Prova Compass gratis
Migliora la tua esperienza di sviluppatore, cataloga tutti i servizi e aumenta l'integrità del software.
Articoli
Tutorial
Guide interattive
Come implementare DevOps
Una guida dettagliata per i team che vogliono implementare DevOps
.png?cdnVersion=2658)
Warren Marusiak
Senior Technical Evangelist
Il tuo ciclo di vita di sviluppo del software è un ammasso confuso di strumenti e flussi di lavoro? I tuoi team e progetti sono isolati? Se hai risposto di sì a una di queste domande, è il momento giusto per prendere il considerazione DevOps. DevOps ti aiuta a semplificare e ottimizzare i flussi di lavoro di sviluppo e distribuzione creando un nuovo ecosistema di sviluppo del software.
Ma come si implementa DevOps? Una delle sfide principali di DevOps è che non esiste un processo standard, poiché ogni team ha necessità e obiettivi diversi. L'enorme numero di strumenti e risorse DevOps può portare a una "paralisi delle analisi" che ne frena l'adozione. I passaggi descritti di seguito possono aiutare il tuo team a implementare DevOps.
Perché DevOps?
In breve, la risposta è che DevOps aumenta la produttività consentendo agli sviluppatori di fare ciò che gli riesce meglio: compilare software fantastici anziché eseguire attività manuali a basso valore come la verifica manuale dei file di log. Le pratiche DevOps automatizzano il lavoro ripetitivo come l'esecuzione di test e distribuzioni, il monitoraggio del software di produzione per il rilevamento di problemi e la creazione di una metodologia di distribuzione in grado di superare i problemi. Gli sviluppatori hanno la possibilità di compilare e sperimentare, ottenendo quindi una maggiore produttività.
Il termine DevOps ha diverse definizioni. In questo articolo DevOps significa che un team è responsabile dell'intero ciclo di vita del software. I team DevOps progettano, implementano, distribuiscono, monitorano, correggono i problemi e aggiornano il software. Sono responsabili del codice e dell'infrastruttura su cui questo viene eseguito. Non sono responsabili soltanto dell'esperienza dell'utente finale, ma anche dei problemi di produzione.
Uno dei principi di DevOps è creare un processo in grado di prevedere i problemi e di consentire agli sviluppatori di affrontarli in modo efficiente. Il processo DevOps deve fornire agli sviluppatori un feedback immediato sullo stato di integrità del sistema in seguito a ogni distribuzione. Più vicino alla sua insorgenza viene rilevato un problema, minore è il suo impatto e prima il team può passare alla porzione di lavoro successiva. Gli sviluppatori possono sperimentare, compilare, rilasciare e provare nuove idee se è più semplice distribuire le modifiche e risolvere i problemi.
Cosa non è DevOps: tecnologia. Se acquisti strumenti DevOps, ma li scambi per la metodologia vera e propria, stai mettendo il carro davanti ai buoi. L'essenza di DevOps è costruire una cultura di responsabilità condivisa, trasparenza e feedback più rapidi. La tecnologia è semplicemente uno strumento che lo rende possibile.
materiale correlato
Inizia gratis
materiale correlato
Scopri le best practice DevOps
Nota importante
Dal momento che il punto di partenza di ogni team è diverso, alcuni dei passaggi seguenti potrebbero non essere validi per tutti. Inoltre, questo elenco non è esaustivo. I passaggi illustrati qui sono da intendersi come punto di partenza per aiutare i team a implementare DevOps.
In questo articolo DevOps è utilizzato come termine generico per indicare la cultura, i processi e le tecnologie alla base del suo funzionamento.
8 passaggi per implementare DevOps
Passaggio 1: Scegli un componente
Come primo passaggio, inizia a piccoli passi. Scegli un componente attualmente in produzione. L'ideale sarebbe un componente con una base di codice semplice, poche dipendenze e infrastruttura minima. Questo componente fungerà da banco di prova per consentire al team di esercitarsi con l'implementazione di DevOps.
Passaggio 2: Valuta la possibilità di adottare una metodologia Agile come Scrum
DevOps spesso viene associato a una metodologia di lavoro Agile, come Scrum. Non è necessario adottare tutti i rituali e le pratiche associate a un metodo come Scrum. Tre elementi di Scrum che sono in genere semplici da adottare e che forniscono rapidamente valore sono il backlog, lo sprint e la pianificazione dello sprint.
Un team DevOps può aggiungere e assegnare priorità al lavoro in un backlog Scrum e poi eseguire un pull di un sottoinsieme di quel lavoro in uno sprint, ovvero un intervallo di tempo fisso, per completare una porzione di lavoro specifica. La pianificazione dello sprint è il processo in cui si decide quali task trasferire dal backlog allo sprint successivo.
Passaggio 3: Usa il controllo del codice sorgente basato su Git
Il controllo della versione è una best practice DevOps che favorisce maggiore collaborazione e cicli di rilascio più rapidi. Strumenti come Bitbucket consentono agli sviluppatori di condividere, collaborare, effettuare il merge ed eseguire il backup del software.
Scegli un modello di creazione di branch. Questo articolo offre una panoramica di questo concetto. Il flusso GitHub è un eccellente punto di partenza per i team che non conoscono Git perché è semplice da comprendere e facile da implementare. Lo sviluppo basato su trunk è spesso la scelta preferita, ma richiede più disciplina e rende più difficoltosa la prima esperienza con Git.
