Wypróbuj Compass bezpłatnie
Ulepsz środowisko programistyczne, skataloguj wszystkie usługi i popraw kondycję oprogramowania.
Artykuły
Samouczki
Interaktywne przewodniki
Jak stosować DevOps
Przewodnik krok po kroku dla zespołów zainteresowanych wdrożeniem DevOps
.png?cdnVersion=3145)
Warren Marusiak
Starszy propagator techniczny
Twój cykl tworzenia oprogramowania jest plątaniną różnych narzędzi i przepływów pracy? Twoje zespoły i projekty funkcjonują w silosach? Jeśli na jedno z tych pytań odpowiadasz twierdząco, to jest to doskonały moment na zastanowienie się nad wdrożeniem DevOps. DevOps pomaga uprościć i zoptymalizować przepływy pracy związane z rozwojem i wdrażaniem oprogramowania dzięki przygotowaniu nowego ekosystemu tworzenia oprogramowania.
Ale jak wdrożyć DevOps? Jednym z głównych wyzwań związanych z DevOps jest brak standardowego procesu, ponieważ każdy zespół ma inne potrzeby i cele. Sama liczba narzędzi i zasobów DevOps może prowadzić do „paraliżu analitycznego”, który utrudnia wdrożenie. Poniższe kroki pomogą Twojemu zespołowi we wdrożeniu DevOps.
Dlaczego DevOps?
Krótka odpowiedź brzmi: DevOps zwiększa produktywność, pozwalając programistom robić to, co robią najlepiej: tworzyć fantastyczne oprogramowanie, zamiast ręcznie wykonywać prace o niskiej wartości, takie jak manualne sprawdzanie plików dziennika. Praktyki DevOps automatyzują powtarzalne zadania, takie jak uruchamianie testów i wdrożeń, monitorowanie oprogramowania produkcyjnego pod kątem problemów i budowanie odpornej na problemy metodologii wdrażania. Programiści mają swobodę budowania i eksperymentowania, co skutkuje wzrostem produktywności.
Nie ma jednej definicji DevOps. W tym artykule DevOps oznacza, że zespół jest właścicielem całego cyklu życia danej części oprogramowania. Zespół DevOps projektuje, implementuje, wdraża, monitoruje, rozwiązuje problemy i aktualizuje oprogramowanie. Jest właścicielem kodu i infrastruktury, na której działa kod. Odpowiada nie tylko za środowisko użytkownika końcowego, ale także za problemy produkcyjne.
Założeniem DevOps jest stworzenie procesu, który przewiduje problemy i umożliwia programistom skuteczne reagowanie na nie. Proces DevOps powinien zapewnić programistom natychmiastowe informacje zwrotne na temat kondycji systemu po każdym wdrożeniu. Im wcześniej zostanie odkryty problem, tym mniejsze będzie jego oddziaływanie i tym szybciej zespół będzie mógł przejść do następnego etapu prac. Gdy można łatwo wdrożyć zmiany i przywrócić sprawność systemu po problemach, programiści są w stanie eksperymentować, kompilować, wydawać i wypróbowywać nowe pomysły.
Czym nie jest DevOps: technologia. By uznać, że wdrożyliśmy DevOps, nie wystarczy tak po prostu kupić narzędzia DevOps. Istotą DevOps jest rozwijanie kultury wspólnej odpowiedzialności, przejrzystości i szybszego przekazywania informacji zwrotnych. Technologia to tylko narzędzie, które to umożliwia.
materiały pokrewne
Zacznij korzystać za darmo
materiały pokrewne
Dowiedz się więcej na temat najlepszych praktyk DevOps
Kilka uwag
Zważywszy na fakt, że sytuacja wyjściowa każdego zespołu jest inna, część z poniższych kroków może nie mieć zastosowania. Ponadto podana lista nie jest wyczerpująca. Przedstawione tutaj kroki mają stanowić punkt wyjścia, który pomoże zespołowi we wdrożeniu DevOps.
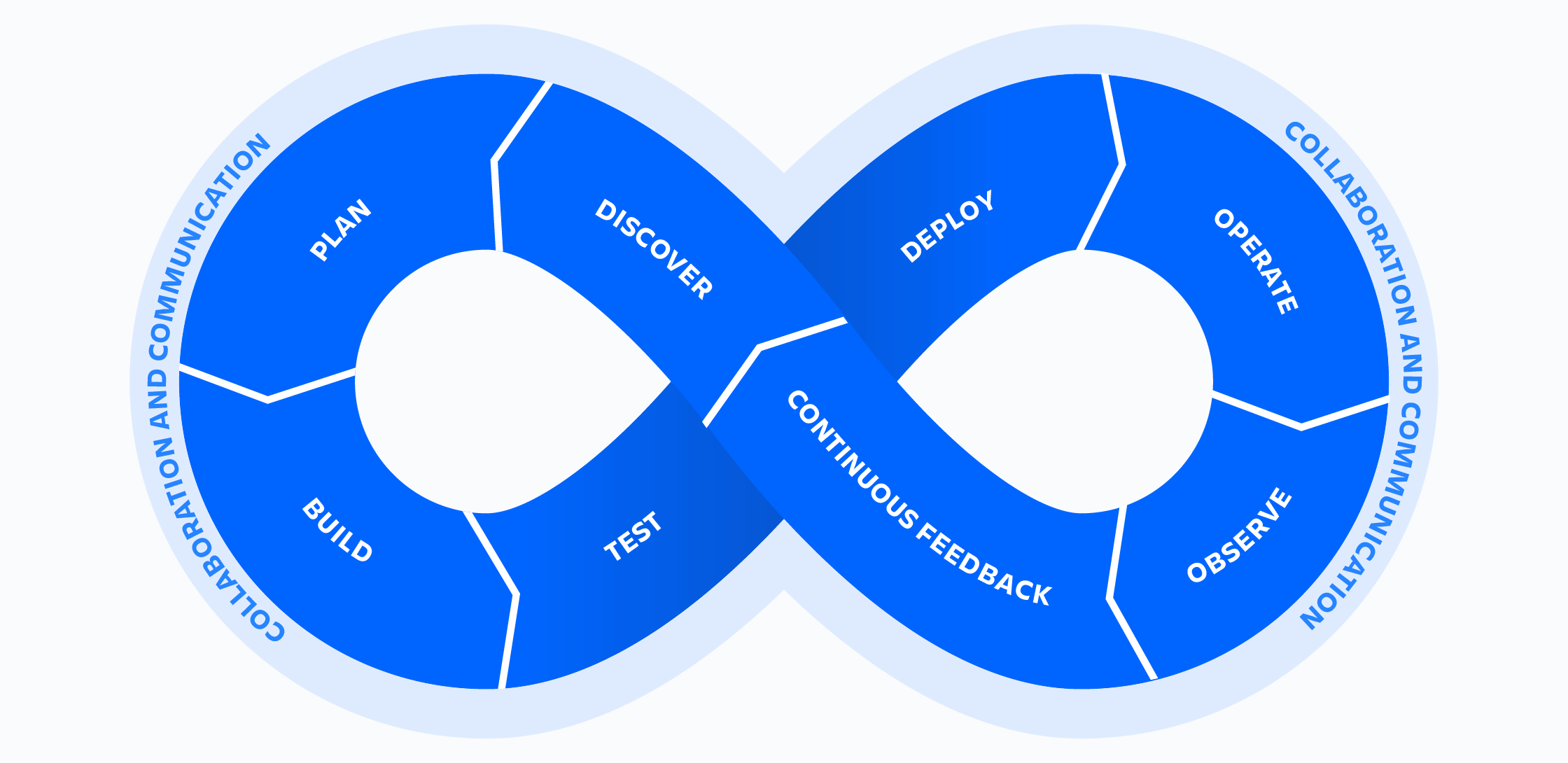
W tym artykule termin DevOps jest używany jako ogólne określenie dotyczące kultury, procesów i technologii, które sprawiają, że DevOps działa.
