Continuous delivery: valore aziendale, vantaggi, sfide e metriche
La continuous delivery migliora la velocity, la produttività e la sostenibilità dei team di sviluppo.

Juni Mukherjee
Scrittore collaboratore
Perché affidarsi alla continuous delivery?
Quali emozioni suscita in te la parola "rilascio"? Sollievo? Euforia? Un incredibile senso di realizzazione? Quando le nuove funzioni sono finalmente disponibili per i clienti e i bug vengono corretti, tutti sono contenti, giusto? Beh, l'oscuro segreto di molte organizzazioni è che il rilascio di una versione richiede un impegno enorme. Se il tuo team usa ancora distribuzioni manuali o parzialmente basate su script o test manuali per prepararsi ai rilasci, i tuoi sentimenti potrebbero essere più vicini al "terrore" e alla "rabbia accecante".
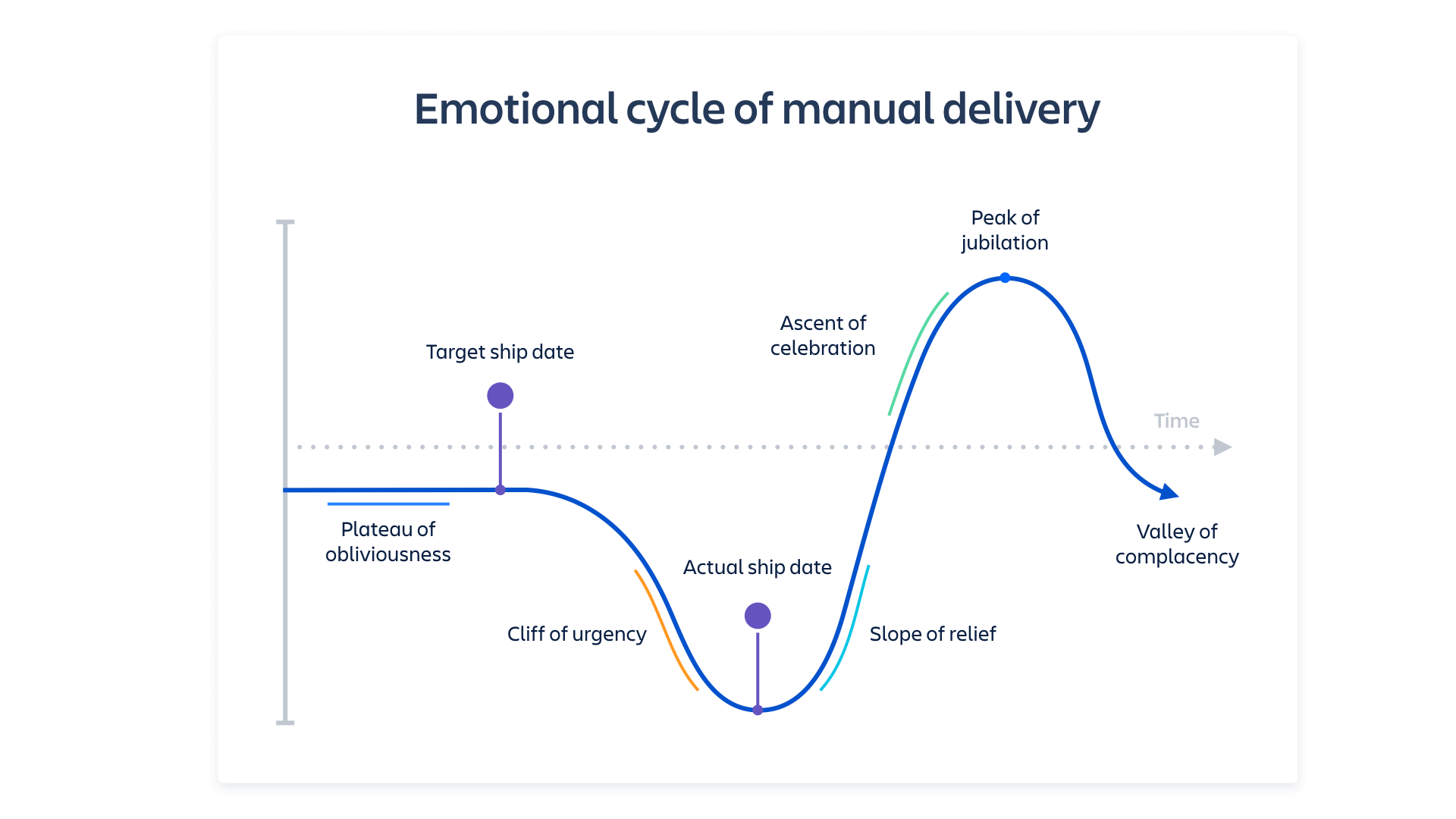
Ecco perché lo sviluppo del software si è orientato verso la continuità, tramite metodologie come Agile e DevOps. Il paradigma continuo prevede rilasci frequenti e prevedibili di prodotti di qualità ai clienti. Pertanto, la cerimonia e il rischio legati al rilascio sono ridotti. Facendo quotidianamente affidamento sulle pipeline, rileverai (e risolverai!) le carenze molto più rapidamente di quanto non faresti se queste si presentassero una volta ogni poche settimane o mesi. Ciò significa che, aumentando la frequenza dei rilasci dei prodotti, potrai ridurre la difficoltà. La cultura del miglioramento continuo è una metrica DevOps per i team ad alte prestazioni.
L'enfasi sulla continuous delivery, la continuous integration, i test continui, il monitoraggio costante e l'analisi delle pipeline indicano una tendenza generale nel settore del software, che aiuta i team a reagire ai cambiamenti del mercato. Per essere chiari: la CD non è una prerogativa esclusiva delle aziende "unicorno" e beniamine della tecnologia. Ogni team, dalla più umile start-up all'impresa più robusta, può e deve praticare la continuous delivery.
Questo articolo esamina il business case relativo a questo passaggio. Parleremo del lavoro che ci aspetta e dei vantaggi che comporta il rilascio di software tramite le pipeline di CD.
Scopri la soluzione
