Monorepos no Git
O que é um monorepo?
As definições variam, mas definimos um monorepo da seguinte forma:
- O repositório contém mais de um projeto lógico (por exemplo, um client iOS e um aplicativo da Web)
- Esses projetos talvez não estão relacionados, estão conectados de um jeito impreciso ou podem ser conectados por outros meios (por exemplo, por meio de ferramentas de gerenciamento de dependências)
- O repositório é grande de várias maneiras:
- Número de commits
- Número de ramificações e/ou marcações
- Número de arquivos rastreados
- Tamanho do conteúdo rastreado (conforme medido observando o diretório .git do repositório)
O Facebook tem um exemplo de monorepo:
Com milhares de confirmações por semana em milhares de arquivos, o principal repositório fonte do Facebook é enorme — muitas vezes maior do que até mesmo o kernel Linux, que registrou 17 milhões de linhas de código e 44.000 arquivos em 2013.
Material relacionado
Como mover um Repositório do Git completo
VER SOLUÇÃO
Aprenda a usar o Git com o Bitbucket Cloud
E durante a realização de testes de desempenho, o repositório de testes usado pelo Facebook foi o seguinte:
- 4 milhões de confirmações
- Histórico linear
- Cerca de 1,3 milhão de arquivos
- O tamanho do diretório .git era cerca de 15 GB
- O tamanho do arquivo de índice era 191 MB
Desafios conceituais
Existem muitos desafios conceituais ao gerenciar projetos não relacionados em um monorepo no Git.
Primeiro, o Git rastreia o estado de toda a árvore em cada confirmação feita. Essa ação é boa para projetos únicos ou relacionados, mas se torna difícil de manejar para repositórios com muitos projetos não relacionados. Simplificando, os commits em partes não relacionadas da árvore afetam a subárvore que é relevante para um desenvolvedor. Esse item é pronunciado em escala com um grande número de commits avançando na história da árvore. Como a ponta do ramo está mudando o tempo todo, é necessária uma mesclagem ou rebase frequente no local para fazer alterações.
No Git, uma marcação é um alias nomeado para um commit específico, referindo-se a toda a árvore. Mas a utilidade das marcações diminui no contexto do monorepo. Pergunte a si mesmo: se você estiver trabalhando em um aplicativo da web que é implementado sem interrupção em monorepo, qual é a relevância da marcação de lançamento para o cliente iOS com versão?
Problemas de desempenho
Em conjunto com esses desafios conceituais, há vários problemas de desempenho que podem afetar a configuração de um monorepo.
Número de commits
Gerenciar projetos não relacionados em um único repositório em escala pode ser problemático no nível da confirmação. Com o tempo, essa ação pode levar a um grande número de commits com a taxa significativa de crescimento (o Facebook cita “milhares de commits por semana”). O que pode se tornar problemático, pois o Git usa um gráfico acíclico direcionado (DAG) para representar a história do projeto. Com um grande número de commits, qualquer comando que percorre o gráfico pode se tornar lento à medida que o histórico se aprofunda.
Some examples of this include investigating a repository's history via git log or annotating changes on a file by using git blame. With git blame if your repository has a large number of commits, Git would have to walk a lot of unrelated commits in order to calculate the blame information. Other examples would be answering any kind of reachability question (e.g. is commit A reachable from commit B). Add together many unrelated modules found in a monorepo and the performance issues compound.
Número de refs
Um grande número de refs (ou seja, ramificações ou marcações) no monorepo afeta o desempenho de várias maneiras.
Ref advertisements contain every ref in your monorepo. As ref advertisements are the first phase in any remote git operation, this affects operations like git clone, git fetch or git push. With a large number of refs, performance takes a hit when performing these operations. You can see the ref advertisement by using git ls-remote with a repository URL. For example, git ls-remote git://git.kernel.org/ pub/scm/linux/kernel/git/torvalds/linux.git will list all the references in the Linux Kernel repository.
If refs are loosely stored listing branches would be slow. After a git gc refs are packed in a single file and even listing over 20,000 refs is fast (~0.06 seconds).