8 kroków do DevOps
Krok 1 — Wybór komponentu
Pierwszym krokiem jest rozpoczęcie od małej skali. Wybierz komponent, który jest obecnie w fazie produkcji. Idealny komponent ma prostą bazę kodu z niewieloma zależnościami i minimalną infrastrukturą. Komponent ten będzie poligonem doświadczalnym, na którym zespół może przećwiczyć wdrażanie DevOps.
Krok 2 — Przeanalizowanie możliwości zastosowania metodologii Agile takiej jak Scrum
DevOps często stosowane jest w połączeniu z metodologią pracy Agile, taką jak Scrum. Nie ma potrzeby wdrażania wszystkich rytuałów i praktyk związanych z metodą taką jak Scrum. Trzy elementy Scrum, które zasadniczo są łatwe do wdrożenia i szybko dostarczają wartość, to backlog, sprint i planowanie sprintu.
Zespół DevOps może dodawać i nadawać priorytety pracy w backlogu Scrum, a następnie wprowadzać podzbiór tej pracy do sprintu, czyli ustalonego czasu na ukończenie określonej części pracy. Planowanie sprintu polega na decydowaniu o tym, jakie zadania przechodzą z backlogu zaległości do następnego sprintu.
Krok 3 — Użycie kontroli źródła opartego na GIT
Kontrola wersji to najlepsza praktyka DevOps, która umożliwia lepszą współpracę i skrócenie cykli wydawania. Narzędzia takie jak Bitbucket umożliwiają programistom udostępnianie, współpracę, scalanie, korzystanie z polecenia git clone i tworzenie kopii zapasowych oprogramowania.