Compilare e gestire software con Open DevOps
Materiale correlato
Misura la frequenza di distribuzione
Principali vantaggi aziendali della continuous delivery
La continuous delivery migliora la velocity, la produttività e la sostenibilità dei team di sviluppo software.
1. Velocity
Le pipeline automatizzate di distribuzione del software aiutano le organizzazioni a rispondere meglio ai cambiamenti del mercato. La necessità di velocità è della massima importanza per ridurre i "tempi di conservazione" delle nuove funzioni. Con un time-to-market ridotto, le organizzazioni hanno maggiori possibilità di superare la concorrenza e rimanere in attività.
Ricorda che la velocità di per sé non è una metrica del successo. Senza qualità, la velocità è inutile. Non c'è alcun valore nell'avere pipeline di continuous delivery che inseriscono rapidamente codice errato nell'ambiente di produzione.

Quindi, nel mondo della continuous delivery, velocity significa velocità responsabile e non velocità controproducente.
2. Produttività
La produttività si traduce in felicità e i team felici sono più coinvolti.
La produttività aumenta quando task noiosi e ripetitivi, come la compilazione di un report sui bug per ogni difetto rilevato, possono essere eseguiti dalle pipeline anziché dalle persone. Ciò consente ai team di concentrarsi sulla vision mentre le pipeline si occupano dell'esecuzione. E chi non vuole delegare gli aspetti più complessi del lavoro agli strumenti?
I team esaminano i ticket segnalati dalle pipeline e, una volta eseguito il commit della correzione, le pipeline vengono eseguite nuovamente per verificare se il problema è stato risolto e se nuovi problemi sono stati introdotti inavvertitamente.

3. Sostenibilità
Le aziende mirano a vincere le maratone, non solo gli sprint. Sappiamo che anticipare gli altri richiede grinta. Rimanere sempre un passo avanti rispetto alla concorrenza può essere ancora più difficile. Ci vogliono disciplina e rigore. Lavorare sodo 24 ore su 24, 7 giorni su 7 porta a burnout prematuri. Invece, lavora in modo intelligente e delega il lavoro ripetitivo alle macchine, che tra l'altro non hanno bisogno di pause caffè e non rispondono in modo aggressivo!
