Prueba Compass gratis
Mejora tu experiencia de desarrollador, cataloga todos los servicios y mejora el estado del software.
Cómo aplicar DevOps
Una guía paso a paso para los equipos que quieren implementar DevOps
.png?cdnVersion=2661)
Warren Marusiak
Divulgador técnico sénior
¿Tu ciclo de vida de desarrollo de software es una pesadilla de herramientas y flujos de trabajo? ¿Tus equipos y proyectos están aislados en silos? Si tu respuesta es afirmativa a cualquiera de estas preguntas, es un buen momento para plantearte utilizar DevOps. DevOps ayuda a simplificar y optimizar los flujos de trabajo de desarrollo e implementación mediante la creación de un nuevo ecosistema de desarrollo de software.
Pero ¿cómo se implementa DevOps? Uno de los principales desafíos de DevOps es que no existe un proceso estándar, ya que cada equipo tiene necesidades y objetivos diferentes. La gran cantidad de recursos y herramientas de DevOps puede provocar una "parálisis del análisis" que dificulta su implementación. Los siguientes pasos pueden ayudar a tu equipo a implementar DevOps.
¿Por qué DevOps?
La respuesta es sencilla: DevOps aumenta la productividad al ayudar a los desarrolladores a hacer lo que se les da mejor, es decir, crear un software de calidad en lugar de llevar a cabo manualmente trabajos de poco valor, como comprobar manualmente los archivos del registro. Las prácticas de DevOps automatizan el trabajo repetitivo, como la ejecución de pruebas e implementaciones, la supervisión del software de producción para detectar problemas y la creación de una metodología de implementación resistente a los problemas. Los desarrolladores tienen la capacidad de crear y experimentar, lo que conlleva un aumento de la productividad.
Hay muchas definiciones de DevOps. En este artículo, DevOps significa que un equipo es propietario de todo el ciclo de vida de una pieza de software. Un equipo de DevOps diseña, aplica, implementa, supervisa y actualiza el software, además de corregir problemas relacionados con el mismo. Es propietario del código y de la infraestructura en la que este se ejecuta. No solo es responsable de la experiencia del usuario final, sino también de los problemas de producción.
Uno de los principios de DevOps es crear un proceso que anticipe los problemas y permita a los desarrolladores responder a ellos de forma eficaz. Un proceso de DevOps debe proporcionar a los desarrolladores un feedback inmediato sobre el estado del sistema después de cada implementación. Tras crear el proceso, cuanto antes se detecte un problema, menor será su impacto y antes podrá el equipo pasar al siguiente conjunto de trabajo. Cuando es fácil incorporar cambios y recuperarse de los problemas, los desarrolladores pueden experimentar, compilar, publicar y probar nuevas ideas.
Lo que DevOps no es: tecnología. Si compras herramientas de DevOps y las llamas "DevOps", es como empezar la casa por el tejado. La esencia de DevOps es crear una cultura de responsabilidad compartida, transparencia y feedback más rápido. La tecnología es una simple herramienta que lo hace posible.
Material relacionado
Pruébalo gratis
Material relacionado
Descubre las prácticas recomendadas de DevOps
Aviso
Dado que cada equipo tiene un punto de partida único, es posible que no todos los pasos que se indican en el apartado siguiente deban aplicarse en tu caso. Además, no es una lista de pasos completa. Los pasos que se presentan a continuación pretenden ser un punto de partida para ayudar a los equipos a implementar DevOps.
En este artículo, "DevOps" se usa como un término general para referirse a la cultura, los procesos y las tecnologías que hacen que DevOps funcione.
8 pasos para implementar DevOps
Paso 1: elige un componente
El primer paso es empezar de forma modesta. Elige un componente que esté actualmente en producción. El componente ideal tiene una base de código simple con pocas dependencias y una infraestructura mínima. Este componente será un campo de pruebas en el que el equipo se esforzará por implementar DevOps.
Paso 2: considera la posibilidad de implementar una metodología ágil como scrum
DevOps suele ir acompañado de una metodología de trabajo ágil, como scrum. No es necesario adoptar todas las prácticas y los rituales asociados con un método como scrum. Los tres elementos de scrum que, por lo general, son fáciles de adoptar y que proporcionan valor rápidamente son el backlog, el sprint y la planificación de sprints.
Un equipo de DevOps puede añadir y priorizar el trabajo en un backlog de scrum, e incorporar un subconjunto de ese trabajo a un sprint, es decir, un periodo de tiempo fijo para completar una cantidad de trabajo específica. La planificación de sprints es el proceso de decidir qué tareas avanzan del backlog al siguiente sprint.
Paso 3: usa el control de código fuente basado en Git
El control de versiones es una práctica recomendada de DevOps que permite una mayor colaboración y ciclos de publicación más rápidos. Herramientas como Bitbucket ayudan a los desarrolladores a compartir, colaborar, fusionar y hacer copias de seguridad del software.
Escoge un modelo de ramificación. Este artículo ofrece información general sobre este concepto. El flujo de GitHub es un excelente punto de partida para los equipos que empiezan con Git, ya que es fácil de entender y de implementar. Se suele preferir el desarrollo basado en troncos, pero requiere más disciplina y dificulta la primera incursión en Git.
