che segue è esposto il flusso di lavoro descritto nelle fasi dei componenti e dei sottosistemi. Esegui i passaggi indipendenti in parallelo per ottimizzare il tempo totale di esecuzione della pipeline e ottenere un feedback rapido.
A) Certificazione dei componenti e/o dei sottosistemi nell'ambiente di test
Fase del sistema di CD
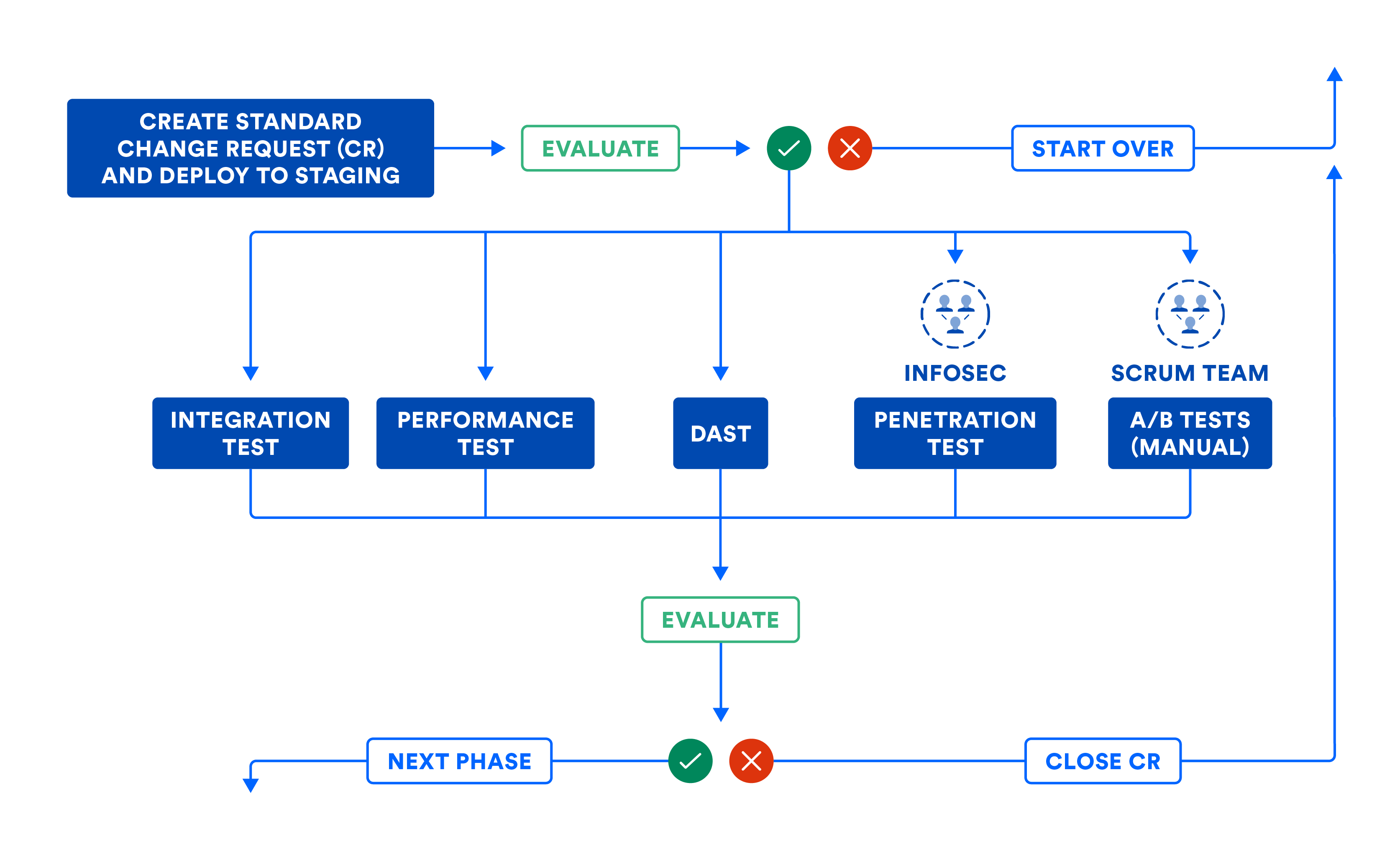
Una volta che i sottosistemi soddisfano le aspettative funzionali, prestazionali e di sicurezza, è possibile insegnare alla pipeline ad assemblare un sistema partendo da sottosistemi debolmente accoppiati nei casi in cui un sistema venga rilasciato nella sua interezza. Ciò significa che il team più veloce va alla stessa velocità di quello più lento. Questo mi ricorda il vecchio detto: "La forza di una catena si misura dal suo anello più debole".
Questo anti-pattern di composizione in cui i sottosistemi vengono formati in un sistema da rilasciare in blocco è sconsigliato perché lega a doppio giro tutti i sottosistemi per il raggiungimento del successo. Evita questo anti-pattern investendo invece in artefatti distribuibili in modo indipendente.