Ogni organizzazione, che sia un'azienda tecnologica o meno, utilizza la tecnologia per differenziarsi. Le pipeline automatizzate riducono la manodopera manuale e portano a conseguenti risparmi poiché il personale è più costoso degli strumenti. Il consistente investimento iniziale può destare preoccupazione nei dirigenti inesperti, tuttavia, pipeline ben progettate consentono alle organizzazioni di innovare meglio e più velocemente per soddisfare le esigenze dei propri clienti. Le pratiche CD offrono all'azienda maggiore flessibilità nel modo di offrire funzioni e correzioni. Set specifici di funzioni possono essere rilasciati a clienti specifici o a un sottoinsieme di clienti, per garantire che funzionino e siano scalabili come previsto. Le funzioni possono essere testate e sviluppate, ma lasciate inattive nel prodotto, in preparazione per più rilasci. Il reparto marketing vuole presentare un "grande successo" alla convention annuale di settore? Con la continuous delivery non solo ciò è possibile, ma è persino una richiesta fin troppo semplice.
Principali sfide della continuous delivery
Sebbene siamo fermamente convinti che la continuous delivery sia la strada giusta da percorrere, può essere difficile per le organizzazioni progettare e compilare pipeline di continuous delivery resilienti. Poiché la CD richiede un'approfondita revisione dei processi tecnici, della cultura operativa e del pensiero organizzativo, spesso può sembrare molto complicato iniziare. L'ingente investimento richiesto nell'infrastruttura aziendale di distribuzione del software, che potrebbe essere stata trascurata nel corso degli anni, può rendere la CD una pillola ancora più amara da ingoiare.
Ci sono molti problemi che le organizzazioni devono affrontare e quelle indicate di seguito sono le tre insidie più comuni: budget, persone e priorità.
Budget: il tuo è troppo basso?
La costruzione di pipeline di continuous delivery consuma i dipendenti migliori. Non si tratta di un progetto secondario il cui costo può essere sottovalutato. Mi ha sempre sorpreso il modo in cui alcune organizzazioni iniziano assegnando membri junior e riducendo i costi per l'acquisto di strumenti moderni. Ad un certo punto, ovviamente correggono la rotta e incaricano gli architetti senior di investire nel disaccoppiamento dell'architettura e in pipeline di continuous delivery resilienti.
Non sottovalutare questo aspetto. In base alla tua vision, stanzia una quantità adeguata di fondi per assicurarti un'esecuzione priva di interruzioni. Distribuisci un MVP (Minimum Viable Product, prodotto minimo funzionante) della pipeline di continuous delivery e poi implementalo in tutta l'organizzazione.
Nel tuo team ci sono persone lungimiranti?
Anche quando hai budget a disposizione, in fin dei conti, l'esecuzione potrebbe essere un problema di persone.
I team dovrebbero automatizzare senza paura quanto più possibile il proprio lavoro e passare a nuovi progetti. Se ci sono persone che si preoccupano del fatto che gli agenti automatizzati svolgano i task che venivano altrimenti svolti da loro manualmente, hai assunto le persone sbagliate.
Se ci si sente bloccati, occorre cambiare marcia. Impara come mettere a disposizione del team un'auto quando tutto ciò che ha chiesto è un cavallo più veloce! Inizia subito avvalendoti dell'aiuto di esperti che ti aiuteranno a superare questo ostacolo iniziale. Le persone, dopo tutto, sono le tue risorse più importanti e occorre formarle per metterle nelle condizioni di fare la cosa giusta. Rendi facile fare la cosa giusta e difficile fare la cosa sbagliata, e il risultato ti sorprenderà.
Mancanza di priorità
"Interrompiamo la riga e compiliamo pipeline di continuous delivery!": nessun owner di prodotto ha mai detto questa frase.