Paso 4: integra el control de código fuente con el seguimiento del trabajo
Integra la herramienta de control de código fuente con la de seguimiento del trabajo. Al contar con un único lugar para ver todo lo relacionado con un proyecto concreto, los desarrolladores y el equipo de gestión ahorrarán una cantidad de tiempo considerable. A continuación, se muestra un ejemplo de una actividad de Jira con actualizaciones de un repositorio de control de código fuente basado en Git. Las actividades de Jira incluyen una sección de desarrollo que va añadiendo el trabajo hecho para la actividad de Jira en el control de código fuente. Esta incidencia tenía una sola rama, seis confirmaciones, una solicitud de extracción y una sola compilación.
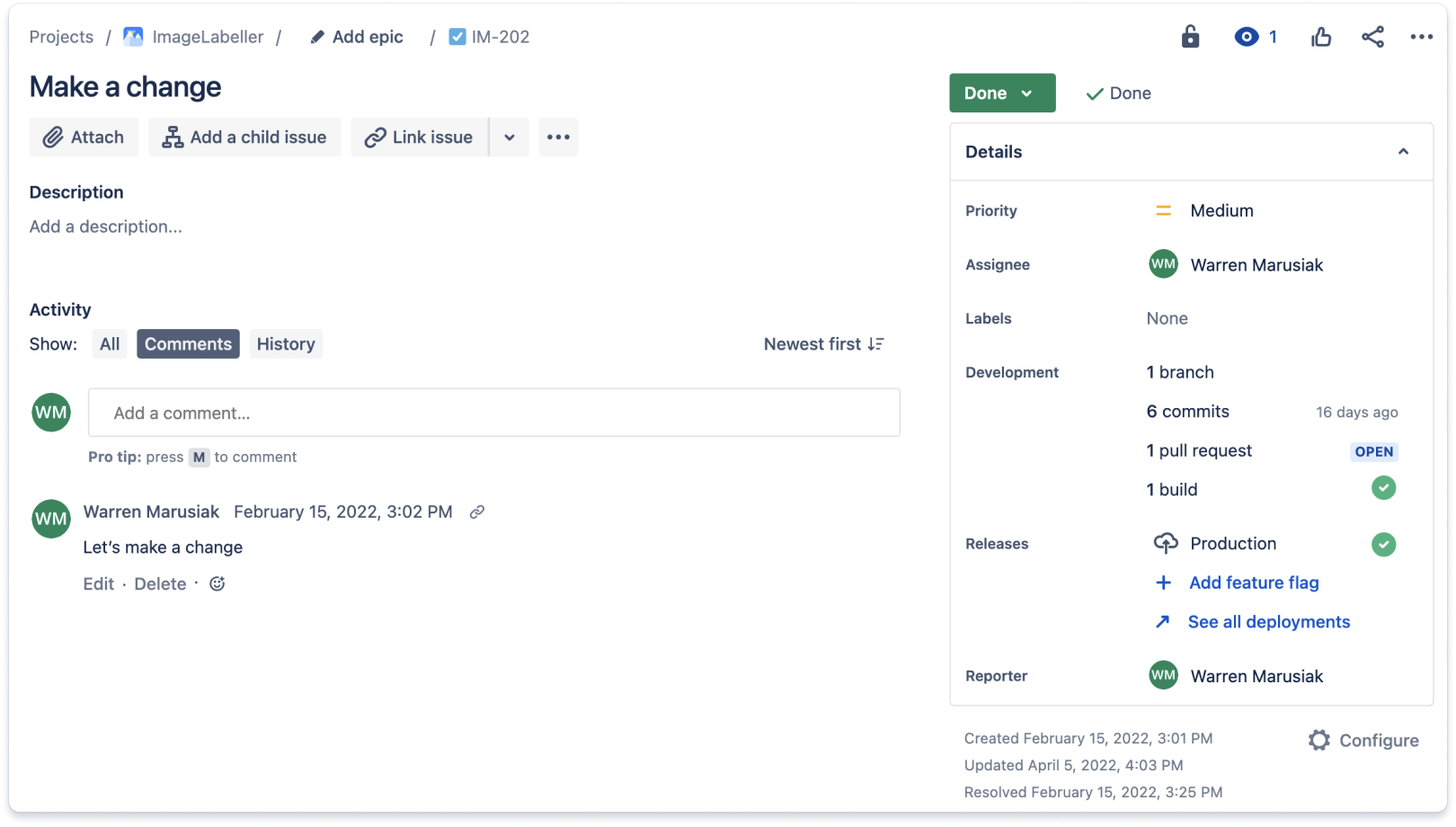
Encontrarás más información consultando la sección de desarrollo de una actividad de Jira. La pestaña de confirmaciones muestra todas las confirmaciones asociadas a una actividad de Jira.