Laddove i sistemi devono essere convalidati nella loro totalità, possono essere certificati mediante test di integrazione, delle prestazioni e della sicurezza. Contrariamente alla fase del sottosistema, non usare simulazioni o stub durante i test in questa fase. Inoltre, ti consigliamo di concentrarti più di ogni altra cosa sui test delle interfacce e delle reti.
Nell'illustrazione seguente viene riassunto il flusso di lavoro della fase del sistema nel caso in cui sia necessario assemblare i sottosistemi utilizzando la composizione. Anche se è possibile implementare i sottosistemi nell'ambiente di produzione, usa questa illustrazione per stabilire le porte software necessarie per promuovere il codice da questa fase a quella successiva.
La pipeline può archiviare automaticamente le richieste di modifica (CR, Change Request) in modo da lasciare un audit trail. La maggior parte delle organizzazioni utilizza questo flusso di lavoro per le modifiche standard, ovvero i rilasci pianificati. Questo flusso di lavoro deve essere utilizzato anche per le modifiche di emergenza (o rilasci non pianificati), anche se alcuni team tendono a prendere delle scorciatoie. Osserva come la richiesta di modifica viene chiusa automaticamente dalla pipeline di CD quando gli errori ne forzano l'interruzione, per impedire che le richieste di modifica vengano abbandonate nel bel mezzo del flusso di lavoro della pipeline.
Nell'illustrazione che segue è esposto il flusso di lavoro descritto nella fase del sistema di CD. Nota che alcuni passaggi potrebbero comportare l'intervento umano e che questi passaggi manuali possono essere eseguiti come parte delle porte manuali della pipeline. Se mappata nella sua totalità, la visualizzazione della pipeline è molto simile alla mappa del flusso di valore dei rilasci del prodotto!
B) CERTIFICAZIONE DEI SOTTOSISTEMI E/O DEI SISTEMI NELL'AMBIENTE DI STAGING
Una volta certificato il sistema assemblato, promuovilo nell'ambiente di produzione senza apportare alcuna modifica.
Fase di produzione di CD
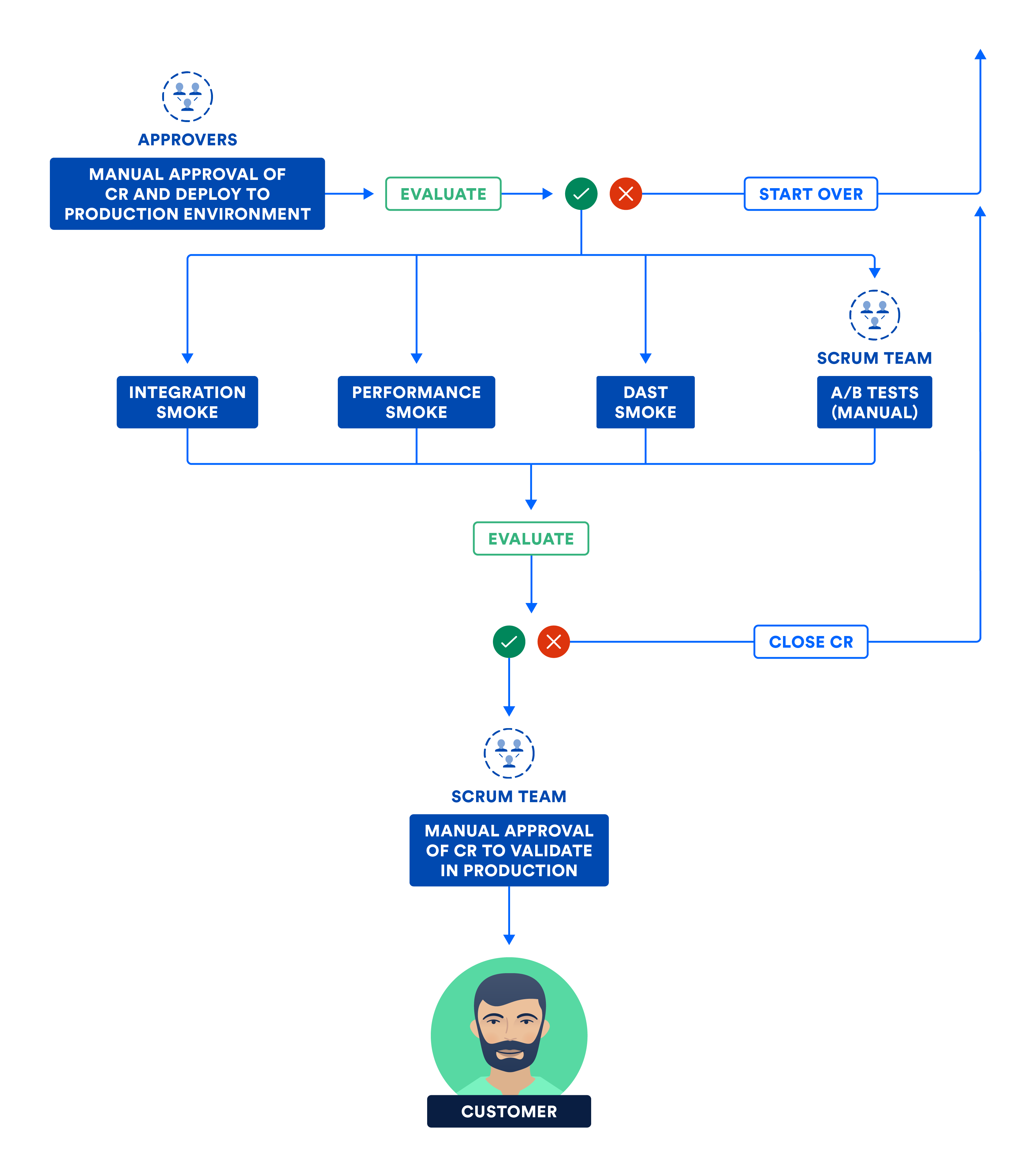
A prescindere dal fatto che i sottosistemi possano essere distribuiti o assemblati indipendentemente in un sistema, gli artefatti con versione vengono distribuiti nell'ambiente di produzione come parte di questa fase finale.