In loro difesa, va detto che gli owner di prodotto si concentrano sull'anticipare la concorrenza con nuove funzioni che stupiscano tutti. Allo stesso tempo, c'è la consapevolezza di avere un problema se in ogni pianificatore di sprint le pipeline vengono confrontate con le funzioni del prodotto e vengono scambiate.
In alcuni backlog di prodotto, le pipeline, se ci sono, sono relegate vicino al fondo del backlog. I dirigenti miopi classificano il lavoro relativo alle pipeline come una spesa, piuttosto che come un investimento che si rivelerà utile per i team. Questi dirigenti continuano a negare i danni a lungo termine che creano e, sfortunatamente, a volte riescono a farla franca.
Le pipeline significano igiene. Se si vuole rimanere in attività, occorre chiedersi se l'igiene è importante. E possiamo scommetterci che lo sia!
Metriche di continuous delivery
L'elaborazione delle transazioni online (OLTP, Online Transaction processing) e l'elaborazione analitica online (OLAP, Online Analytical Processing) sono due tecniche ben note nel settore. Entrambi i concetti si applicano alle pipeline di continuous delivery e aiutano a generare informazioni che indirizzano le organizzazioni nella giusta direzione. Vediamo come.
Dalle pipeline passa una moltitudine di dati transazionali
Immagina una giornata lavorativa tipo di un team di sviluppo software. Il team esegue il commit di una funzione a cui l'azienda ha dato priorità, esegue il commit dei test per tale funzione e integra le distribuzioni con la pipeline di continuous delivery, in modo che ogni modifica venga distribuita automaticamente. Il team si rende conto che l'applicazione è diventata lenta dopo aver aggiunto questa nuova funzione ed esegue il commit di una correzione di tale problema di prestazioni. Aggiunge anche test delle prestazioni per assicurarsi che vengano rilevati tempi di risposta errati prima di promuovere l'applicazione dall'ambiente di test a quello di staging.
Pensa a ciascuno di questi commit come a una transazione. Ed è così che i team di sviluppo software procedono, una transazione dopo l'altra, fino alla nascita di un prodotto che lascerà tutti senza fiato. E poi si ricomincia. Moltiplica queste transazioni per tutti gli ingegneri e i team dell'organizzazione per ottenere una moltitudine di dati transazionali.

Questo è un ottimo spunto per passare alla prossima sezione sull'analisi delle pipeline e su come ottenere il massimo da questi dati transazionali.
Analizziamo i dati transazionali della pipeline
Possiamo analizzare i dati transazionali per estrarre porzioni di informazioni? Certo, che possiamo!
Come con tutti i dati transazionali, l'enorme volume ci impedisce di agire in modo sensato. Ecco perché è necessario aggregare ed eseguire analisi per raccogliere informazioni sulla nostra organizzazione. Le analisi ci aiutano a ottenere una visione d'insieme, ed ecco tre esempi di come abbiamo migliorato le nostre pratiche grazie all'analisi e agli approfondimenti delle pipeline.
Tra le centinaia di distribuzioni che avvengono ogni settimana, abbiamo rilevato che il numero di errori di distribuzione dell'applicazione A è tre volte superiore a quello dell'applicazione B. Questa scoperta ci ha portato a studiare le scelte di progettazione relative all'applicazione A sulla stabilità dell'ambiente e sulla gestione della configurazione. Abbiamo appreso che il team utilizzava macchine virtuali instabili nel proprio data center per la distribuzione, mentre l'applicazione B era containerizzata. Abbiamo dato priorità a un investimento in un'infrastruttura immutabile e abbiamo ricontrollato dopo un mese per assicurarci che il ritorno sull'investimento fosse positivo. E di certo lo era. Ciò che può essere misurato, può essere corretto.