Wybierz model tworzenia gałęzi. Zarys tej koncepcji przedstawiono w tym artykule. Przepływ GitHub jest doskonałym punktem wyjścia dla zespołów zaczynających pracę z Git, ponieważ łatwo go zrozumieć i wdrożyć. Często preferowanym rozwiązaniem jest tworzenie oprogramowania w oparciu o gałąź główną, ale wymaga ono większej dyscypliny i komplikuje pierwsze kroki z Git.
Krok 4 — Zintegrowanie kontroli źródła ze śledzeniem pracy
Zintegruj narzędzie do kontroli źródła z narzędziem do śledzenia pracy. Dzięki temu że w jednym miejscu można zobaczyć wszystko, co jest związane z danym projektem, programiści i menedżerowie oszczędzą sporo czasu. Poniżej znajduje się przykład zgłoszenia Jira z aktualizacjami z repozytorium kontroli źródła opartego na systemie Git. Zgłoszenia Jira zawierają sekcję programistyczną, w której zebrane są informacje o pracy wykonanej w związku ze zgłoszeniem Jira w kontroli źródła. To zgłoszenie miało jedną gałąź, sześć commitów, jeden pull request i jedną kompilację.
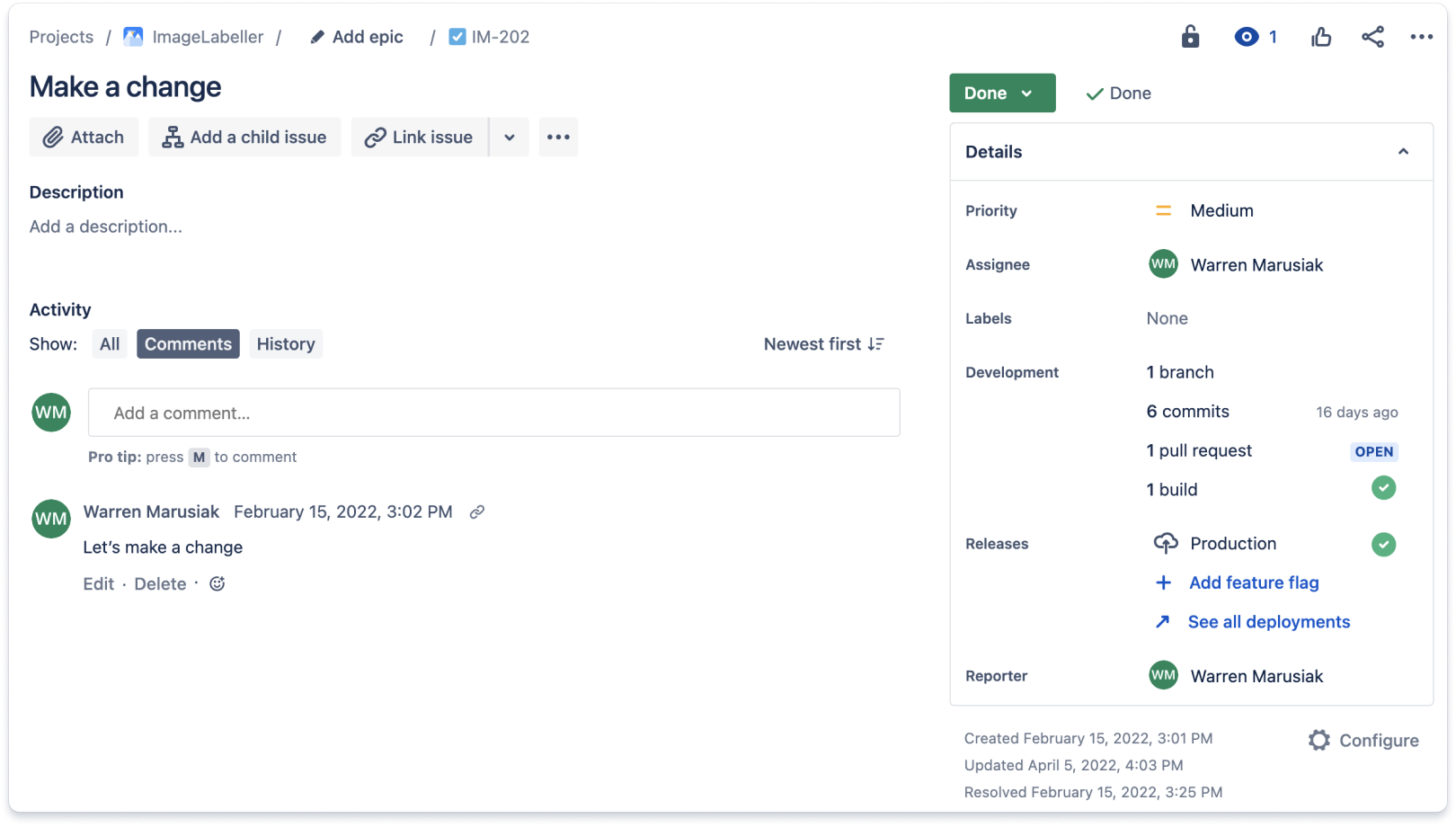
Zagłębiając się w sekcję programistyczną zgłoszenia Jira, można znaleźć dodatkowe szczegóły. Karta commitów zawiera listę wszystkich commitów powiązanych ze zgłoszeniem Jira.
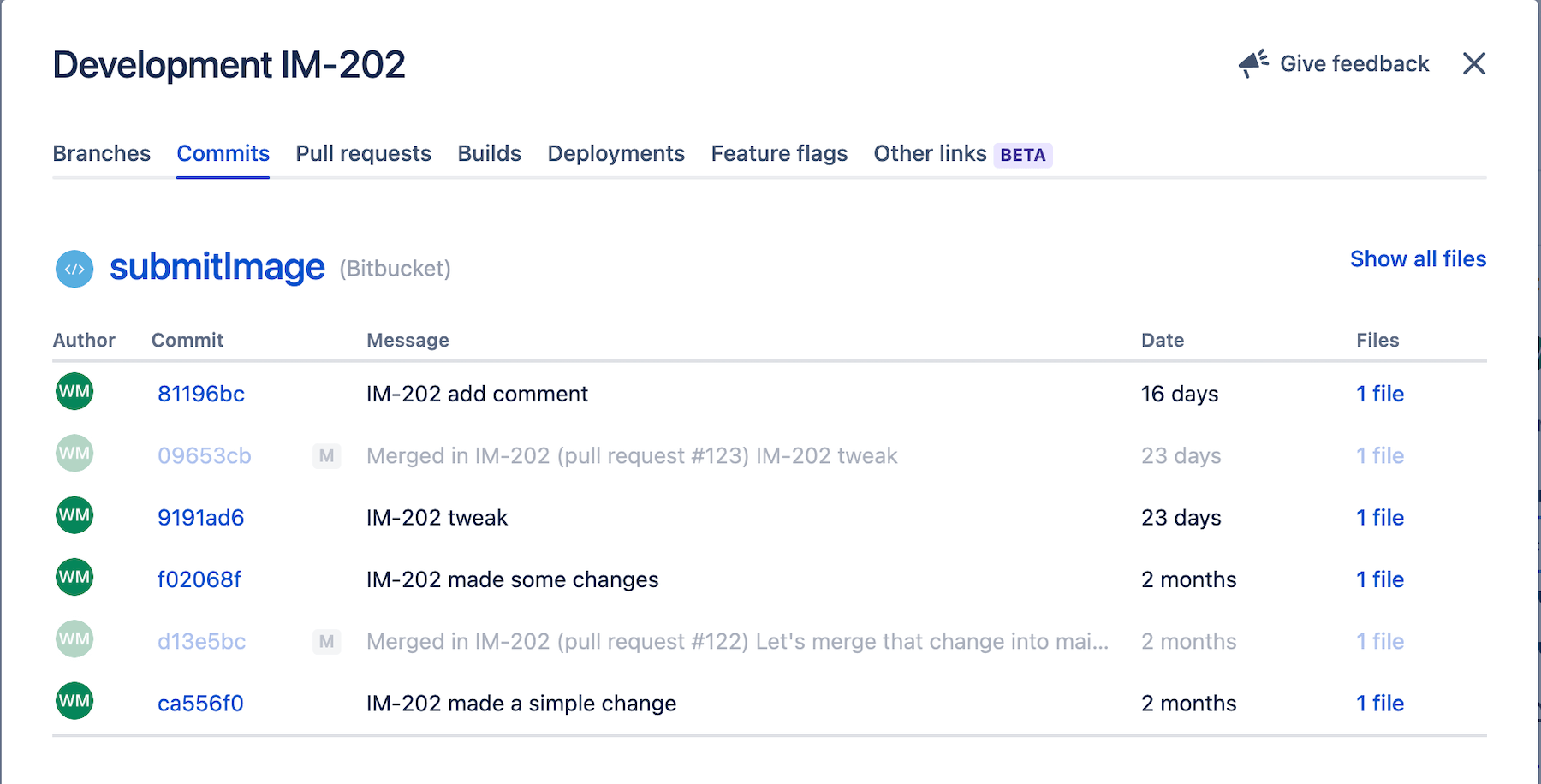
W tej sekcji wymieniono wszystkie pull requesty powiązane ze zgłoszeniem Jira.