Passaggio 4: Integra il controllo del codice sorgente con il monitoraggio del lavoro
Integra lo strumento di controllo del codice sorgente con lo strumento di monitoraggio del lavoro. Potendo visualizzare in un'unica posizione tutti gli elementi correlati a un determinato progetto, gli sviluppatori e i responsabili risparmieranno una quantità considerevole di tempo. Di seguito è riportato un esempio di un ticket Jira con aggiornamenti provenienti da un repository di controllo del codice sorgente basato su Git. I ticket Jira includono una sezione di sviluppo in cui viene aggregato il lavoro svolto per il ticket Jira nel controllo del codice sorgente. Questo ticket disponeva di un singolo branch, sei commit, una pull request e una sola build.
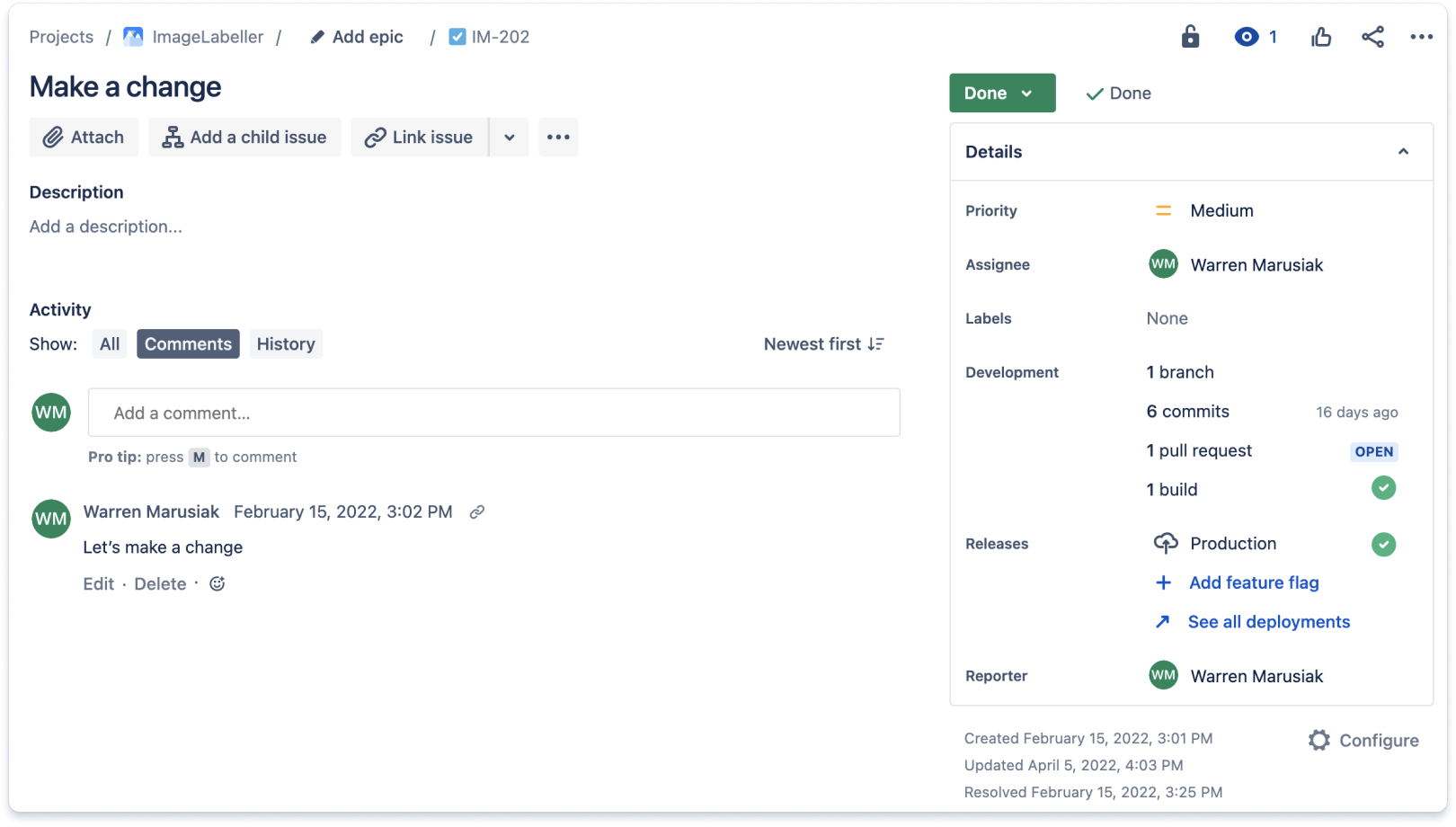
Leggi la sezione dedicata allo sviluppo dei ticket Jira per altri dettagli. Nella scheda dei commit sono elencati tutti i commit associati a un ticket Jira.
