Como lidar com repositórios grandes com o Git

Nicola Paolucci
Representante do desenvolvedor
O Git é uma escolha fantástica para acompanhar a evolução da base de código e ter uma colaboração eficiente com colegas. Mas o que acontece quando o repositório que você quer rastrear é muito grande?
Neste texto, vou dar algumas técnicas para lidar com essa situação.
Duas categorias de repositórios grandes
Se você parar para pensar, existem duas razões principais para os repositórios terem um crescimento massivo:
- Eles acumulam um histórico muito longo (o projeto cresce por um período prolongado e a bagagem se acumula)
- Eles incluem enormes arquivos binários que precisam ser rastreados e emparelhados com o código.
… ou pode ser os dois.
Às vezes, o segundo tipo de problema é agravado pelo fato de que artefatos binários antigos e obsoletos ainda estão armazenados no repositório. Mas há uma correção moderadamente fácil — embora irritante — para isso (veja abaixo).
As técnicas e soluções alternativas para cada cenário são diferentes, embora às vezes complementares. Então, vou abordá-las separadamente.
Clonagem de repositórios com um histórico muito longo
Mesmo que o limite para qualificar um repositório como "massivo" seja muito alto, eles ainda são difíceis de clonar. E nem sempre é possível evitar históricos longos. Alguns repositórios devem ser mantidos intactos por razões legais ou regulamentares.
Solução simples: clone superficial do git
A primeira solução para um clone rápido e economia de tempo e espaço em disco do desenvolvedor e do sistema é copiar apenas as revisões recentes. A opção de clone superficial do Git permite que você extraia apenas os n commits mais recentes do histórico do repositório.
Como se usa esse recurso? Basta usar a opção –depth. Por exemplo:
git clone --depth [depth] [remote-url]
Imagine que você acumulou dez ou mais anos de histórico de projetos em seu repositório. Por exemplo, migramos o Jira (uma base de código de 11 anos) para o Git. A economia de tempo para repositórios como esse pode aumentar e ser muito perceptível.
O clone completo do Jira tem 677 MB, com o diretório de trabalho tendo outros 320 MB, compensando mais de 47.000 commits. Um clone superficial do repositório leva 29,5 segundos, em comparação com 4 minutos e 24 segundos para um clone completo com todo o histórico. A disparidade também cresce em proporção a quantos arquivos binários seu projeto engoliu ao longo do tempo.
Material relacionado
Como mover um Repositório do Git completo
VER SOLUÇÃO
Aprenda a usar o Git com o Bitbucket Cloud
Dica: Crie sistemas conectados ao seu repositório do Git. Se beneficie de clones superficiais também!
Os clones superficiais costumavam ser cidadãos um pouco prejudicados do mundo Git, pois algumas operações mal eram suportadas. Mas as versões recentes (1.9 ou superior) melhoraram muito a situação, e agora você pode extrair e enviar para os repositórios, mesmo a partir de um clone superficial.
Solução cirúrgica: branch de filtro do Git
Para os enormes repositórios que têm grandes excedentes binários com commit por engano ou arquivos antigos não são mais necessários, uma ótima solução é usar a git filter-branch. O comando permite percorrer todo o histórico do projeto filtrando, modificando e pulando arquivos de acordo com padrões predefinidos.
É uma ferramenta muito poderosa depois de identificar onde seu repositório é pesado. Existem scripts auxiliares disponíveis para identificar objetos grandes, então essa parte deve ser bem fácil.
A sintaxe é assim:
git filter-branch --tree-filter 'rm -rf [/path/to/spurious/asset/folder]'No entanto, o git filter-branch tem uma pequena desvantagem: depois de usar _filter-branch_, você efetivamente reescreve todo o histórico do seu projeto. Ou seja, todos os IDs de commit mudam. Assim, é preciso que todos os desenvolvedores reclonem o repositório atualizado.
Então, se você está planejando realizar uma ação de limpeza usando git filter-branch, você deve alertar sua equipe, planejar um pequeno congelamento enquanto a operação é realizada e, em seguida, notificar a todos que eles devem clonar o repositório de novo.
Dica: Saiba mais sobre git filter-branch nesta publicação sobre como destruir seu repositório do Git.