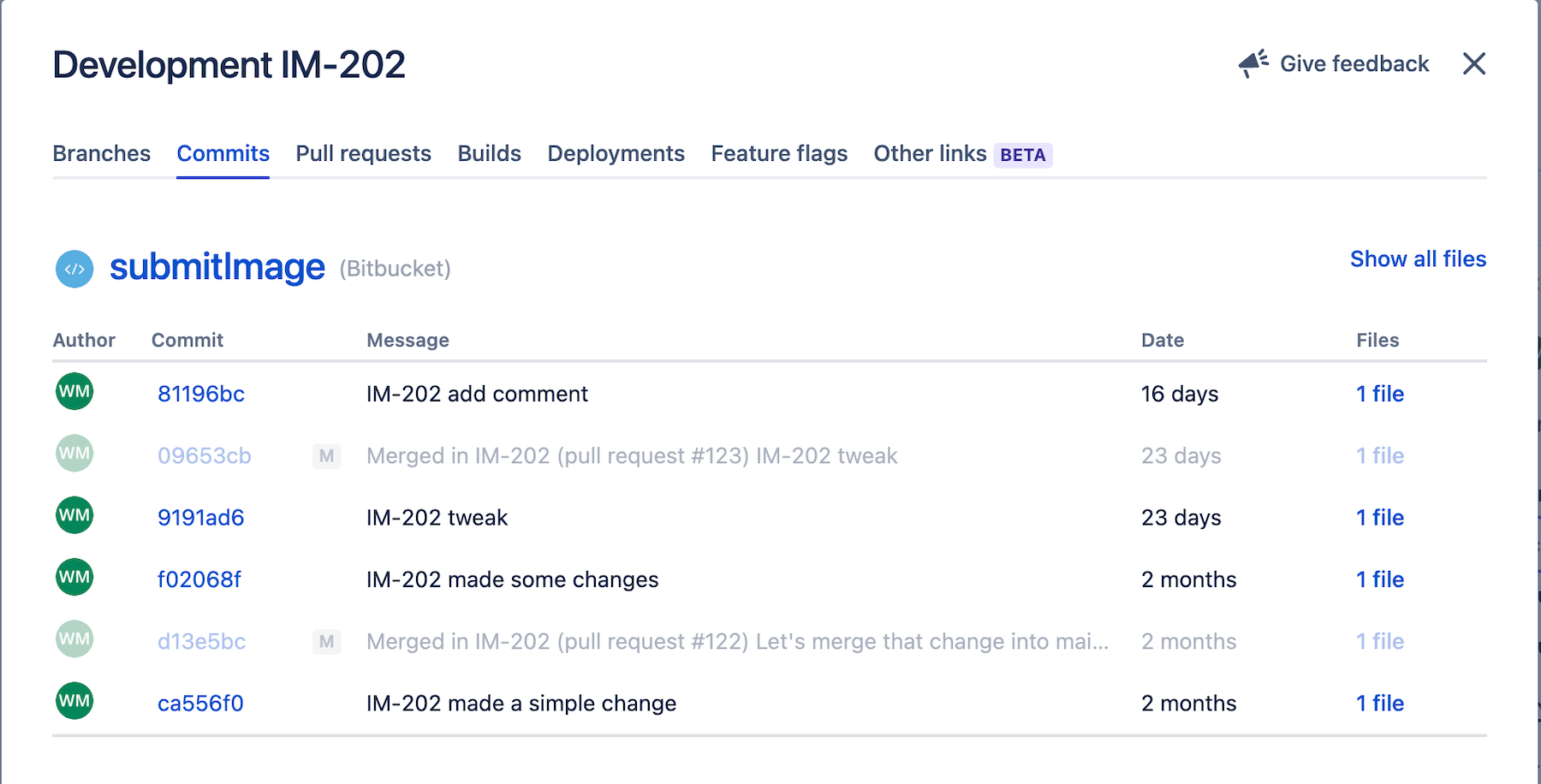
En esta sección se muestran todas las solicitudes de extracción asociadas a la actividad de Jira.