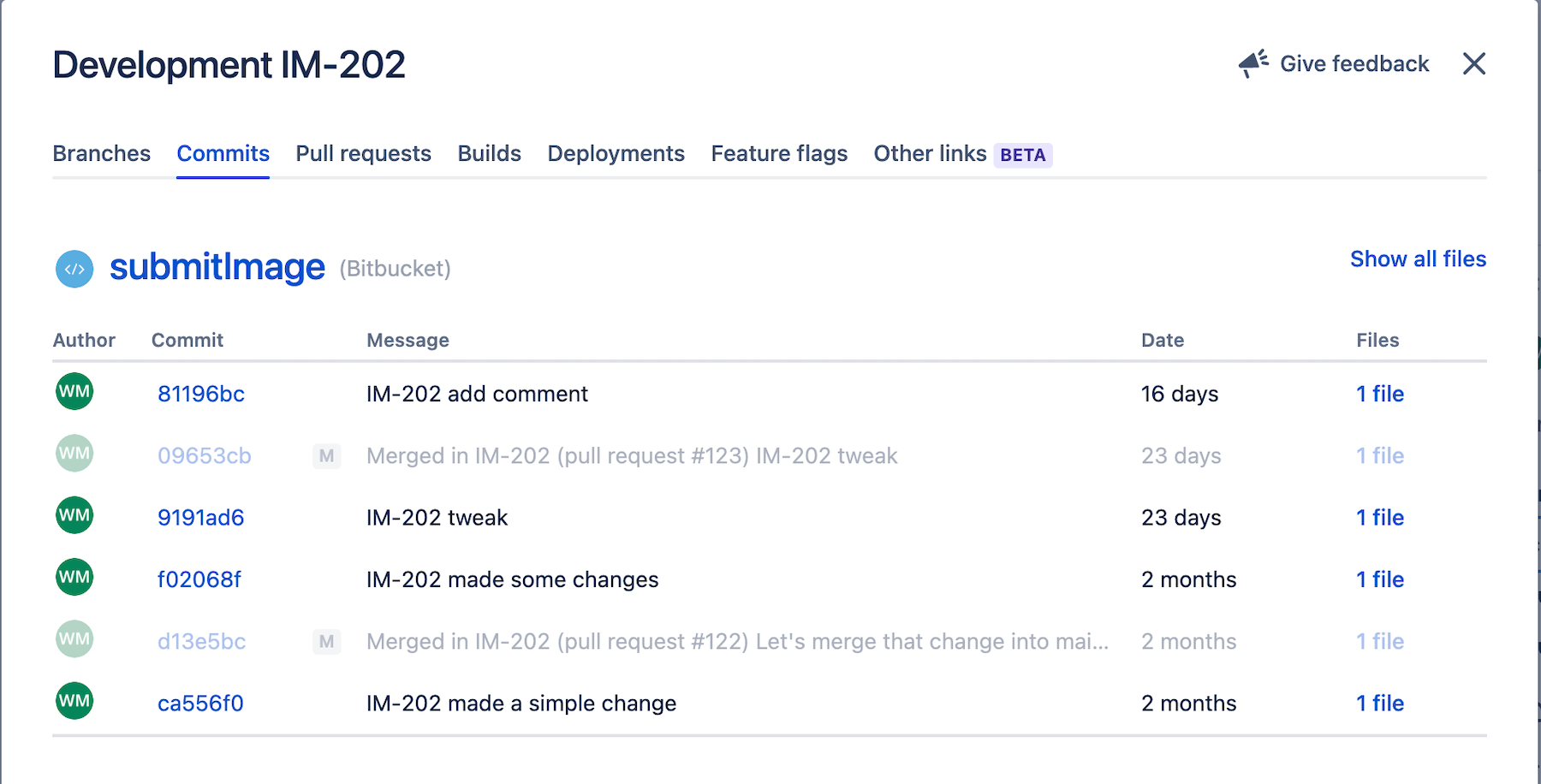
In questa sezione sono elencate tutte le pull request associate al ticket Jira.
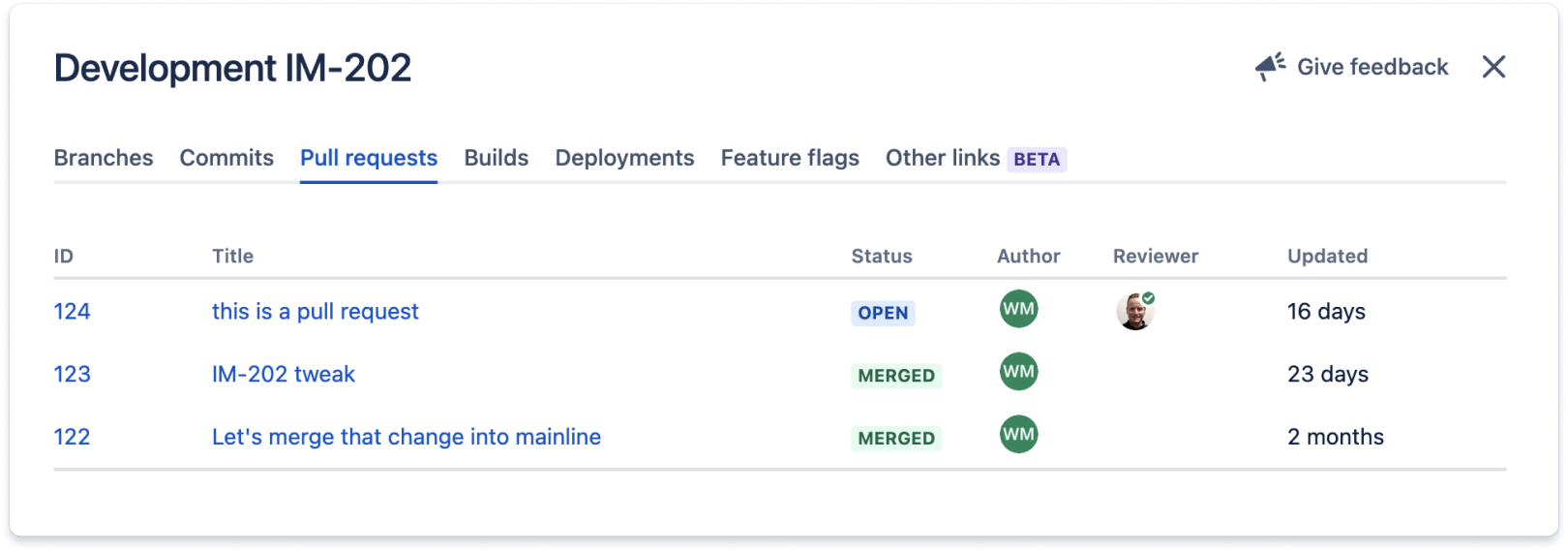
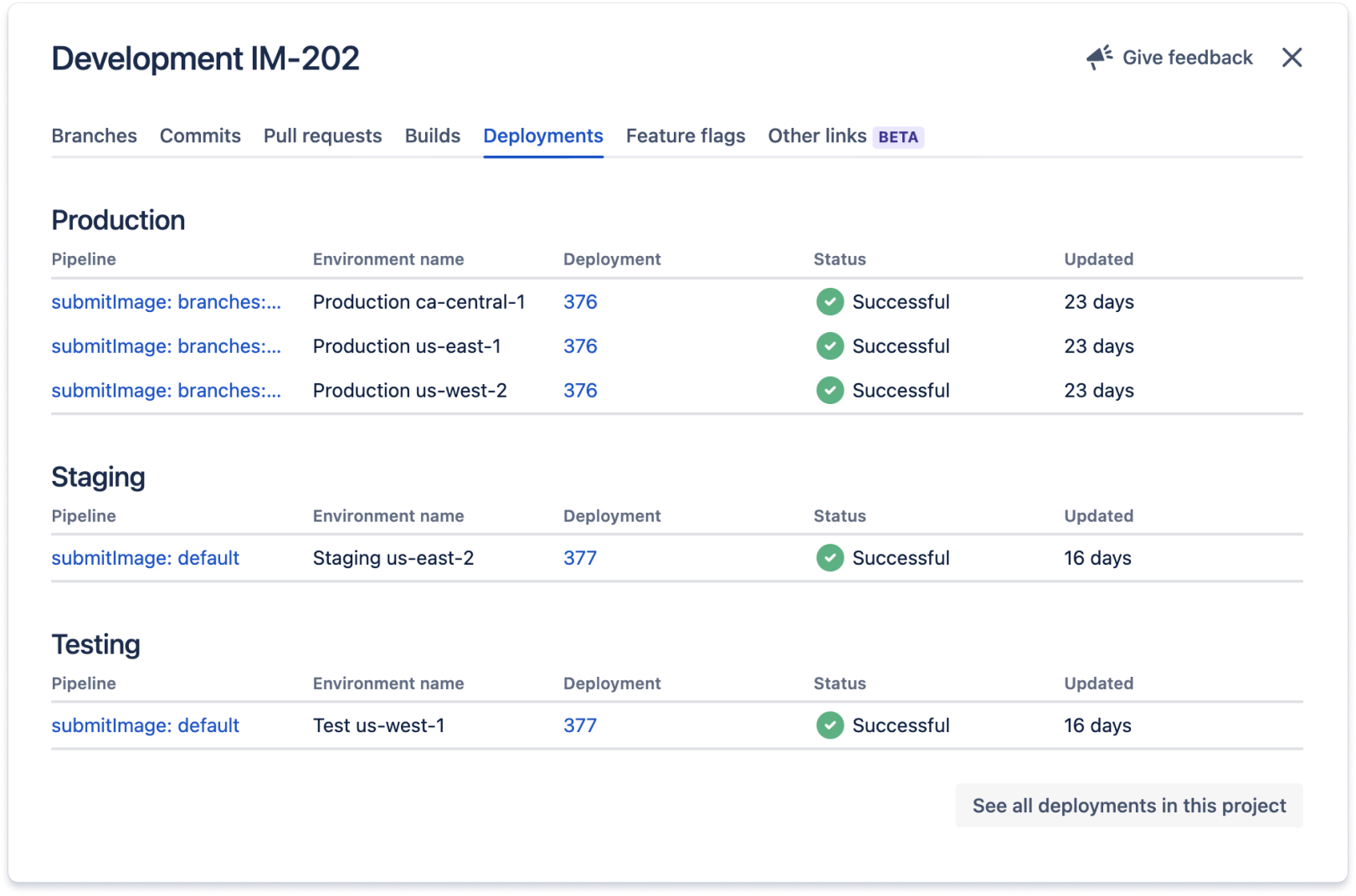
Il codice correlato a questo ticket Jira viene distribuito in tutti gli ambienti elencati nella sezione Deployments (Distribuzioni). Queste integrazioni in genere funzionano tramite l'aggiunta dell'ID del ticket Jira (in questo caso IM-202) ai messaggi di commit e ai nomi dei branch del lavoro correlato al ticket Jira.