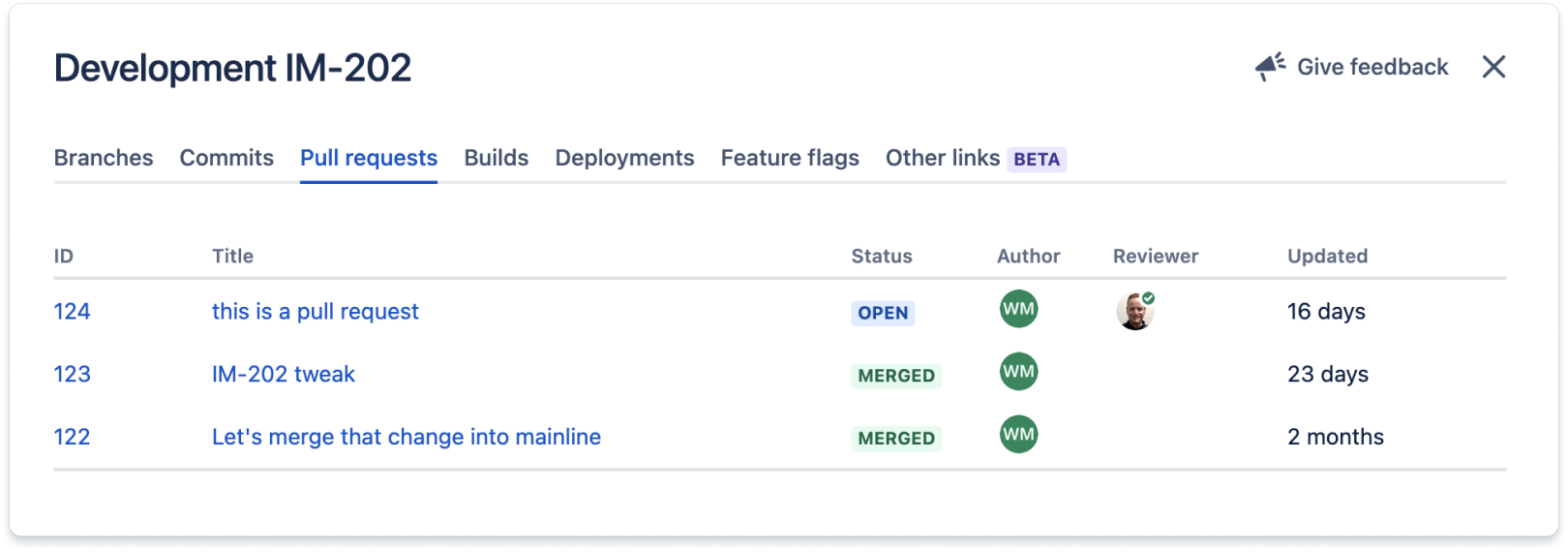
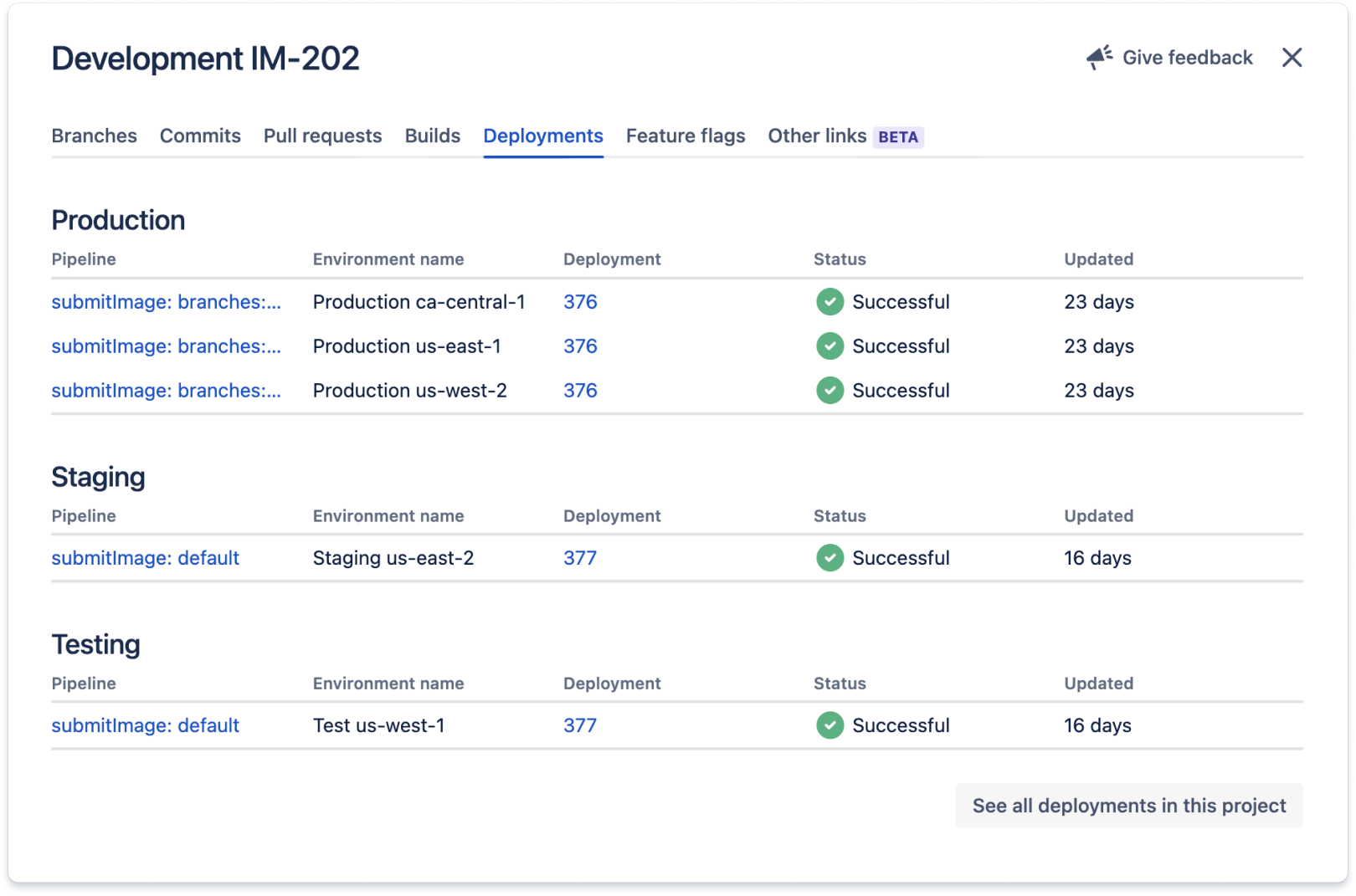
Kod związany z tym zgłoszeniem Jira jest wdrażany we wszystkich środowiskach wymienionych w sekcji Wdrożenia. Integracje te zwykle działają poprzez dodanie identyfikatora zgłoszenia Jira — w tym przypadku IM-202 — w celu zatwierdzenia komunikatów i nazw gałęzi pracy związanej ze zgłoszeniem Jira.