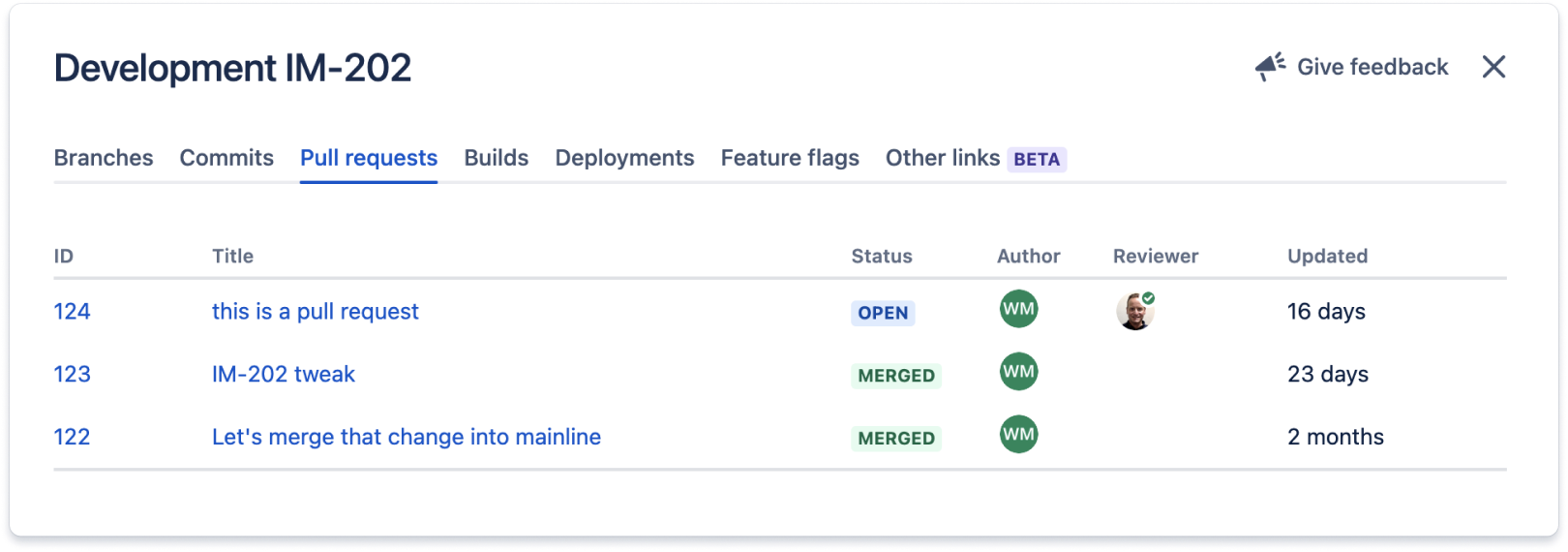
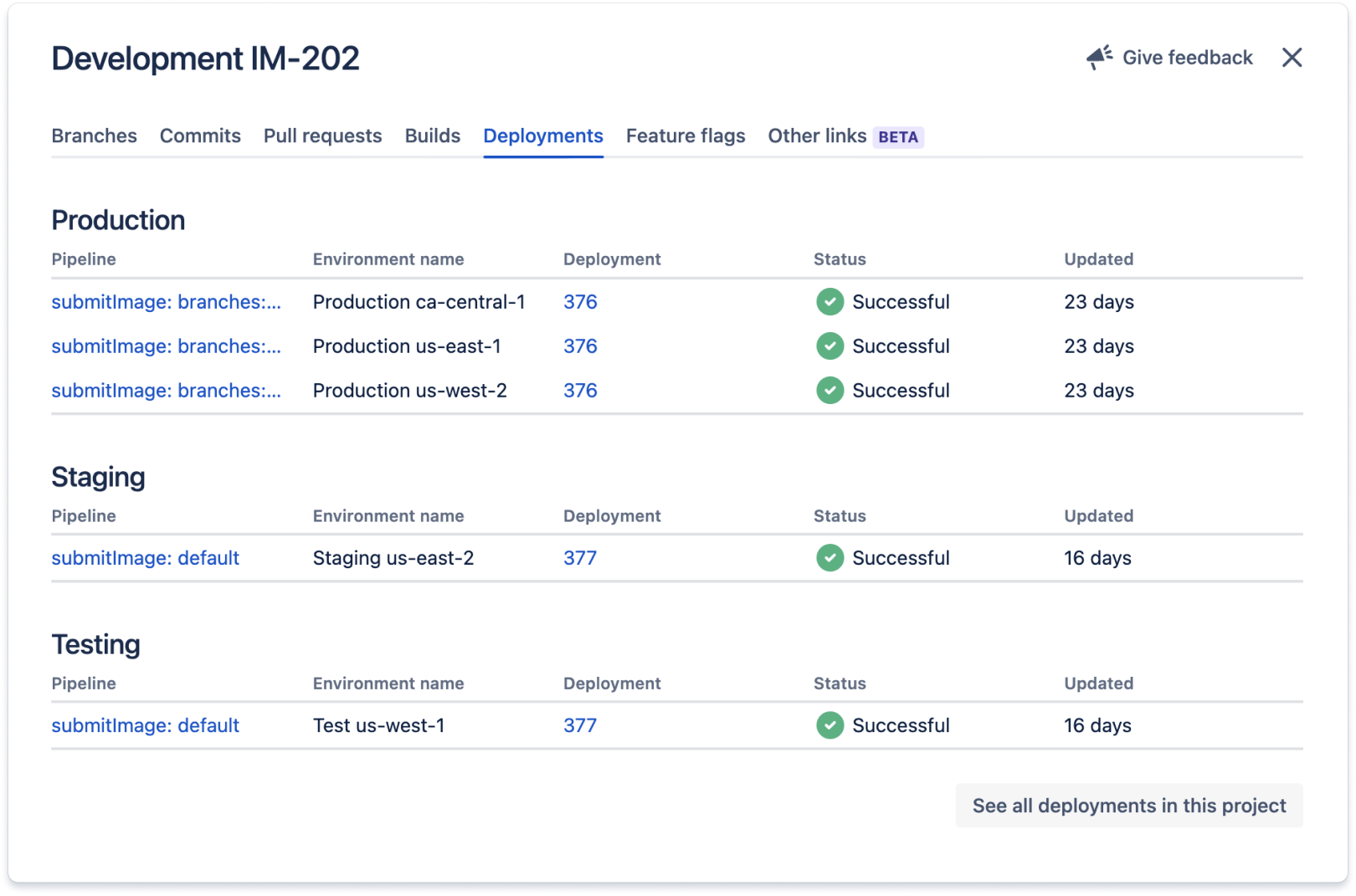
El código relacionado con esta actividad de Jira se implementa en todos los entornos que aparecen en la sección Implementaciones. Estas integraciones suelen funcionar añadiendo el ID de la actividad de Jira (en este caso, IM-202) en los mensajes de confirmación y los nombres de las ramas de trabajo relacionados con la actividad de Jira.