Alternativa ao clone superficial do git: clone apenas um branch
Desde o git 1.7.10, você também pode limitar a quantidade de histórico clonado, clonando uma única ramificação, da seguinte forma:
git clone [remote url] --branch [branch_name] --single-branch [folder]Esse hack específico é útil quando você está trabalhando com ramificações divergentes e de longa duração, ou se você tem muitas ramificações e só precisa trabalhar com algumas delas. Se você tiver apenas algumas ramificações com poucas diferenças, é provável que não veja uma grande diferença.
Gerenciando repositórios com enormes ativos binários
O segundo tipo de repositório grande são aqueles com enormes arquivos binários. É algo que muitos tipos diferentes de equipes de software (e sem ser de software!) encontram. As equipes de jogos precisam lidar com enormes modelos 3D, as equipes de desenvolvimento da web podem precisar rastrear arquivos de imagem bruta, as equipes de CAD podem precisar manipular e rastrear o status dos entregáveis binários.
O Git não é muito ruim no manuseio de arquivos binários, mas também não é lá muito bom. Por padrão, o Git vai compactar e armazenar todas as versões completas subsequentes dos arquivos binários, o que não é o ideal se você tiver muitos.
Existem alguns ajustes básicos que melhoram a situação, como executar a coleta de lixo ("git gc"), ou ajustar o uso de commits delta para alguns tipos binários em .gitattributes.
Mas é importante refletir sobre a natureza dos arquivos binários do seu projeto, pois isso vai ajudar a determinar a abordagem vencedora. Por exemplo, aqui estão alguns pontos a serem considerados:
- Para arquivos binários que mudam muito — e não apenas alguns cabeçalhos de metadados — é provável que a compactação delta vai ser inútil. Portanto, use 'delta off' para esses arquivos para evitar o trabalho desnecessário de compactação delta como parte da recompactação.
- No cenário acima, é provável que esses arquivos também não sejam compactados com zlib muito bem, então você pode desativar a compactação com 'core.compression 0' ou 'core.loosecompression 0'. Essa é uma configuração global que prejudicaria todos os arquivos não binários que compactam bem, então a sugestão faz sentido se você dividir os arquivos binários em um repositório separado.
- É importante lembrar que "git gc" transforma os objetos soltos “duplicados” em um único arquivo de pacote. Mas, vale lembrar, a menos que os arquivos sejam compactados de alguma forma, talvez não faça nenhuma diferença significativa na relação com o arquivo de pacote resultante.
- Explore o ajuste do core.bigFileThreshold. Qualquer coisa maior que 512 MB não vai ser compactada em delta de qualquer maneira (sem ter que definir .gitattributes) então talvez isso seja algo que valha a pena ajustar.
Solução para árvores de pastas grandes: checkout esparso do git
Uma ajuda leve para o problema de arquivos binários é o checkout esparso (disponível desde o Git 1.7.0). Essa técnica permite manter o diretório de trabalho limpo, detalhando quais pastas você quer preencher. Infelizmente, essa ação não afeta o tamanho do repositório local geral, mas pode ser útil se você tiver uma enorme árvore de pastas.
Quais são os comandos envolvidos? Aqui está um exemplo:
- Clone o repositório completo uma vez: 'git clone'
- Ative a função: git config core.sparsecheckout true
- Adicione pastas que necessárias, ignorando as pastas de ativos:
- echo src/ › .git/info/sparse-checkout
- Leia a árvore conforme especificado:
- git read-tree -m -u HEAD
Depois do exposto acima, você pode voltar a usar seus comandos git normais, mas o diretório de trabalho vai conter apenas as pastas especificadas acima.
Solução para controlar quando você atualiza arquivos grandes: submódulos
[ATUALIZAÇÃO] … ou você pode pular tudo o que foi dito e usar o Git LFS
Se você costuma trabalhar com arquivos grandes, a melhor solução pode ser aproveitar o suporte a arquivos grandes (LFS) desenvolvido pela Atlassian em parceria com o GitHub em 2015. (Sim, você leu certo. Fizemos uma parceria com o GitHub em uma contribuição de código aberto para o projeto Git.)
Git LFS é uma extensão que armazena ponteiros (é claro!) para arquivos grandes no repositório, em vez de armazenar os próprios arquivos. Os arquivos reais são armazenados em um servidor remoto. Como você pode imaginar, isso reduz demais o tempo necessário para clonar seu repositório.