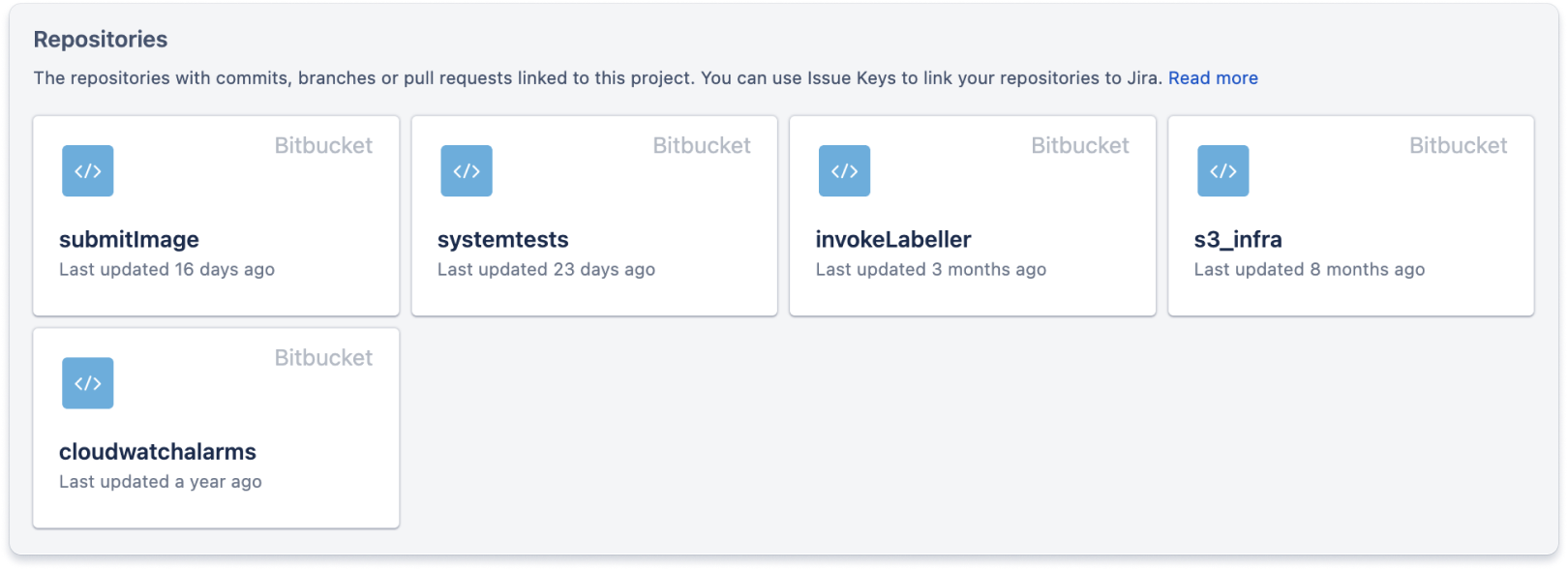
Karta kodu zawiera łącza do wszystkich repozytoriów kontroli źródła związanych z projektem. Pomaga to programistom znaleźć kod, nad którym powinni pracować, gdy przypisują się do zgłoszenia Jira.
Krok 5 — Napisanie testów
Pipeline'y CI/CD wymagają testów, aby sprawdzić, czy kod wdrożony w różnych środowiskach działa poprawnie. Zacznij od napisania testów jednostkowych dla kodu. Ambitnym celem jest 90 procent pokrycia kodu, ale gdy dopiero zaczynasz, jest to nierealne. Wyznacz niski poziom bazowy dla pokrycia kodu i stopniowo z biegiem czasu zwiększaj poprzeczkę dla pokrycia testów jednostkowych. W tym celu możesz dodać jednostki pracy do backlogu.
Stosuj programowanie sterowane testami podczas naprawiania błędów znalezionych w kodzie produkcyjnym. Kiedy znajdziesz błąd, napisz testy jednostkowe, testy integracyjne i/lub systemowe, które kończą się niepowodzeniem w środowiskach, w których ten błąd występuje. Następnie napraw błąd i zobacz, czy testy kończą się teraz powodzeniem. Ten proces w sposób naturalny pozwoli z czasem zwiększyć pokrycie kodu. Jeśli błąd został wychwycony w środowisku testowym lub przejściowym, testy dadzą Ci pewność, że kod działa poprawnie, gdy zostanie przeniesiony do produkcji.
Gdy zaczynasz od początku, ten krok jest co prawda pracochłonny, ale ważny. Testowanie pozwala zespołom zobaczyć wpływ zmian kodu na zachowanie systemu przed wdrożeniem tych zmian u użytkowników końcowych.
Testy jednostkowe
Testy jednostkowe sprawdzają, czy kod źródłowy jest poprawny i powinien być uruchamiany jako jeden z pierwszych kroków w pipelinie CI/CD. Deweloperzy powinni napisać testy dla zielonej ścieżki, problematycznych wejść i znanych przypadków narożnych. Podczas pisania testów programiści mogą symulować dane wyjściowe i oczekiwane dane wyjściowe.
Testy integracyjne
Testy integracyjne pozwalają na sprawdzenie, czy dwa komponenty komunikują się ze sobą poprawnie. Można symulować dane wyjściowe i oczekiwane dane wyjściowe. Testy te są jednym z pierwszych kroków pipeline'u CI/CD przed wdrożeniem w dowolnym środowisku. Testy te zazwyczaj wymagają szerzej zakrojonych symulacji niż testy jednostkowe.
Testy systemowe
Testy systemowe sprawdzają kompleksową wydajność systemu i dają pewność, że system działa zgodnie z oczekiwaniami w każdym środowisku. Symuluj dane wejściowe, które może otrzymać komponent, i uruchom system. Następnie sprawdź, czy system zwraca wymagane wartości i poprawnie aktualizuje pozostałą część systemu. Testy te powinny być uruchamiane po wdrożeniu w każdym środowisku.