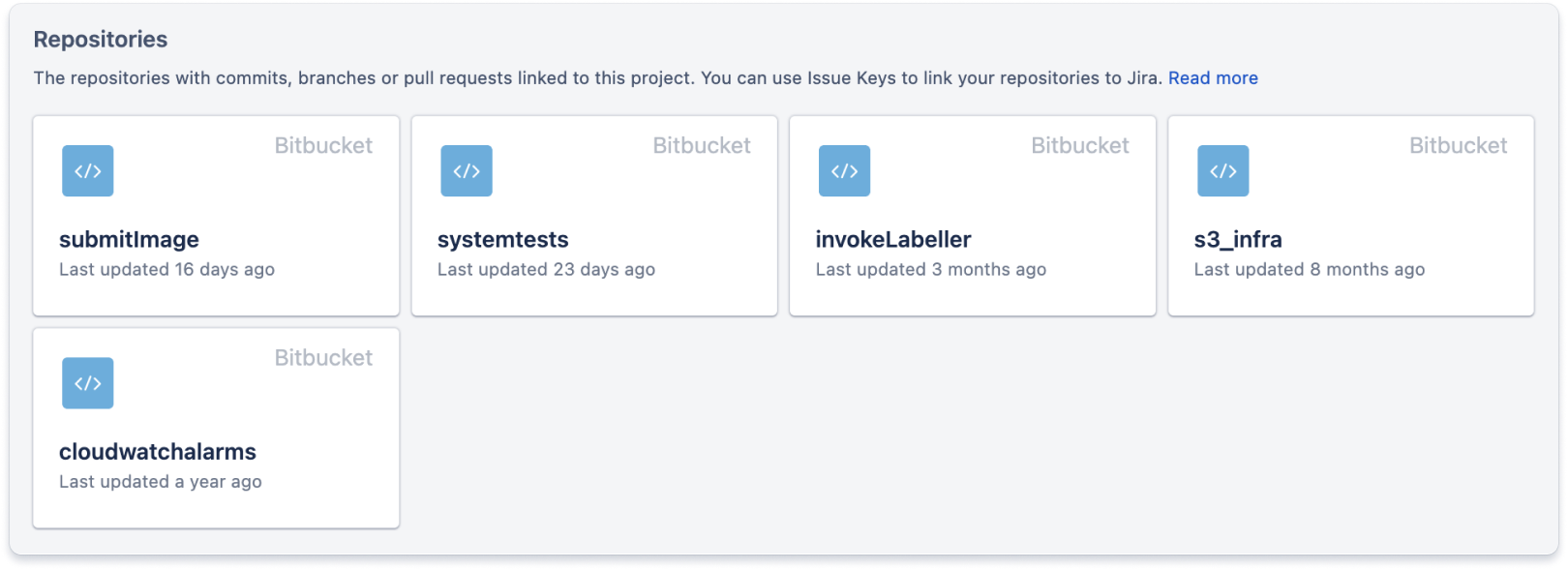
È presente una scheda del codice che contiene i link a tutti i repository del controllo del codice sorgente correlati al progetto. In questo modo, gli sviluppatori possono trovare il codice su cui devono lavorare quando assegnano se stessi a un ticket Jira.
Passaggio 5: Scrivi i test
Le pipeline CI/CD hanno bisogno di test per verificare il corretto funzionamento del codice distribuito nei diversi ambienti. Inizia scrivendo test unitari del codice. Raggiungere una copertura del codice del 90% è un obiettivo ambizioso, ma poco realistico quando si è all'inizio. Imposta una baseline ridotta per la copertura del codice e alza a poco a poco l'asticella della copertura dei test unitari nel corso del tempo. Per farlo, puoi aggiungere elementi di lavoro al backlog.
Usa lo sviluppo basato su test durante la correzione dei bug rilevati nel codice di produzione. Quando trovi un bug, scrivi test unitari, test di integrazione e/o test di sistema che non vengono superati negli ambienti in cui si trova il bug. Quindi, correggi il bug e osserva come adesso i test vengono superati. Questo processo aumenterà in modo organico la copertura del codice nel tempo. Se il bug è stato rilevato in un ambiente di test o di staging, i test confermeranno il corretto funzionamento del codice una volta trasferito all'ambiente di produzione.
Se stai partendo dall'inizio, questo passaggio richiede molto lavoro, ma è fondamentale. I test consentono ai team di vedere gli effetti che le modifiche del codice hanno sul comportamento del sistema prima di esporre gli utenti finali a tali modifiche.
Test unitari
I test unitari consentono di verificare la correttezza del codice sorgente e devono essere eseguiti come uno dei primi passaggi della pipeline CI/CD. Gli sviluppatori devono scrivere dei test per i casi di green path, input problematici e i casi ricorrenti noti. Durante la scrittura dei test, gli sviluppatori possono simulare gli input e gli output previsti.
Test di integrazione
I test di integrazione consentono di verificare che la comunicazione tra due componenti avvenga correttamente. Questi test simulano gli input e gli output previsti e rappresentano uno dei primi passaggi di una pipeline CI/CD prima della distribuzione in un qualsiasi ambiente. In genere, questi test richiedono attività di simulazione più estese rispetto ai test unitari per avviarne il funzionamento.
Test di sistema
I test di sistema consentono di verificare le prestazioni end-to-end del sistema e di assicurarsi che quest'ultimo funzioni come previsto in ogni ambiente. Questi test simulano l'input che un componente potrebbe ricevere ed eseguono il sistema. Quindi, verificano che il sistema restituisca i valori necessari e che aggiorni correttamente le altre parti del sistema. Questi test devono essere eseguiti dopo la distribuzione in ciascun ambiente.
Passaggio 6: Delinea un processo CI/CD per la distribuzione del componente
Prendi in considerazione l'idea di effettuare la distribuzione in più ambienti durante la creazione di una pipeline CI/CD. Se un team crea una pipeline CI/CD che distribuisce soltanto in un solo ambiente, si avrà una codifica fissa. È importante creare pipeline CI/CD per l'infrastruttura e il codice. Inizia creando una pipeline CI/CD per distribuire l'infrastruttura necessaria in ciascun ambiente. Quindi, crea un'altra pipeline CI/CD per distribuire il codice.
Struttura della pipeline
Questa pipeline inizia con l'esecuzione dei test unitari e dei test di integrazione prima di passare alla distribuzione nell'ambiente di test. I test di sistema vengono eseguiti dopo la distribuzione in un ambiente.