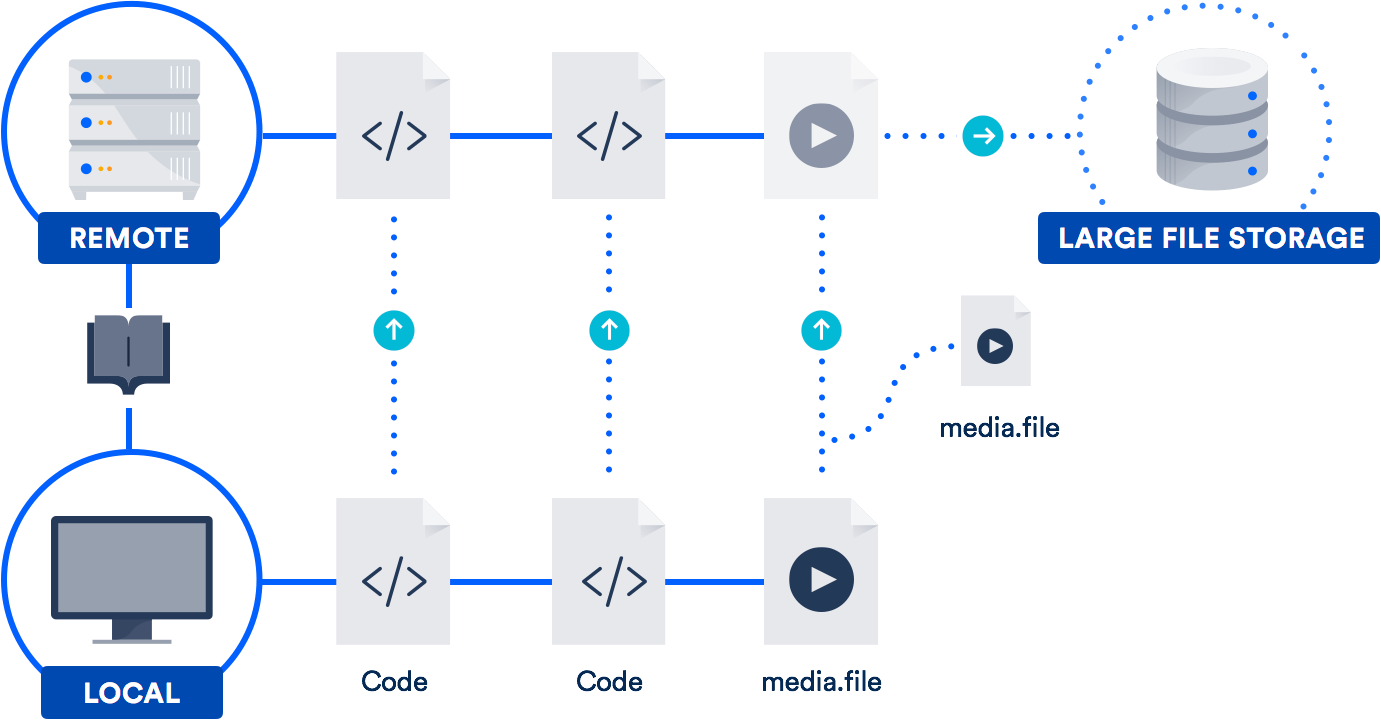
O Bitbucket é compatível com Git LFS, assim como o GitHub. Então, é provável que você já tenha acesso a essa tecnologia. É muito útil para equipes que incluem designers, cinegrafistas, músicos ou usuários de CAD.
Conclusões
Não desista dos recursos fantásticos do Git só porque você tem um enorme histórico de repositório ou arquivos enormes. Existem soluções viáveis para os dois problemas.
Confira os outros artigos com link acima para obter mais informações sobre submódulos, dependências de projetos e Git LFS. E para atualizações sobre comandos e fluxo de trabalho, o microsite Git tem muitos tutoriais. Boa codificação!
Compartilhar este artigo
Próximo tópico
Leitura recomendada
Marque esses recursos para aprender sobre os tipos de equipes de DevOps ou para obter atualizações contínuas sobre DevOps na Atlassian.

Blog do Bitbucket

Caminho de aprendizagem de DevOps