La distribuzione senza tempi di inattività (ZDD, Zero Downtime Deployment) evita i tempi di inattività ai clienti e deve essere messa in pratica nell'ambiente di test, in quello di staging fino a quello di produzione. La distribuzione blu-verde è una tecnica ZDD diffusa in cui i nuovi bit vengono distribuiti in una piccola sezione della popolazione (chiamata ambiente "verde"), mentre la maggior parte della popolazione ne è ignara e si trova nell'ambiente "blu", contenente i vecchi bit. Se arriva il momento di eseguire un push, tutti vengono riportati all'ambiente "blu" e pochissimi clienti (se presenti) saranno stati interessati da questo processo. Se non si verificano errori nell'ambiente "verde", tutti i clienti vengono fatti confluire lentamente in questo ambiente dall'ambiente "blu".
Tuttavia, vedo che le porte manuali vengono utilizzate in modo improprio in alcune organizzazioni che obbligano i team a ottenere l'approvazione manuale nelle riunioni del comitato di approvazione delle modifiche (CAB, Change Approval Board). Il motivo è, il più delle volte, un'interpretazione errata della separazione dei compiti o degli interessi. Un reparto consegna il lavoro a un altro per ottenere l'approvazione e proseguire con il lavoro. Ho anche visto alcuni approvatori del CAB dimostrare di avere una comprensione tecnica superficiale delle modifiche trasferite all'ambiente di produzione e rendere quindi lento e noioso il processo di approvazione manuale.
Questo è un ottimo spunto per sottolineare la differenza tra continuous delivery e continuous deployment. A differenza della continuous deployment, la continuous delivery rende possibile la presenza delle porte manuali. Sebbene entrambi gli approcci siano indicati con la sigla CD, la continuous deployment richiede più disciplina e rigore poiché non è previsto alcun intervento umano nella pipeline.
Il trasferimento dei bit è diverso dalla loro attivazione. Esegui smoke test (ovvero un sottoinsieme delle suite di test di integrazione, delle prestazioni e di sicurezza) nell'ambiente di produzione. Una volta superati gli smoke test, i bit vengono attivati e il prodotto viene rilasciato ai clienti.
Il diagramma seguente illustra i passaggi eseguiti dal team in questa fase finale della continuous delivery.
C) CERTIFICAZIONE DEI SOTTOSISTEMI E/O DEI SISTEMI NELL'AMBIENTE DI PRODUZIONE
La continuous delivery è la nuova normalità
Per implementare correttamente gli approcci di continuous delivery o continuous deployment, è fondamentale eseguire bene la continuous integration e i test continui. Con una base solida, vincerai su tutti e tre i fronti: qualità, frequenza e prevedibilità.
Le pipeline continuous delivery agevolano la trasformazione delle idee in prodotti attraverso una serie di esperimenti sostenibili. Se scopri che la tua idea non è così buona come pensavi, puoi cambiare rapidamente e passare a un'idea migliore. Inoltre, le pipeline riducono il tempo medio di risoluzione (MTTR) dei problemi di produzione, riducendo così anche i tempi di inattività per i clienti. Con la continuous delivery, i team saranno produttivi e i clienti soddisfatti: chi non lo vorrebbe?
Scopri di più nel nostro tutorial sulla continuous delivery.
Condividi l'articolo
Argomento successivo
Letture consigliate
Aggiungi ai preferiti queste risorse per ricevere informazioni sui tipi di team DevOps e aggiornamenti continui su DevOps in Atlassian.

Community DevOps

Leggi il blog