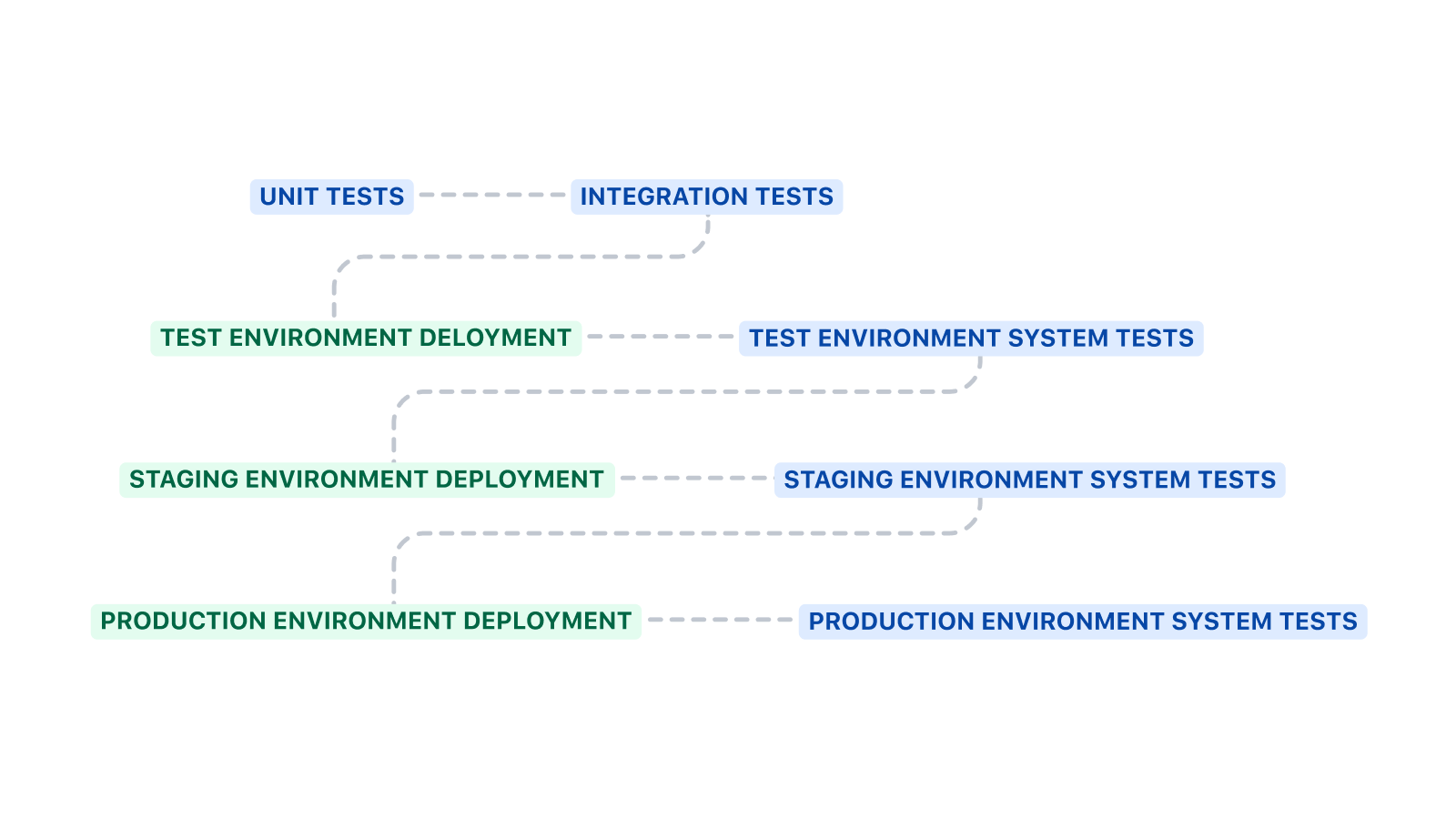
La bozza del modello riportata sopra può essere ampliata in molti modi. Linting del codice, analisi statica e scansione della sicurezza sono altri passaggi validi da aggiungere prima dei test unitari e di integrazione. Il linting del codice può contribuire al rispetto degli standard di codifica, l'analisi statica controlla la presenza di anti-pattern e la scansione della sicurezza è in grado di rilevare la presenza di vulnerabilità note.