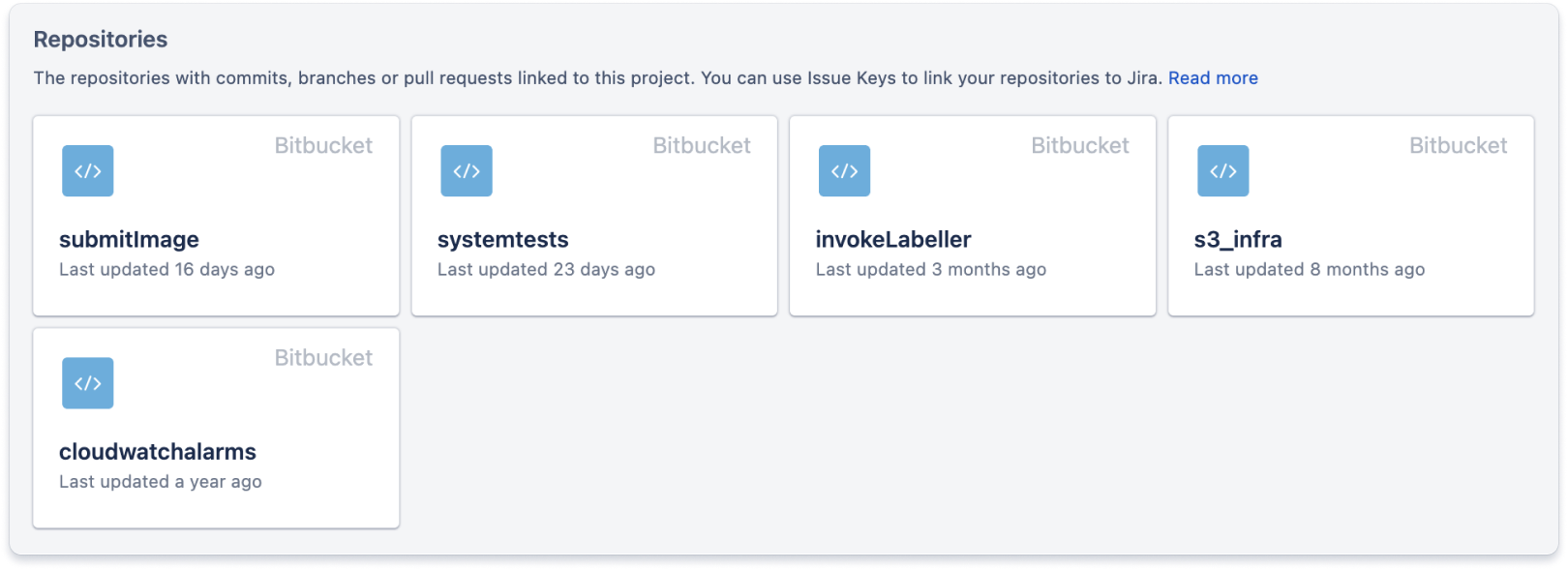
Hay una pestaña de código que proporciona enlaces a todos los repositorios de control de código fuente relacionadas con el proyecto. Esto ayuda a los desarrolladores a encontrar el código en el que tienen que trabajar cuando se asignan a una actividad de Jira.
Paso 5: escribe pruebas
Las canalizaciones de CI/CD necesitan pruebas para validar que el código implementado en varios entornos funciona correctamente. Empieza por escribir pruebas unitarias para el código. Aunque un objetivo ambicioso sería una cobertura de código del 90 por ciento, no es una estimación realista cuando se acaba de empezar. Establece una línea base baja para la cobertura de código y aumenta gradualmente el listón para la cobertura de las pruebas unitarias a lo largo del tiempo. Puedes añadir elementos de trabajo al backlog para abordar este tema.
Utiliza un desarrollo basado en pruebas para corregir los errores que encuentres en el código de producción. Cuando encuentres un error, escribe pruebas unitarias, pruebas de integración y/o pruebas de sistema que fallen en entornos en los que aparezca el error. Luego, soluciona el error y comprueba que se superen las pruebas. Este proceso aumentará orgánicamente la cobertura de código a lo largo del tiempo. Si el error se ha detectado en un entorno de ensayo o de prueba, las pruebas darán la seguridad de que el código funciona correctamente cuando se pase a la producción.
Al empezar desde el principio, este paso requiere mucho trabajo, pero es muy importante. Las pruebas permiten a los equipos ver el efecto de los cambios de código en el comportamiento del sistema antes de exponer a los usuarios finales a estos cambios en el código.
