Gestione degli imprevisti per i team high velocity
Come scegliere i KPI e le metriche per la gestione degli imprevisti
Monitoraggio e miglioramento della gestione degli imprevisti nel corso del tempo
Nel mondo sempre attivo di oggi, gli imprevisti tecnologici hanno conseguenze importanti.
Per le aziende, il tempo di inattività dei sistemi ha un costo medio di 300.000 dollari all'ora in termini di mancate entrate, produttività dei dipendenti e costi di manutenzione. Le interruzioni gravi possono superare di gran lunga tali costi (ne sa qualcosa Delta Airlines, che ha perso circa 150 milioni di dollari a seguito di un'interruzione dell'IT avvenuta nel 2017). I clienti che non possono pagare le bollette, partecipare a una videoconferenza per una riunione importante o acquistare un biglietto aereo non ci pensano due volte a passare a un'azienda concorrente per la propria attività.
Con una posta in gioco così alta, per i team è più importante che mai tenere traccia dei KPI di gestione degli imprevisti e utilizzare i risultati per rilevare, diagnosticare, correggere e, in ultima analisi, prevenire gli imprevisti.
La buona notizia è che, a differenza dei sistemi meccanici e offline, gli imprevisti Web e software di solito consentono ai team di acquisire molti più dati utili per comprendere gli eventi e apportare miglioramenti.
La brutta notizia è che a volte un'eccessiva quantità di dati può nascondere i problemi invece di portarli alla luce.
Il valore di KPI, metriche e analisi degli imprevisti
I KPI (Key Performance Indicator) sono metriche che aiutano le aziende a capire se stanno raggiungendo obiettivi specifici. Per la gestione degli imprevisti, queste metriche possono essere il numero di imprevisti, il tempo medio di risoluzione o il tempo medio tra un imprevisto e quello successivo.
Il monitoraggio dei KPI per la gestione degli imprevisti può aiutare a identificare e diagnosticare problemi riguardanti processi e sistemi, stabilire parametri di riferimento e obiettivi realistici su cui il team può lavorare e fornire un punto di partenza per domande più ampie.
Ad esempio, supponiamo che l'azienda abbia l'obiettivo di risolvere tutti gli imprevisti entro 30 minuti, ma il tuo team ha attualmente una media di 45 minuti. In assenza di metriche specifiche, è difficile sapere dove risiedono i problemi. Il sistema di avvisi impiega troppo tempo? Il processo subisce interruzioni? Gli strumenti diagnostici devono essere aggiornati? Si tratta di un problema di team o tecnico?
Ora aggiungi alcune metriche: se conosci con esattezza il tempo impiegato dal sistema di avvisi, puoi identificarlo come problema o escluderlo. Se noti che la diagnostica richiede più del 50% del tempo, puoi concentrare la risoluzione dei problemi su questo aspetto. Se vedi che il team B impiega il 25% di tempo in più rispetto ai team A, C e D, puoi iniziare ad approfondire i motivi.