Krok 6 — Tworzenie procesu CI/CD w celu wdrożenia komponentu
Podczas tworzenia pipeline'u CI/CD rozważ przeprowadzenie wdrożenia w wielu środowiskach. Kod zostanie zapisany na stałe, jeśli zespół buduje pipeline CI/CD, który jest wdrażany tylko do jednego środowiska. Ważne jest tworzenie pipeline'ów CI/CD dla infrastruktury i kodu. Zacznij od stworzenia pipeline'u CI/CD, aby wdrożyć niezbędną infrastrukturę w każdym środowisku. Następnie stwórz kolejny pipeline CI/CD, aby wdrożyć kod.
Struktura pipeline'u
Ten pipeline zaczyna się od uruchomienia testów jednostkowych i testów integracyjnych przed wdrożeniem w środowisku testowym. Testy systemowe są wykonywane po wdrożeniu w środowisku.
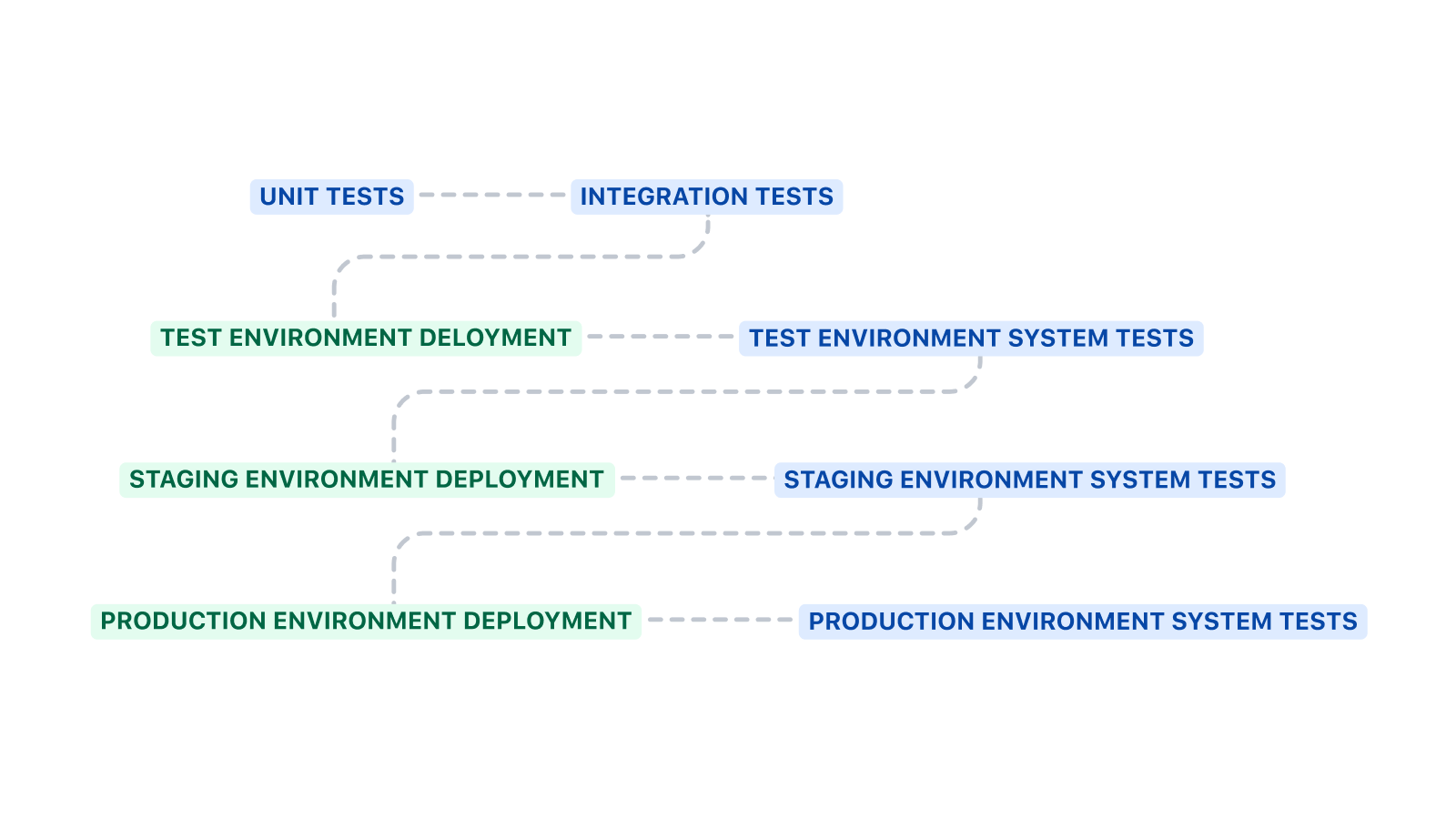
Powyższy wstępny szablon można rozbudować na kilka sposobów. Linting kodu, analiza statyczna i skanowanie bezpieczeństwa to sprawdzone dodatkowe kroki, które należy dodać przed testami jednostkowymi i integracyjnymi. Linting kodu pozwala wymusić standardy kodowania, analiza statyczna umożliwia sprawdzenie antywzorców, a skanowanie bezpieczeństwa może wykryć obecność znanych luk w zabezpieczeniach.