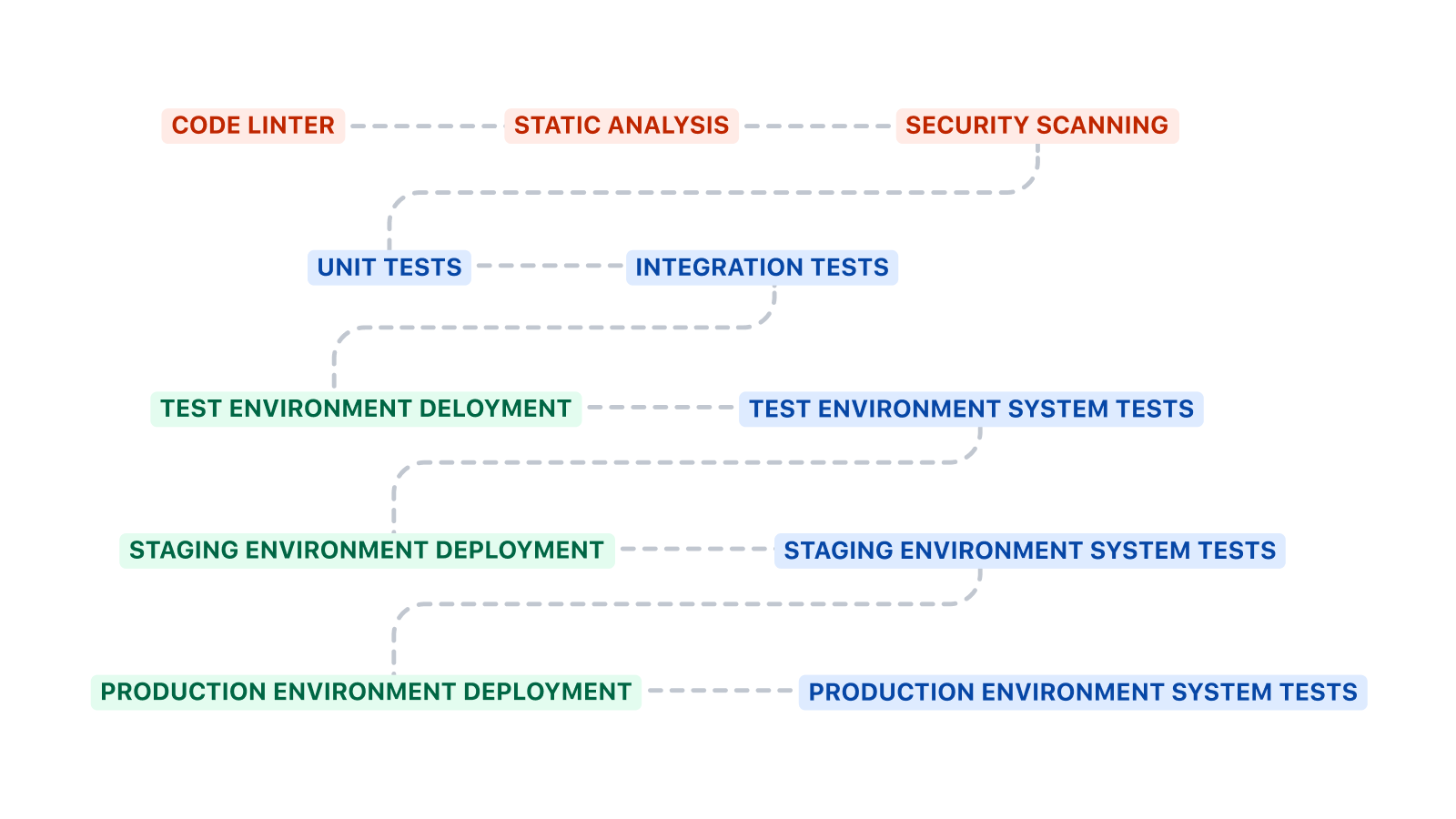
Le pipeline CI/CD per la distribuzione dell'infrastruttura e del codice sono probabilmente diverse. La pipeline CI/CD per l'infrastruttura spesso non dispone di test unitari o di integrazione. Esegue i test di sistema dopo ogni distribuzione per verificare che il sistema non abbia smesso di funzionare.
Infrastruttura
Le differenze di infrastruttura tra i vari ambienti complicano l'esecuzione corretta del software in esecuzione in un determinato ambiente. Le regole del firewall, le autorizzazioni utente, l'accesso al database e altri componenti del livello di infrastruttura devono trovarsi in una configurazione nota per assicurare la corretta esecuzione del software. La distribuzione manuale dell'infrastruttura può essere difficile da ripetere correttamente. Dal momento che questo processo comprende molti passaggi, ricordarsi di eseguire ogni passaggio nell'ordine corretto, con i parametri giusti, può portare ad errori. L'infrastruttura deve essere definita nel codice, laddove possibile, per mitigare questi e altri problemi.
L'infrastruttura può essere definita nel codice tramite tanti strumenti diversi, tra cui AWS CloudFormation, Terraform, Ansible, Puppet o Chef.
Scrivi più pipeline per distribuire l'infrastruttura. Come per la scrittura del codice, è utile mantenere la distribuzione dell'infrastruttura modulare. Se possibile, scomponi l'infrastruttura richiesta in sottoinsiemi disgiunti. Supponiamo che A, B, C e D siano astrazioni dei componenti dell'infrastruttura che possono dipendere l'uno dall'altro. Ad esempio, A potrebbe essere una box EC2 e B un bucket S3. Le dipendenze in cui un componente dell'infrastruttura A, e solo A, dipendono dal componente B devono probabilmente essere tenute insieme nella stessa pipeline CI/CD. Le dipendenze in cui A, B e C dipendono da D, ma in cui A, B e C sono indipendenti, devono essere suddivise in più pipeline Ci/CD. In questo caso, in quattro pipeline indipendenti. In questa istanza, devi creare una pipeline per D, da cui dipendono tutti gli altri tre componenti, e una pipeline per ciascun componente A, B e C.
Codice
Le pipeline CI/CD sono create per la distribuzione di codice. Queste pipeline sono in genere semplici da implementare poiché l'infrastruttura è già disponibile grazie al lavoro svolto in precedenza. In questa fase è importante prestare attenzione ai test, alla ripetibilità e alla capacità di ripristino da distribuzioni errate.
La ripetibilità è la capacità di distribuire la stessa modifica più volte senza danneggiare il sistema. La distribuzione deve essere rientrante e idempotente e deve impostare lo stato di un sistema su una configurazione nota piuttosto che applicare un modificatore allo stato esistente. L'applicazione di un modificatore non è un passaggio che può essere ripetuto poiché, dopo la prima distribuzione, la data di inizio necessaria per garantire il corretto funzionamento del modificatore è cambiata.
Un esempio semplice di aggiornamento non ripetibile è l'aggiornamento di un file di configurazione tramite l'accodamento di dati. Non accodare righe ai file di configurazione o utilizzare nessun'altra tecnica di modifica simile. Se gli aggiornamenti vengono effettuati tramite l'accodamento, il file di configurazione può terminare con decine di righe duplicate. Invece, sostituisci il file di configurazione con un file scritto correttamente dallo strumento di controllo del codice sorgente.