Any operation that needs to traverse a repository's commit history and consider each ref (e.g. git branch --contains SHA1) will be slow in a monorepo. In a repository with 21708 refs, listing the refs that contain an old commit (that is reachable from almost all refs) took:
Tempo do usuário (segundos): 146,44*
*Isso varia dependendo dos caches de página e da camada de armazenamento subjacente.
Número de arquivos rastreados
O cache de índice ou diretório (.git/index) rastreia todos os arquivos no repositório. O Git usa esse índice para determinar se um arquivo foi alterado executando stat (1) em cada arquivo e comparando as informações de modificação do arquivo com as informações contidas no índice.
Assim, o número de arquivos rastreados afeta o desempenho* de muitas operações:
git statuspode ser lento (estatísticas de cada arquivo, arquivo de índice vai ser grande)git committambém pode ser lento (também estatísticas de cada arquivo)
*Isso varia dependendo dos caches de página e da camada de armazenamento subjacente, só é perceptível quando há um grande número de arquivos, na área de autenticação de dezenas ou centenas de milhares.
Arquivos grandes
Arquivos grandes em uma única subárvore/projeto afetam o desempenho de todo o repositório. Por exemplo, grandes ativos de mídia adicionados a um projeto cliente iOS em um monorepo são clonados apesar de um desenvolvedor (ou agente de build) trabalhar em um projeto não relacionado.
Efeitos combinados
Seja o número de arquivos, a frequência com que eles são alterados ou o tamanho, esses itens combinados têm um impacto maior no desempenho:
- Alternar entre ramificações/marcações, o que é mais útil em um contexto de subárvore (por exemplo, a subárvore em que estou trabalhando), ainda atualiza a árvore inteira. Esse processo pode ser lento devido ao número de arquivos afetados ou requer uma solução alternativa. Usando
git checkout ref-28642-31335 — templates, por exemplo, atualiza o diretório./templatespara corresponder à ramificação fornecida, mas sem atualizar oHEAD, que tem o efeito colateral de marcar os arquivos atualizados como modificados no índice. - A clonagem e a busca ficam mais lentas e consomem muitos recursos no servidor, pois todas as informações são condensadas em um arquivo de pacote antes da transferência.
- A coleta de lixo é lenta e, por padrão, acionada em um push (se a coleta de lixo for necessária).
- O uso de recursos é alto para cada operação que envolve a (re) criação de um arquivo de pacote, por exemplo,
git upload-pack, git gc.
Estratégias de mitigação
Embora fosse ótimo se o Git suportasse o caso de uso especial que os repositórios monolíticos tendem a ser, os objetivos de design do Git que o tornou bem-sucedido e popular às vezes estão em desacordo com o desejo de usar de uma forma para a qual não foi projetado. A boa notícia para a grande maioria das equipes é que repositórios monolíticos grandes tendem a ser a exceção e não a regra, então, por mais interessante que este post seja, talvez não se aplique a uma situação que você está enfrentando.
Dito isso, há uma série de estratégias de mitigação que podem ajudar ao trabalhar com grandes repositórios. Para repositórios com históricos longos ou grandes ativos binários, meu colega Nicola Paolucci descreve algumas soluções alternativas.
Remover refs
Se o repositório tiver refs na casa das dezenas de milhares, você deve considerar remover refs que você não precisa mais. O DAG mantém o histórico de como as mudanças evoluíram, enquanto os commits de merge apontam para os pais, para que o trabalho realizado nas ramificações possa ser rastreado mesmo que a ramificação não exista mais.
Em um fluxo de trabalho baseado em ramificações, o número de ramificações de longa duração que você quer reter deve ser pequeno. Não tenha medo de excluir uma ramificação de função de curta duração após uma mesclagem.
Considere remover todas as ramificações que foram mescladas em uma filial principal, como a produção. Rastrear o histórico de como as mudanças evoluíram ainda é possível, desde que o commit seja acessível a partir da ramificação principal e você tenha mesclado a ramificação com um commit de mesclagem. A mensagem de commit de mesclagem padrão em geral contém o nome da ramificação, permitindo que você retenha essas informações, se necessário.