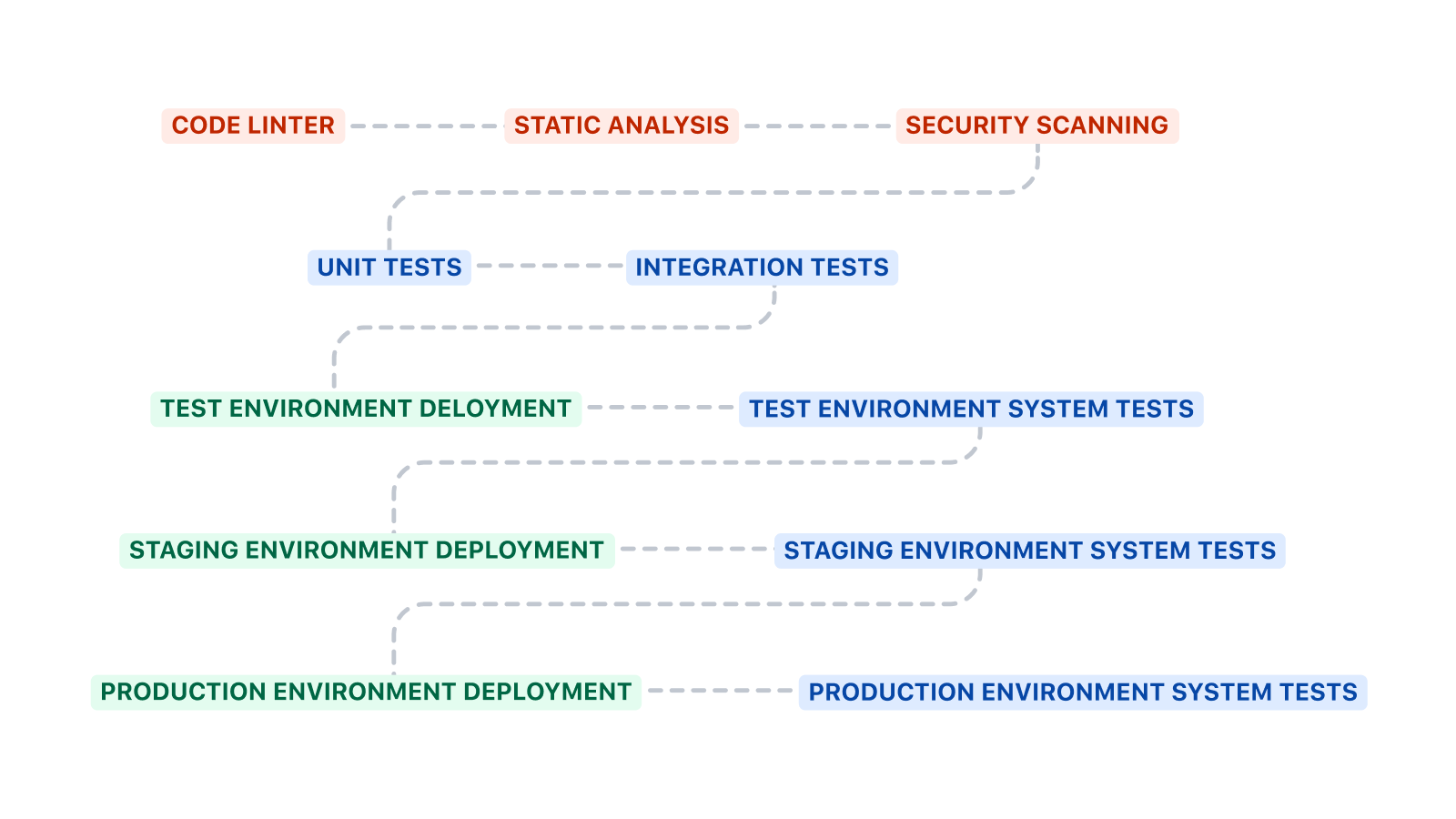
Pipeline'y CI/CD do wdrażania infrastruktury i kodu najpewniej różnią się od siebie. Pipeline CI/CD dla infrastruktury często nie posiada testów jednostkowych lub integracyjnych. Będzie uruchamiać testy systemu po każdym wdrożeniu, dzięki czemu można się upewnić, że system nie przestał działać.
Infrastruktura
Różnice w infrastrukturze w poszczególnych środowiskach utrudniają poprawne uruchamianie oprogramowania działającego w danym środowisku. Aby oprogramowanie działało poprawnie, reguły zapory, uprawnienia użytkowników, dostęp do bazy danych i inne komponenty na poziomie infrastruktury muszą znajdować się w znanej konfiguracji. Ręczne wdrażanie infrastruktury może być trudno powtórzyć w sposób prawidłowy. Ponieważ proces ten obejmuje wiele kroków, konieczność pamiętania o wykonaniu każdego z nich w odpowiedniej kolejności, z właściwymi parametrami, może prowadzić do błędów. Aby ograniczyć te i inne problemy, trzeba w miarę możliwości zdefiniować infrastrukturę w kodzie.
Do zdefiniowania infrastruktury w kodzie można wykorzystać szereg narzędzi, w tym AWS CloudFormation, Terraform, Ansible, Puppet czy Chef.
Napisz kilka pipeline'ów, aby wdrożyć infrastrukturę. Tak jak w przypadku pisania kodu, warto, aby wdrażanie infrastruktury było modułowe. Tam, gdzie to możliwe, należy podzielić wymaganą infrastrukturę na osobne podzbiory. Załóżmy, że A, B, C i D są abstrakcjami dla komponentów infrastruktury, które mogą zależeć od siebie nawzajem. Na przykład A może być pudełkiem EC2, a B może być zasobnikiem S3. Zależności, w których komponent infrastruktury A — i tylko A — zależy od komponentu B, prawdopodobnie powinny być przechowywane razem w tym samym pipelinie CI/CD. Zależności, w których A, B i C zależą od D — ale A, B i C są niezależne — powinny być podzielone na wiele pipeline'ów CI/CD. W tym przypadku są to cztery niezależne pipeline'y. Należy zbudować jeden pipeline dla D, od którego zależą wszystkie trzy pozostałe komponenty, i po jednym dla każdego: A, B oraz C.
Kod
Pipeline'y CI/CD są tworzone w celu wdrożenia kodu. Są one zwykle łatwe do wdrożenia, ponieważ infrastruktura jest już dostępna ze względu na wcześniej wykonane prace. Istotnymi kwestiami są tu testowanie, powtarzalność i możliwość odzyskania sprawności po nieprawidłowych wdrożeniach.
Powtarzalność oznacza zdolność do ponownego wdrożenia tej samej zmiany bez szkody dla systemu. Wdrożenie powinno być wielobieżne i idempotentne. Wdrożenie powinno uwzględniać stan systemu ze znaną konfiguracją zamiast stosować modyfikator do istniejącego stanu. Stosowanie modyfikatora nie może zostać powtórzone, ponieważ po pierwszym wdrożeniu zmienił się stan początkowy wymagany do prawidłowego działania tego modyfikatora.
Prostym przykładem niepowtarzalnej aktualizacji jest aktualizacja pliku konfiguracyjnego poprzez dołączenie do niego danych. Nie dołączaj wierszy do plików konfiguracyjnych ani nie używaj żadnej techniki modyfikacji tego rodzaju. Jeśli aktualizacje są wykonywane za pomocą operacji dołączenia, w pliku konfiguracyjnym mogą znaleźć się dziesiątki zduplikowanych wierszy. Zamiast tego zastąp plik konfiguracyjny poprawnie napisanym plikiem z kontroli źródła.