Questo principio va applicato anche all'aggiornamento dei database. Gli aggiornamenti dei database possono essere problematici e richiedono grande attenzione ai dettagli. È essenziale fare in modo che il processo di aggiornamento del database sia ripetibile e a tolleranza di errore. Esegui dei backup immediatamente prima di applicare le modifiche per poter eseguire un ripristino se necessario.
Un'altra considerazione da fare è capire come ripristinare il sistema in seguito a una distribuzione errata. Sia nel caso in cui la distribuzione non è andata a buon fine e il sistema si trova in uno stato sconosciuto o nel caso in cui la distribuzione è riuscita, vengono attivati degli avvisi e cominciano ad arrivare ticket di assistenza. Ci sono due modi generali per gestire questa situazione. Il primo è eseguire un rollback. Il secondo è utilizzare i flag delle funzioni e disattivare i flag necessari per reimpostare il sistema su uno stato corretto noto. Vedi il passaggio 8 di questo articolo per ulteriori informazioni sui flag delle funzioni.
Il rollback consente di distribuire lo stato corretto noto precedente in un ambiente in seguito al rilevamento di una distribuzione errata. Questa operazione deve essere pianificata fin dall'inizio. Prima di iniziare a lavorare su un database, esegui un backup. Assicurati di poter distribuire rapidamente la versione precedente del codice. Testa il processo di rollback negli ambienti di test o staging con regolarità.
Passaggio 7: Aggiungi monitoraggio, avvisi e strumentazione
I team DevOps hanno la necessità di monitorare il comportamento dell'applicazione in esecuzione in ciascun ambiente. Ci sono errori nei log? Si è verificato il time out delle chiamate alle API? Si stanno verificando arresti anomali dei database? Monitora ogni componente del sistema per rilevare eventuali problemi. Se è questo il caso, crea un ticket in modo che chi di dovere possa occuparsi della risoluzione dei problemi. Inoltre, come parte della risoluzione dei problemi, scrivi ulteriori test in grado di individuare il problema in questione.
Correzione dei bug
Il monitoraggio e la risposta ai problemi sono parte dell'esecuzione del software di produzione. I team con una cultura DevOps sono responsabili del funzionamento del software e prendono in prestito i comportamenti dei Site Reliability Engineer (SRE). Effettua l'analisi della causa principale del problema, scrivi test per rilevarlo, correggilo e assicurati che venga superato. Questo processo è spesso laborioso all'inizio, ma paga nel lungo termine poiché riduce il debito tecnico mantenendo l'agilità operativa.
Ottimizzazione delle prestazioni
Dopo aver configurato il monitoraggio dell'integrità di base, di solito si passa all'ottimizzazione delle prestazioni. Esamina l'esecuzione di ogni parte del sistema e ottimizza quelle più lente. Come ha osservato Knuth: "l'ottimizzazione prematura è la causa di tutti i mali". Non migliorare le prestazioni di tutti gli elementi del sistema, ma concentrati soltanto su quelli più lenti e costosi, servendoti del monitoraggio per identificarli.
Passaggio 8: Usa i flag delle funzioni per implementare i test canary
Per abilitare i test canary, riunisci ogni nuova funzione in un flag delle funzioni con un elenco degli utenti di test consentiti. Il nuovo codice delle funzioni verrà eseguito soltanto per gli utenti indicati nell'elenco, in seguito alla distribuzione in un ambiente. Lascia che la nuova funzione venga ben assorbita in un ambiente prima di farla avanzare al successivo. Mentre la nuova funzione si trova in una regione, osserva metriche, avvisi e altri elementi di strumentazione per cogliere i segnali di eventuali problemi. Nello specifico, cerca un eventuale aumento del numero di nuovi ticket di assistenza.
Affronta i problemi in un ambiente prima di farli avanzare all'ambiente successivo. I problemi rilevati nell'ambiente di produzione devono essere gestiti allo stesso modo dei problemi emersi nell'ambiente di test o di staging. Dopo aver individuato la causa principale del problema, scrivi dei test per identificarlo, implementa una correzione, assicurati che il test venga superato e fai avanzare la correzione nella pipeline CI/CD. I nuovi test verranno superati e il numero di ticket di assistenza diminuirà mentre la modifica viene assimilata dall'ambiente in cui è stato rilevato il problema.
In conclusione...
Esegui una retrospettiva del progetto per trasferire il primo componente in DevOps. Identifica le criticità o gli aspetti complicati o difficili. Migliora il piano per affrontare queste criticità e passa al secondo componente.
Utilizzare l'approccio DevOps per far arrivare un componente all'ambiente di produzione potrebbe sembrare notevolmente impegnativo all'inizio, ma è una scelta che ripaga nel lungo termine. L'implementazione del secondo componente dovrebbe essere più semplice una volta che hai gettato le basi. Lo stesso processo seguito per il primo componente può essere utilizzato (e leggermente modificato) anche per il secondo componente, dal momento che gli strumenti sono già a disposizione del team che ha compreso le tecnologie e si è esercitato a lavorare seguendo lo stile DevOps
Per iniziare il percorso con DevOps ti consigliamo di provare Atlassian Open DevOps, una toolchain integrata e aperta, con tutto ciò che ti serve per sviluppare e far funzionare il software, e in grado di offrire la possibilità di integrare strumenti aggiuntivi man mano che le tue esigenze crescono.
Condividi l'articolo
Argomento successivo
Letture consigliate
Aggiungi ai preferiti queste risorse per ricevere informazioni sui tipi di team DevOps e aggiornamenti continui su DevOps in Atlassian.

Community DevOps

Percorso di apprendimento DevOps