Automation-regel in Jira wanneer pull request wordt samengevoegd
Posted by: Tim Miller
Verder gaan dan agile
Indexing is the way to get an unordered table into an order that will maximize the query’s efficiency while searching.
When a table is unindexed, the order of the rows will likely not be discernible by the query as optimized in any way, and your query will therefore have to search through the rows linearly. In other words, the queries will have to search through every row to find the rows matching the conditions. As you can imagine, this can take a long time. Looking through every single row is not very efficient.
For example, the table below represents a table in a fictional datasource, that is completely unordered.
Company_ID | UNIT | UNIT_COST |
|---|---|---|
| 10 | UNIT 12 | UNIT_COST 1.15 |
| 12 | UNIT 12 | UNIT_COST 1.05 |
| 14 | UNIT 18 | UNIT_COST 1.31 |
| 18 | UNIT 18 | UNIT_COST 1.34 |
| 11 | UNIT 24 | UNIT_COST 1.15 |
| 16 | UNIT 12 | UNIT_COST 1.31 |
| 10 | UNIT 12 | UNIT_COST 1.15 |
| 12 | UNIT 24 | UNIT_COST 1.3 |
| 18 | UNIT 6 | UNIT_COST 1.34 |
| 18 | UNIT 12 | UNIT_COST 1.35 |
| 14 | UNIT 12 | UNIT_COST 1.95 |
| 21 | UNIT 18 | UNIT_COST 1.36 |
| 12 | UNIT 12 | UNIT_COST 1.05 |
| 20 | UNIT 6 | UNIT_COST 1.31 |
| 18 | UNIT 18 | UNIT_COST 1.34 |
| 11 | UNIT 24 | UNIT_COST 1.15 |
| 14 | UNIT 24 | UNIT_COST 1.05 |
If we were to run the following query:
SELECT
company_id,
units,
unit_cost
FROM
index_test
WHERE
company_id = 18The database would have to search through all 17 rows in the order they appear in the table, from top to bottom, one at a time. So to search for all of the potential instances of the company_id number 18, the database must look through the entire table for all appearances of 18 in the company_id column.
This will only get more and more time consuming as the size of the table increases. As the sophistication of the data increases, what could eventually happen is that a table with one billion rows is joined with another table with one billion rows; the query now has to search through twice the amount of rows costing twice the amount of time.
You can see how this becomes problematic in our ever data saturated world. Tables increase in size and searching increases in execution time.
Querying an unindexed table, if presented visually, would look like this:
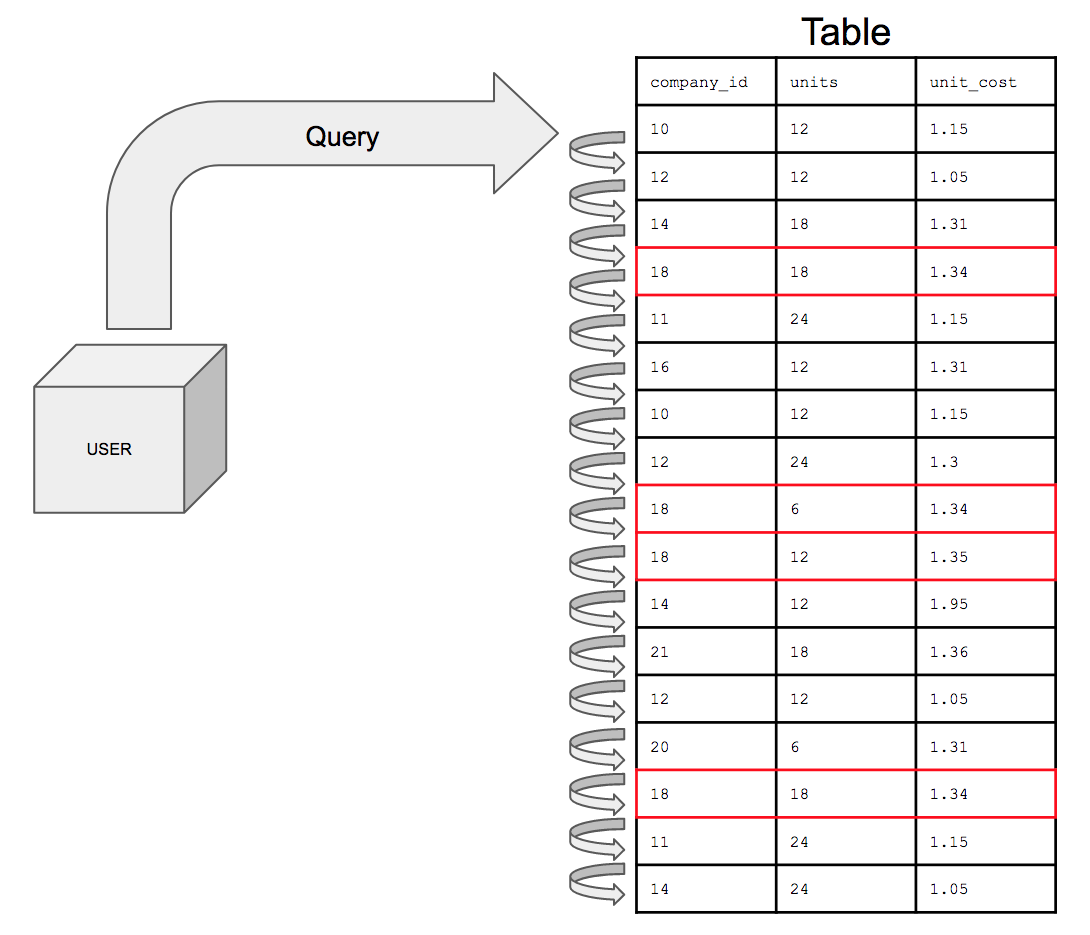
What indexing does is sets up the column you’re search conditions are on in a sorted order to assist in optimizing query performance.