Lidando com um grande número de arquivos
Se o repositório tiver um grande número de arquivos (na casa das dezenas a centenas de milhares), o armazenamento local rápido com muita memória, que também é usada como um cache de buffer, pode ajudar. Essa é uma área que exigiria mudanças mais significativas no cliente, semelhantes, por exemplo, às mudanças que o Facebook implementou para o Mercurial.
A abordagem usava notificações do sistema de arquivos para registrar alterações em arquivos em vez de iterar sobre todos os arquivos para verificar se algum foi alterado. Uma abordagem semelhante (também usando watchman) foi discutida para o git, mas ainda não foi encontrada.
Usar o Git LFS (armazenamento de arquivos grandes)
Esta seção foi atualizada em 20 de janeiro de 2016
Para projetos que incluem arquivos grandes, como vídeos ou gráficos, o Git LFS é uma opção para limitar o impacto no tamanho e no desempenho geral do repositório. Em vez de armazenar objetos grandes direto no repositório, o Git LFS armazena um pequeno arquivo de espaço reservado com o mesmo nome contendo uma referência ao objeto, que é armazenado em um armazenamento especializado de objetos grandes. O Git LFS se conecta às operações nativas de push, pull, checkout e fetch do Git para lidar com a transferência e a substituição desses objetos na árvore de trabalho de um jeito transparente. Isso significa que você pode trabalhar com arquivos grandes no repositório como faria em geral, sem a penalidade de tamanhos de repositório inchados.
O Bitbucket Server 4.3 (e posterior) incorpora uma implementação compatível do Git LFS v1.0+ e permite a visualização e a comparação de grandes ativos de imagem rastreados pelo LFS direto na interface do usuário do Bitbucket.
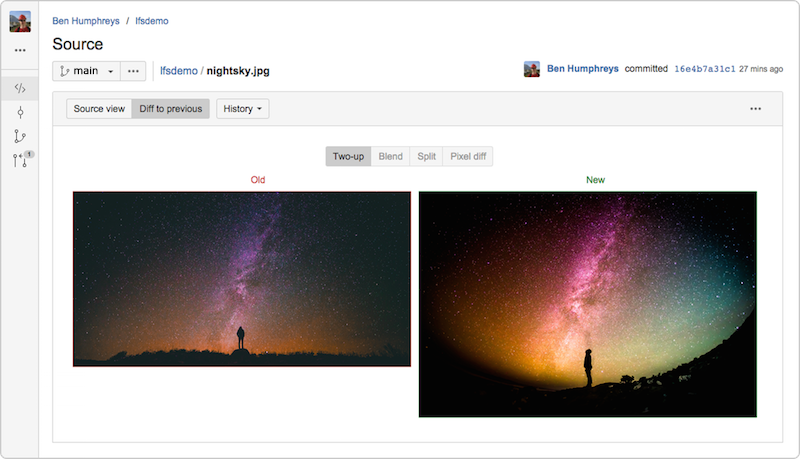
Meu colega Steve Streeting da Atlassian, é um colaborador ativo do projeto LFS e há pouco tempo escreveu sobre o projeto.
Identifique limites e divida o repositório
A solução mais radical é dividir o monorepo em repositórios git menores e mais focados. Tente deixar de rastrear todas as alterações em um único repositório e, em vez disso, identifique os limites dos componentes, talvez identificando módulos ou componentes que tenham um ciclo de lançamento semelhante. Um bom teste decisivo para subcomponentes claros é o uso de marcações no repositório e se elas fazem sentido para outras partes da árvore de origem.
Embora fosse ótimo se o Git suportasse monorepos, o conceito de monorepo está um pouco em desacordo com o que torna o Git bem-sucedido e popular em primeiro lugar. No entanto, isso não significa que você deva desistir dos recursos do Git porque você tem um monorepo - na maioria dos casos, existem soluções viáveis para quaisquer problemas que surjam.
Compartilhar este artigo
Próximo tópico
Leitura recomendada
Marque esses recursos para aprender sobre os tipos de equipes de DevOps ou para obter atualizações contínuas sobre DevOps na Atlassian.

Blog do Bitbucket

Caminho de aprendizagem de DevOps