Pruebas unitarias
Las pruebas unitarias comprueban que el código fuente es correcto y deben ejecutarse como uno de los primeros pasos en una canalización de CI/CD. Los desarrolladores deben escribir pruebas para la ruta verde, entradas problemáticas y casos límite conocidos. Al escribir las pruebas, los desarrolladores pueden simular las entradas y los resultados esperados.
Pruebas de integración
Las pruebas de integración verifican que dos componentes se comunican entre ellos correctamente. Simula las entradas y los resultados esperados. Estas pruebas son uno de los primeros pasos de una canalización de CI/CD antes de la implementación en cualquier entorno. Por lo general, estas pruebas requieren simulaciones más extensas que las pruebas unitarias para funcionar.
Pruebas de sistema
Las pruebas de sistema comprueban el rendimiento integral del sistema y proporcionan la confianza de que el sistema funciona de la manera esperada en cada entorno. Simula la entrada que pudiera recibir un componente y ejecuta el sistema. A continuación, comprueba que el sistema devuelve los valores necesarios y que actualiza el resto del sistema correctamente. Estas pruebas deben realizarse tras la implementación en cada entorno.
Paso 6: crea un proceso de CI/CD para implementar el componente
A la hora de crear una canalización de CI/CD, considera la posibilidad de realizar la implementación en varios entornos. Si un equipo crea una canalización de CI/CD que se implementa en un solo entorno, se codificará todo de forma no flexible. Es importante crear canalizaciones de CI/CD para la infraestructura y el código. Empieza por crear una canalización de CI/CD para implementar la infraestructura necesaria en cada entorno. A continuación, crea otra canalización de CI/CD para implementar el código.
La estructura de las canalizaciones
Esta canalización comienza con la ejecución de pruebas unitarias y de integración antes de implementarlas en el entorno de pruebas. Las pruebas de sistema se ejecutan después de la implementación en un entorno.
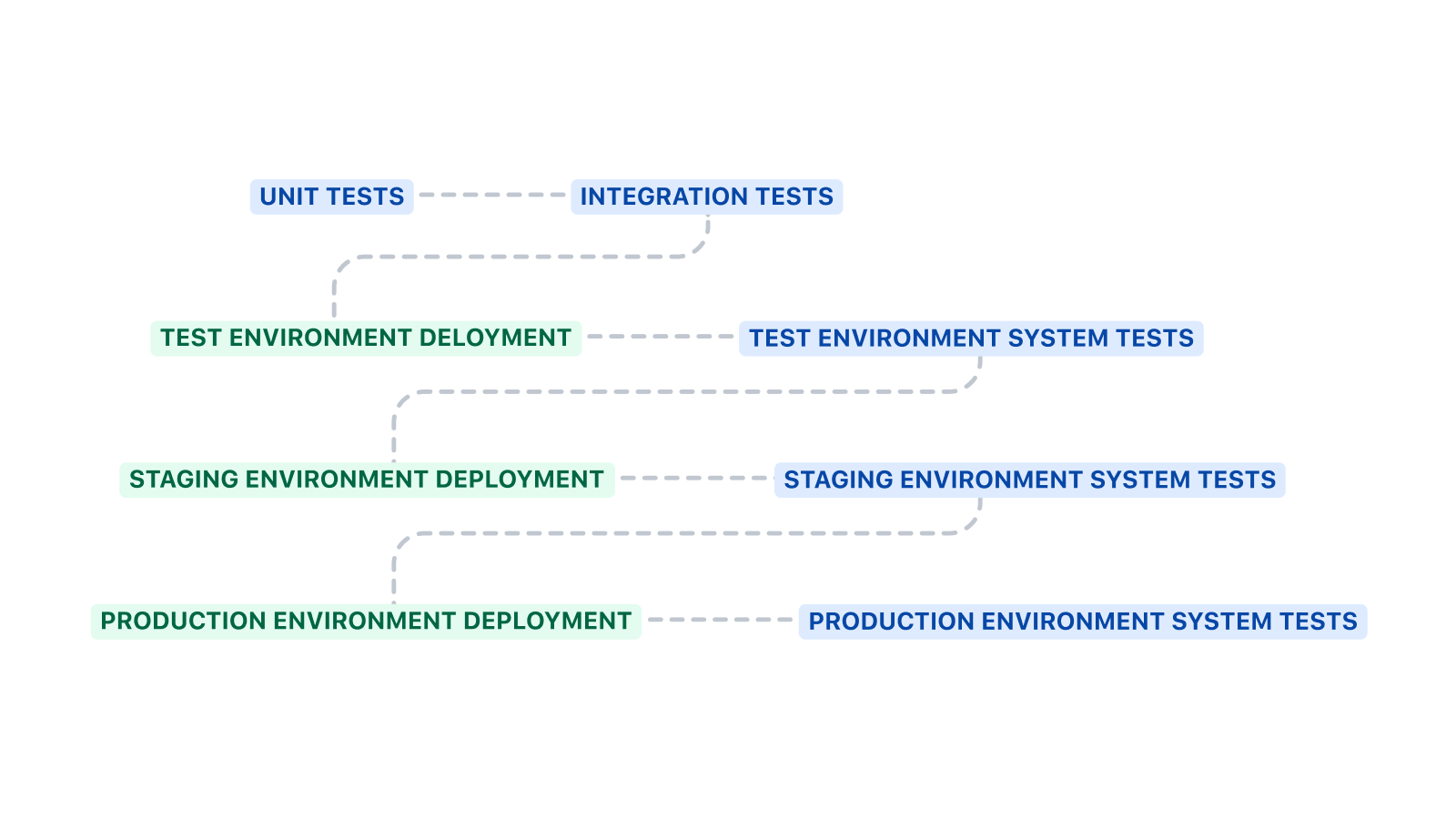
La plantilla aproximada que se muestra arriba se puede ampliar de varias maneras. La depuración del código, el análisis estático y el escaneo de seguridad son pasos adicionales interesantes que puedes añadir antes de las pruebas unitarias y de integración. La depuración del código puede hacer cumplir los estándares de codificación, el análisis estático puede comprobar si hay antipatrones y el escaneo de seguridad puede detectar la presencia de vulnerabilidades conocidas.