Un altro esempio è quando abbiamo appreso che gli errori di analisi statica del codice dell'applicazione B hanno registrato una tendenza costante al rialzo negli ultimi trimestri. Ciò potrebbe significare che il team dietro l'applicazione B ha bisogno di un'ulteriore formazione per scrivere codice migliore. Abbiamo anche scoperto che gli analizzatori di codice statici riportavano falsi positivi, ovvero segnalavano violazioni del codice quando in effetti non ce n'erano. Quindi, abbiamo sostituito l'analizzatore del team con un noto strumento standard del settore che ha consentito di ridurre i falsi positivi in una certa misura. Abbiamo organizzato un workshop di programmazione in cui abbiamo discusso e risolto i legittimi errori dell'analisi statica. Alla fine del workshop, il team lavorava già in perfetta sintonia.
Un'altra intuizione interessante è stata che i test unitari dell'applicazione A avevano una copertura del codice inferiore rispetto alle applicazioni B e C, ma nonostante questo l'applicazione A ha registrato il minor numero di ticket di produzione nell'ultimo anno. La scrittura di test unitari e la misurazione della copertura del codice sono attività utili. Ma esagerare con questo esercizio è improduttivo per il team e inutile per i clienti. Lezione imparata.
Indicatori di prestazioni chiave (KPI)
Non possiamo fare affidamento sulle opinioni quando si tratta di indirizzare l'organizzazione nella giusta direzione. Innanzitutto, dobbiamo definire i KPI in base a cosa si intende per "successo". In secondo luogo, dobbiamo prendere decisioni basate sui dati analizzando i KPI di mesi, trimestri e anni.
Confronto tra KPI organizzativi e KPI dipartimentali
Molte volte abbiamo visto i singoli reparti definire le proprie metriche di successo. È positivo che i reparti capiscano cosa significhi per loro il successo, purché tali metriche siano legate agli obiettivi dell'organizzazione.
Confronto tra gli errori nell'ambiente di test, di staging e di produzione
In alcune organizzazioni è previsto che il team di sviluppo sia responsabile dell'ambiente di test, il team di controllo di qualità dell'ambiente di staging e quello delle operazioni dell'ambiente di produzione. Per evitare di essere sommersi dai report sulla copertura del codice relativamente ai test unitari eseguiti nell'ambiente di test, è importante che gli sviluppatori facciano un passo indietro ed esaminino il quadro generale di tutti gli ambienti, a prescindere dal fatto che ne siano responsabili o meno.
La percentuale di errori nell'ambiente di staging dovuti ai test delle prestazioni potrebbe essere elevata e potrebbe essere dovuta a benchmark delle prestazioni errati o a un codice lento. Un'analisi comparativa potrebbe dimostrare che le pipeline producono errori soprattutto negli smoke test di integrazione nell'ambiente di produzione e ciò giustificherebbe un'ulteriore analisi. La causa principale potrebbero essere dei bug reali nel prodotto o un codice di test difettoso, dati di test imprecisi, una configurazione errata del test, incomprensioni tra il team di prodotto e quello di progettazione e simili.
Da ulteriori approfondimenti potrebbe emergere che le configurazioni di test errate sono dilaganti e si potrebbe dare priorità alla risoluzione di questi problemi per correggere i frequenti errori di integrazione. Inoltre, anche gli sviluppatori che sono responsabili del codice fino all'ambiente di produzione sono conformi al paradigma DevOps.
Indice di stabilità
Una volta definiti i KPI, è fondamentale capire se un singolo KPI è viziato da pregiudizi e tende fortemente verso una particolare direzione. In caso affermativo, occorre bilanciarlo con altri KPI per ottenere maggiore equilibrio. Uno di questi KPI è la stabilità.
Gli sviluppatori misurano la stabilità con il parametro FeatureLeadTime, ovvero il tempo impiegato per rendere disponibile una funzione nell'ambiente di produzione. Dal momento che una funzione comprende più commit, una misurazione più granulare del parametro FeatureLeadTime è il parametro Checkin2goLive, ovvero il tempo impiegato perché un controllo entri nell'ambiente di produzione.
Misura il parametro Checkin2goLive tramite le pipeline, poiché quest'ultimo può essere approssimato in base al tempo impiegato da una pipeline per promuovere il codice dall'ambiente di test, a quello di staging e a quello di produzione. Inoltre, Checkin2goLive riflette anche i difetti del tempo medio di risoluzione (MTTR), poiché la correzione dei bug attraversa la stessa pipeline dall'ambiente di test, a quello di staging fino a quello di produzione.