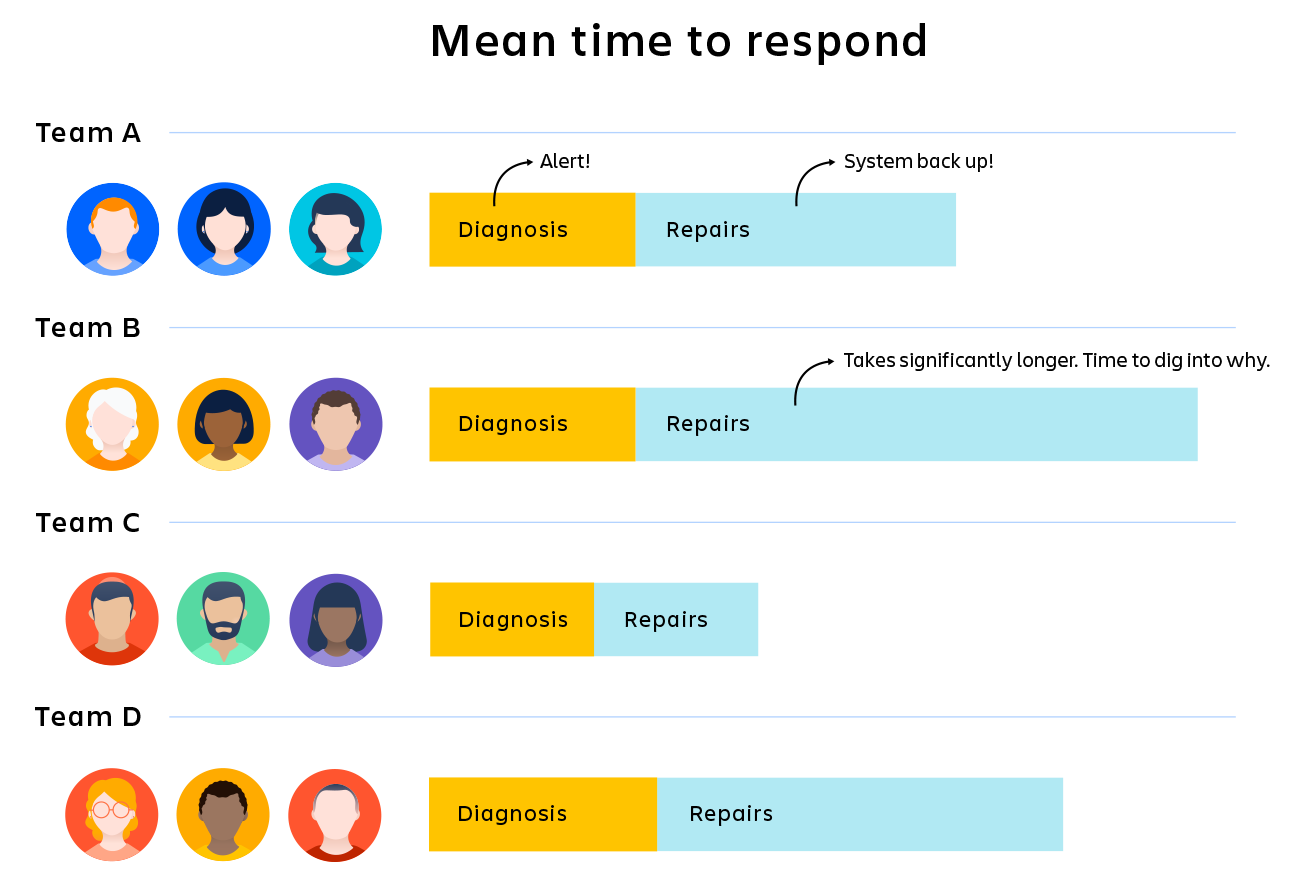
I KPI non correggono automaticamente i problemi, ma aiutano a capire dove risiede il problema e a concentrare le energie sugli approfondimenti giusti.
KPI e metriche degli imprevisti più diffusi
Avvisi creati
Se utilizzi uno strumento di avvisi, è utile sapere quanti avvisi vengono generati in un determinato periodo di tempo. Utilizzando una soluzione come Jira Service Management, puoi sia inviare avvisi sia attivare report e dashboard per monitorarli.
Monitora i periodi con riduzioni o aumenti significativi e insoliti o numeri che tendono verso l'alto e, quando li vedi, approfondisci il motivo per cui si stanno verificando questi cambiamenti e in che modo i tuoi team li stanno affrontando.
Imprevisti nel corso del tempo
Tenere traccia degli imprevisti nel corso del tempo significa esaminarne il numero medio a livello settimanale, mensile, trimestrale, annuale o persino giornaliero.
Gli imprevisti si verificano con una frequenza maggiore o minore nel corso del tempo? Il numero di imprevisti è accettabile o potrebbe essere inferiore? Una volta identificato un problema relativo al numero di imprevisti, puoi iniziare a porre domande sui motivi per i quali quel numero è in aumento o rimane elevato e su quali azioni il team possa intraprendere per risolvere il problema.