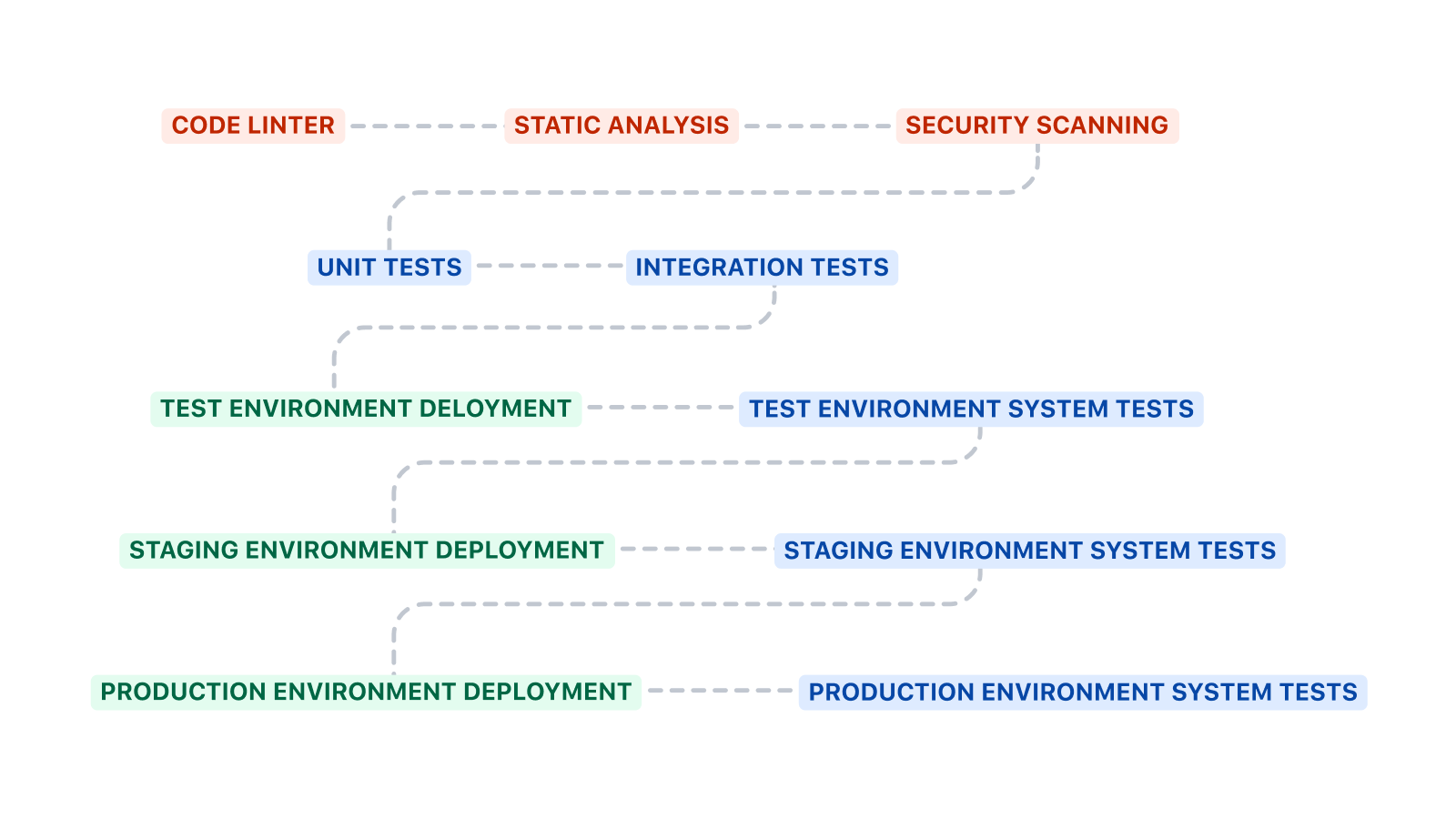
Es probable que las canalizaciones de CI/CD sean diferentes cuando se trate de implementar la infraestructura y el código. La canalización de CI/CD para la infraestructura no suele incluir pruebas unitarias ni de integración. Ejecutará las pruebas de sistema después de cada implementación para asegurarse de que el sistema no ha dejado de funcionar.