È interessante notare che per il team delle operazioni la velocità ha spesso una connotazione negativa, poiché questo team è incentivato a essere avverso ai rischi. I membri del team delle operazioni misurano il numero di difetti sfuggiti per riflettere l'errore e definiscono la stabilità in base alla percentuale di difetti rilevati dalla pipeline rispetto a quelli che sono sfuggiti.
Il team aziendale definisce la stabilità in base alla soddisfazione dei clienti o al numero di clienti abituali. Anche se questo valore sembra soggettivo, è possibile approssimare questa metrica in base al numero di difetti segnalati dai clienti o tramite i sondaggi di feedback dei clienti.
L'indice di stabilità è un classico esempio in cui i team di sviluppo, delle operazioni e aziendale sono fermi nelle loro posizioni; tuttavia, è auspicabile che l'organizzazione crei un ambiente di lavoro armonioso, invece di non affidarsi a nessuno. Quindi, crea un indice organizzativo di stabilità imparziale.
Indice di qualità del codice
Un altro esempio in cui è necessario tenere conto di diversi punti di vista riguarda la qualità del codice. Alcuni dicono che la qualità del codice si riflette nella copertura del codice misurata mediante test unitari, mentre altri sostengono che sia legata alla complessità ciclomatica. Gli analizzatori statici standard segnalano duplicazioni di codice, vulnerabilità di sicurezza e potenziali perdite di memoria. Tutte queste sono reali misure della qualità del codice e quindi è consigliabile creare un indice in cui tutte queste metriche, e magari anche altre, svolgano un ruolo.
Confronto tra KPI aziendali e KPI tecnici
Un altro KPI popolare che le organizzazioni amano tenere d'occhio è il valore fornito in uno sprint. Una cattiva pratica comune è registrare il numero di rilasci, che di per sé non aggiungono valore. È possibile spostare elementi dal punto A al punto B senza alcun impatto sull'equilibrio dell'attività, ma non è sufficiente. Alcune organizzazioni misurano il numero di test appena aggiunti in un determinato sprint o il numero totale di test eseguiti, test che comunque non riflettono i risultati aziendali, ma solo il lavoro di progettazione. Il valore fornito in uno sprint deve essere rilevante per il business.
Un paio di esempi di KPI aziendali potrebbero essere il numero di acquisizioni di clienti nell'ultimo trimestre e il numero di clic pubblicitari nell'ultimo mese. Le pipeline non influenzano direttamente queste metriche aziendali. L'unico motivo per cui cerchiamo di mappare i KPI aziendali rispetto ai KPI tecnici è per comprendere la relazione tra il lavoro tecnico e gli obiettivi aziendali.
I KPI aziendali mappati alle pipeline aiutano anche a calcolare il ROI (ritorno sull'investimento) delle pipeline. I team dirigenziali utilizzano queste metriche per comprendere le possibili aree di miglioramento e per pianificare il budget.
Intraprendi il tuo viaggio
Non perdere tempo a discutere se la continuous delivery è adatta alle tue esigenze, se la continuous integration è sufficiente o se la continuous deployment ti porterà al settimo cielo. Se intraprendi questo viaggio, si apriranno enormi opportunità di miglioramento continuo per il tuo team! I tuoi team potranno sperimentare senza paura e non soffriranno di burnout a causa dei rilasci straordinari.
Scopri come creare una pipeline di continuous integration, delivery e deployment (CI/CD) con i nostri tutorial su CI/CD DevOps. Inoltre, Open DevOps di Atlassian fornisce una piattaforma di toolchain aperta che ti consente di creare una pipeline di sviluppo basata su CD con gli strumenti che preferisci.
Condividi l'articolo
Argomento successivo
Letture consigliate
Aggiungi ai preferiti queste risorse per ricevere informazioni sui tipi di team DevOps e aggiornamenti continui su DevOps in Atlassian.

Community DevOps

Leggi il blog