MTBF
L'MTBF (tempo medio tra guasti) è il tempo medio tra i guasti riparabili di un prodotto tecnologico. Può aiutarti a monitorare la disponibilità e l'affidabilità dei prodotti.
Come per altre metriche, è un buon punto di partenza per domande più ampie. Se l'MTBF è inferiore a quello desiderato, è arrivato il momento di chiedersi perché i sistemi sono soggetti a guasti così frequenti e in che modo puoi ridurli o evitare che si verifichino in futuro.
MATTA
L'MTTA (tempo medio di riconoscimento) è il tempo medio che intercorre dal momento in cui si attiva un avviso di sistema a quando un membro del team prende atto dell'imprevisto e inizia a lavorarci per risolverlo.. Il valore di questa metrica risiede nella possibilità di comprendere in che misura il tuo team è reattivo riguardo alla risoluzione dei problemi.
Se sai che è presente un problema di reattività, puoi ricominciare ad analizzarlo più a fondo. Perché l'MTTA è alto? I team sono oberati di lavoro? Sono distratti da altro? La responsabilità di un avviso non è chiara? L'MTTA può aiutarti a identificare un problema e domande come queste sono utili per comprenderlo a fondo.
MTTD
L'MTTD (tempo medio di rilevamento) è il tempo medio impiegato dal team per scoprire un problema. Il termine è spesso utilizzato nell'ambito della sicurezza informatica quando i team sono concentrati sul rilevamento di attacchi e violazioni.
Se questa metrica cambia drasticamente, o non raggiunge l'obiettivo, anche in questo caso è opportuno chiedersi perché.
MTTR
L'MTTR può rappresentare il tempo medio di riparazione, risoluzione, risposta o ripristino. Probabilmente, di queste metriche quella più utile è il tempo medio di risoluzione, che monitora non solo il tempo impiegato per diagnosticare e risolvere un problema immediato, ma anche il tempo impiegato per garantire che non si verifichi di nuovo. Il ripristino è una metrica DevOps principale che DevOps Research and Assessment (DORA) indica come fondamentale per misurare la stabilità di un team DevOps.
È utile ribadire che questa metrica offre risultati ottimali se utilizzata a fini diagnostici. I tuoi tempi di risoluzione sono rapidi ed efficienti come vorresti che fossero? In caso contrario, è il momento di farsi domande più approfondite su come e perché non centrino il bersaglio.
Il ripristino è una metrica DevOps chiave che può essere utilizzata per misurare la stabilità di un team DevOps, come osservato da DevOps Research and Assessment (DORA). È il tempo totale necessario per rilevare, ridurre e risolvere un problema.
Tempo su chiamata
Se è presente una rotazione su chiamata, può essere utile tenere traccia del tempo che dipendenti e collaboratori esterni dedicano alle chiamate. Questa metrica può aiutarti ad assicurarti che nessun dipendente o team sia oberato di lavoro.
In uno strumento come Jira Service Management, puoi generare report completi per vedere questi dati a colpo d'occhio.
SLA
Uno SLA (accordo sui livelli di servizio) è un accordo tra fornitore e cliente su metriche misurabili come tempo di attività, reattività e responsabilità.
Le promesse fatte negli SLA (riguardanti il tempo di attività, il tempo medio di ripristino e così via) sono uno dei motivi per cui è importante che i team IT monitorino queste metriche. Nell'eventualità in cui ci siano delle modifiche in metriche come il tempo medio di risposta o il tempo medio tra guasti, è necessario aggiornare gli accordi e/o apportare correzioni, in tempi rapidi.
SLO
Uno SLO (obiettivo di livelli di servizio) è un accordo all'interno di uno SLA relativo a una metrica specifica come il tempo di attività. Come per lo SLA stesso, gli SLO sono metriche importanti da monitorare per assicurarsi che l'azienda rispetti la sua parte dell'accordo in fatto di servizio clienti.
Timestamp (o timeline)
Un timestamp è un'informazione codificata su ciò che è accaduto in momenti specifici durante, prima o dopo l'imprevisto. Queste informazioni non sono generalmente considerate una metrica, ma sono dati importanti da avere a disposizione per valutare lo stato della gestione degli imprevisti ed elaborare strategie di miglioramento.