With an index on the company_id column, the table would, essentially, “look” like this:
COMPANY_ID | UNIT | UNIT_COST |
|---|---|---|
| 10 | UNIT 12 | UNIT_COST 1.15 |
| 10 | UNIT 12 | UNIT_COST 1.15 |
| 11 | UNIT 24 | UNIT_COST 1.15 |
| 11 | UNIT 24 | UNIT_COST 1.15 |
| 12 | UNIT 12 | UNIT_COST 1.05 |
| 12 | UNIT 24 | UNIT_COST 1.3 |
| 12 | UNIT 12 | UNIT_COST 1.05 |
| 14 | UNIT 18 | UNIT_COST 1.31 |
| 14 | UNIT 12 | UNIT_COST 1.95 |
| 14 | UNIT 24 | UNIT_COST 1.05 |
| 16 | UNIT 12 | UNIT_COST 1.31 |
| 18 | UNIT 18 | UNIT_COST 1.34 |
| 18 | UNIT 6 | UNIT_COST 1.34 |
| 18 | UNIT 12 | UNIT_COST 1.35 |
| 18 | UNIT 18 | UNIT_COST 1.34 |
| 20 | UNIT 6 | UNIT_COST 1.31 |
| 21 | UNIT 18 | UNIT_COST 1.36 |
Now, the database can search for company_id number 18 and return all the requested columns for that row then move on to the next row. If the next row’s company_id number is also 18 then it will return the all the columns requested in the query. If the next row’s company_id is 20, the query knows to stop searching and the query will finish.
Verder gaan dan agile
In reality the database table does not reorder itself every time the query conditions change in order to optimize the query performance: that would be unrealistic. In actuality, what happens is the index causes the database to create a data structure. The data structure type is very likely a B-Tree. While the advantages of the B-Tree are numerous, the main advantage for our purposes is that it is sortable. When the data structure is sorted in order it makes our search more efficient for the obvious reasons we pointed out above.
When the index creates a data structure on a specific column it is important to note that no other column is stored in the data structure. Our data structure for the table above will only contain the the company_id numbers. Units and unit_cost will not be held in the data structure.
Verder gaan dan agile
Database indexes will also store pointers which are simply reference information for the location of the additional information in memory. Basically the index holds the company_id and that particular row’s home address on the memory disk. The index will actually look like this:
COMPANY_ID | POINTER |
|---|---|
| 10 | _123 |
| 10 | _129 |
| 11 | _127 |
| 11 | _138 |
| 12 | _124 |
| 12 | _130 |
| 12 | _135 |
| 14 | _125 |
| 14 | _131 |
| 14 | _133 |
| 16 | _128 |
| 18 | _126 |
| 18 | _131 |
| 18 | _132 |
| 18 | _137 |
| 20 | _136 |
| 21 | _134 |
With that index, the query can search for only the rows in the company_id column that have 18 and then using the pointer can go into the table to find the specific row where that pointer lives. The query can then go into the table to retrieve the fields for the columns requested for the rows that meet the conditions.
If the search were presented visually, it would look like this:
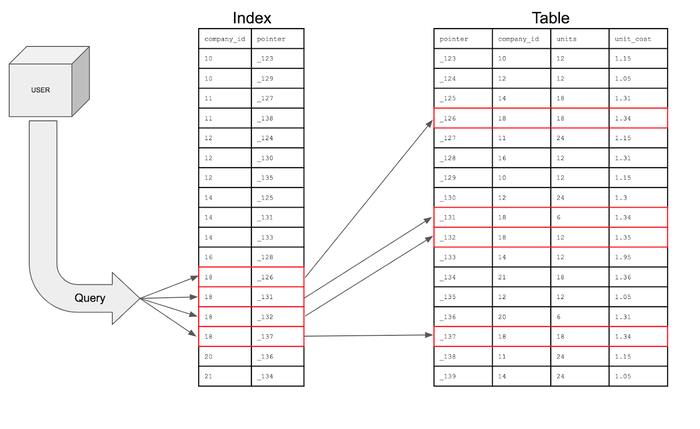
Recap
- Indexing adds a data structure with columns for the search conditions and a pointer
- The pointer is the address on the memory disk of the row with the rest of the information
- The index data structure is sorted to optimize query efficiency
- The query looks for the specific row in the index; the index refers to the pointer which will find the rest of the information.
- The index reduces the number of rows the query has to search through from 17 to 4.