Zasadę tę należy stosować także przy aktualizacji baz danych. Aktualizacje baz danych bywają skomplikowane i wymagają dbałości o szczegóły. Ważne jest, aby proces aktualizacji bazy danych był powtarzalny i odporny na błędy. Bezpośrednio przed zastosowaniem zmian należy wykonać kopie zapasowe danych, aby możliwe było ich odzyskanie.
Kolejną kwestią jest odzyskiwanie po nieprawidłowym wdrożeniu. Może się zdarzyć, że wdrożenie się nie powiedzie i system jest w nieznanym stanie, albo wdrożenie się powiedzie, alarmy są uruchamiane i zaczynają napływać zgłoszenia problemów. Istnieją dwa ogólne sposoby na poradzenie sobie z tym problemem. Pierwszym z nich polega na wykonaniu wycofania. Drugi wiąże się natomiast z użyciem flag funkcji i wyłączeniem niezbędnych flag, aby powrócić do znanego prawidłowego stanu. W kroku 8 tego artykułu podajemy więcej informacji na temat flag funkcji.
Wycofanie wdraża znany wcześniej prawidłowy stan w środowisku po wykryciu nieprawidłowego wdrożenia. Należy je zaplanować już na początku. Przed zmodyfikowaniem bazy danych trzeba wykonać kopię zapasową. Upewnij się, że jesteś w stanie szybko wdrożyć poprzednią wersję kodu. Regularnie testuj proces wycofywania w środowiskach testowych lub przejściowych.
Krok 7 — Dodawanie monitorowania, alarmów i oprzyrządowania
Zespół DevOps musi monitorować zachowanie uruchomionej aplikacji w każdym środowisku. Czy są błędy w dziennikach? Czy czas połączeń z interfejsami API został przekroczony? Czy bazy danych ulegają awarii? Należy monitorować każdy komponent systemu pod kątem problemów. Jeśli w wyniku monitorowania zostanie wykryty problem, trzeba utworzyć zgłoszenie usterki, aby ktoś mógł rozwiązać problem. W ramach rozwiązania warto napisać dodatkowe testy, które mogą wyłapać problem.
Naprawianie błędów
Monitorowanie i reagowanie na problemy jest elementem pracy nad oprogramowaniem w środowisku produkcyjnym. Zespół kierujący się kulturą DevOps odpowiada za eksploatację oprogramowania i inspiruje się zachowaniem inżyniera ds. niezawodności witryn internetowych (site reliability engineer — SRE). Przeprowadź analizę przyczyn problemu, napisz testy w celu wykrycia problemu, napraw go i sprawdź, czy testy kończą się teraz powodzeniem. Proces ten jest często pracochłonny na początku, ale opłaca się w dłuższej perspektywie, ponieważ pozwala zmniejszyć dług techniczny i utrzymać zwinność operacyjną.
Optymalizacja wydajności
Po wprowadzeniu podstawowego monitorowania kondycji częstym kolejnym krokiem jest dostosowywanie wydajności. Trzeba przyjrzeć się, jak działa każdy komponent systemu, i zoptymalizować zbyt wolno działające elementy. Jak zauważył Knuth: „przedwczesna optymalizacja jest źródłem wszelkiego zła”. Nie należy optymalizować wydajności wszystkiego w systemie. Optymalizacji powinny podlegać tylko najwolniejsze, najbardziej kosztowne elementy. Monitorowanie pomaga określić, które komponenty są wolne i kosztowne.
Krok 8 — Użycie flag funkcji do wdrożenia „testów kanarka”
Aby włączyć „testy kanarka”, zawiń każdą nową funkcję we flagę funkcji z listą dozwolonych użytkowników testowych. Nowy kod funkcji będzie działał tylko dla użytkowników z listy dozwolonych po wdrożeniu do środowiska. Poczekaj, aż nowa funkcja zostanie przyswojona w każdym środowisku, zanim przeniesiesz ją do następnego. W tym czasie przyjrzyj się wskaźnikom, alarmom i innemu oprzyrządowaniu w poszukiwaniu oznak problemów. W szczególności zwróć uwagę na wzrost liczby nowych zgłoszeń usterek.
Zajmij się problemami w danym środowisku przed przekazaniem ich do następnego środowiska. Do problemów znalezionych w środowiskach produkcyjnych należy podchodzić tak samo jak do problemów w środowiskach testowych czy przejściowych. Po zidentyfikowaniu głównej przyczyny problemu napisz testy, aby zidentyfikować problem, wdrożyć poprawkę, sprawdzić, czy testy kończą się powodzeniem, i przekazać poprawkę za pośrednictwem pipeline'u CI/CD. Nowe testy będą kończyć się pomyślnie, a liczba zgłoszeń problemów spadnie, podczas gdy zmiana zostanie osadzona w środowisku, w którym wykryto problem.
Podsumowując…
Przeprowadź retrospektywę projektu w kontekście przeniesienia pierwszego komponentu do DevOps. Zidentyfikuj słabe punkty, czyli problematyczne lub stanowiące wyzwanie elementy. Rozbuduj plan naprawy tych słabych punktów, a następnie przejdź do drugiego komponentu.
Początkowo może się wydawać, że zastosowanie podejścia DevOps, aby przenieść komponent do produkcji, wiąże się z dużym nakładem pracy, jednak takie podejście przynosi korzyści w dłuższej perspektywie. Wdrożenie drugiego elementu powinno być łatwiejsze po przygotowaniu dla niego gruntu. Proces zastosowany do pierwszego elementu może zostać wykorzystany i nieznacznie zmodyfikowany na potrzeby drugiego elementu z uwagi na to, że narzędzia są już dostępne, technologie są zrozumiałe, a zespół jest przeszkolony do pracy w stylu DevOps.
Aby rozpocząć korzystanie z DevOps, zalecamy wypróbowanie Atlassian Open DevOps, zintegrowanego i otwartego łańcucha narzędzi, który zawiera wszystko, co potrzebne do tworzenia i obsługi oprogramowania, a także pozwalające na integrację dodatkowych narzędzi w miarę pojawiania się zwiększonych potrzeb.

Udostępnij ten artykuł
Następny temat
Zalecane lektury
Dodaj te zasoby do zakładek, aby dowiedzieć się więcej na temat rodzajów zespołów DevOps lub otrzymywać aktualności na temat metodyki DevOps w Atlassian.

Społeczność DevOps

Ścieżka szkoleniowa DevOps