I timestamp aiutano i team a creare le timeline dell'imprevisto, insieme alle attività di gestione e risposta. Una timeline chiara e condivisa è uno degli artefatti più utili durante un'analisi retrospettiva dell'imprevisto.
Tempo di attività
Il tempo di attività indica la quantità di tempo (rappresentata in percentuale) durante la quale i sistemi sono disponibili e funzionanti.
A causa della crescente connettività dei servizi online e della crescente complessità dei sistemi stessi, in genere non esiste un tempo di attività garantito del 100%. Per la maggior parte dei prodotti l'obiettivo è la disponibilità elevata, cioè la presenza di un sistema o di un prodotto che funzioni senza interruzioni per lunghi periodi di tempo. Secondo lo standard di settore, il 99,9% di operatività è un valore ottimo e il 99,99% è eccellente.
Monitorare il successo in base a questa metrica serve a mantenere le promesse fatte ai clienti. Inoltre, come per altre metriche, è solo un punto di partenza. Se il tempo di attività non è del 99,99%, la domanda sui motivi richiederà ulteriori ricerche, conversazioni con il tuo team e indagini sul processo, la struttura, l'accesso o la tecnologia.
Un'avvertenza sull'analisi degli imprevisti
Per contro, i KPI presentano l'aspetto negativo di creare una facile dipendenza da dati poco approfonditi. Sapere che il tuo team non sta risolvendo gli imprevisti a una velocità sufficiente non porta di per sé a una correzione, perché bisogna comunque capire come e perché il team sta risolvendo o meno i problemi e anche se i problemi confrontati sono effettivamente comparabili.
I KPI non sono in grado di fornire informazioni sul modo in cui i team affrontano problemi complicati, non riescono a spiegare perché il tempo tra un imprevisto e quello successivo si sia ridotto invece che allungato, non forniscono indicazioni sui motivi per cui l'Imprevisto A è durato il triplo dell'Imprevisto B.
Per ottenere questi dati, serve un approfondimento. I dati, oltre a essere un punto di partenza per tali approfondimenti, possono anche essere un ostacolo perché ci inducono a pensare che ci stiamo impegnando a sufficienza anche se le metriche non migliorano, a raggruppare imprevisti che in realtà sono estremamente diversi e dovrebbero essere gestiti in modo diverso, a non tenere conto dell'esperienza dei team e delle complicazioni sottostanti agli imprevisti stessi.
"Gli imprevisti sono molto più unici di quanto il senso comune vorrebbe far credere. Due imprevisti della stessa durata possono presentare livelli di sorpresa e incertezza notevolmente diversi nel modo in cui le persone sono arrivate a capire cosa stesse succedendo. Possono anche contenere rischi molto diversi con riferimento all'adozione di azioni volte a mitigare o migliorare la situazione. Gli imprevisti non sono widget che vengono prodotti, in cui una variazione limitata nelle dimensioni fisiche è considerata un indicatore chiave di qualità."
- John Allspaw, Moving Past Shallow Incident Data
I KPI non sono in sé negativi. Non pensiamo che si debba buttare via il bambino con l'acqua sporca. Il punto è che i KPI non sono sufficienti. Sono un punto di partenza, uno strumento diagnostico, il primo passo verso un percorso più complesso che porta a un autentico miglioramento.
Jira Service Management offre funzioni di reporting che consentono al tuo team di tenere traccia dei KPI e di monitorare e ottimizzare la tua pratica di gestione degli imprevisti.
Configurare una On-call Schedule con Opsgenie
In questo tutorial imparerai come configurare una On-call Schedule, applicare le regole di sostituzione, configurare le notifiche su chiamata e molto altro, il tutto in Opsgenie.
Segui il tutorialModelli ed esempi di comunicazione degli imprevisti
Quando si risponde a un imprevisto, i modelli di comunicazione hanno un valore inestimabile. Scopri i modelli utilizzati dai nostri team e altri esempi di imprevisti comuni.
Leggi l'articolo