Infraestructura
Las diferencias en la infraestructura entre los entornos dificultan que el software que se ejecuta en ese entorno se ejecute correctamente. Las reglas del cortafuegos, los permisos de usuario, el acceso a la base de datos y otros componentes a nivel de infraestructura deben tener una configuración conocida para que el software se ejecute correctamente. La implementación manual de la infraestructura puede ser difícil de repetir correctamente. Como este proceso consta de muchos pasos, acordarse de ejecutar cada paso en el orden correcto y con los parámetros correctos puede provocar errores. La infraestructura tiene que definirse en código siempre que sea posible para que se puedan solucionar estos y otros problemas.
La infraestructura se puede definir en código mediante diversas herramientas, como AWS CloudFormation, Terraform, Ansible, Puppet o Chef.
Escribe varias canalizaciones para implementar la infraestructura. Al igual que escribir código, es útil mantener la implementación de la infraestructura de forma modular. Siempre que sea posible, hay que descomponer la infraestructura requerida en subconjuntos desarticulados. Supongamos que A, B, C y D son abstracciones de componentes de la infraestructura que pueden depender los unos de los otros. Por ejemplo, A podría ser una caja de EC2 y B un depósito de S3. Las dependencias en las que un componente A (y solo A) de la infraestructura depende del componente B probablemente deben mantenerse juntas en la misma canalización de CI/CD. Las dependencias en las que A, B y C dependen de D, pero A, B y C son independientes, deben dividirse en varias canalizaciones de CI/CD. En este caso, cuatro canalizaciones independientes. En esta instancia, debes crear una canalización para D de la que dependan los otros tres componentes y una para cada uno de los componentes A, B y C.
Código
Las canalizaciones de CI/CD están diseñadas para implementar código. Estas canalizaciones suelen ser sencillas de implementar, ya que la infraestructura ya está disponible gracias al trabajo previo. Las consideraciones importantes a este respecto son las pruebas, la repetibilidad y la capacidad de recuperación de implementaciones incorrectas.
La "repetibilidad" es la capacidad de implementar el mismo cambio una y otra vez sin dañar el sistema. La implementación debe ser reentrante e idempotente. Una implementación debe establecer el estado de un sistema en una configuración conocida en lugar de aplicar un modificador al estado existente. La aplicación de un modificador no se puede repetir, ya que, tras la primera implementación, cambia el estado inicial para que el modificador funcione.
Un ejemplo sencillo de actualización no repetible es la de actualizar una configuración adjuntándole datos. No adjuntes filas a los archivos de configuración ni uses ninguna técnica de modificación de este tipo. Si las actualizaciones se llevan a cabo mediante adjuntos, el archivo de configuración puede acabar con docenas de filas duplicadas. En lugar de eso, sustituye el archivo de configuración con un archivo escrito correctamente desde el control del código fuente.
Este principio también debe aplicarse a la actualización de las bases de datos. Las actualizaciones de las bases de datos pueden ser problemáticas y requieren que se preste atención a los detalles. Es esencial que el proceso de actualización de la base de datos sea repetible y tolerante a fallos. Haz copias de seguridad inmediatamente antes de aplicar los cambios para que sea posible hacer una recuperación.
También hay que prestar especial atención a cómo recuperarse de una mala implementación. O bien la implementación falla y el sistema se encuentra en un estado desconocido, o bien la implementación se realiza correctamente, se activan las alarmas y empiezan a llegar tickets de incidencias. Hay dos formas generales de abordar esta situación. La primera es hacer una reversión. La segunda es utilizar marcas de función y desactivar las marcas necesarias para volver a un estado correcto conocido. Consulta el paso 8 de este artículo para obtener más información sobre las marcas de función.
Una reversión implementa el anterior estado correcto conocido a un entorno después de que se haya detectado una mala implementación. Esto debe planificarse desde el principio. Antes de tocar una base de datos, haz una copia de seguridad. Asegúrate de que puedes implementar rápidamente la versión anterior del código. Prueba el proceso de reversión con regularidad en entornos de prueba o ensayo.
Paso 7: añade supervisión, alarmas e instrumentación
Un equipo de DevOps tiene que supervisar el comportamiento de la aplicación que se ejecuta en cada entorno. ¿Hay errores en los registros? ¿Las llamadas a las API sobrepasan el tiempo de espera? ¿Las bases de datos fallan? Supervisa cada componente del sistema para ver si hay problemas. Si se detecta un problema, genera un ticket de incidencia para que alguien pueda resolverlo. Como parte de la resolución, escribe pruebas adicionales que permitan detectar el problema.
Corrección de errores
Supervisar y responder a los problemas forma parte de la ejecución de software de producción. Un equipo con una cultura de DevOps es propietario del funcionamiento del software y toma prestados los comportamientos de un ingeniero de fiabilidad del sitio (SRE). Analiza el origen del problema, luego escribe pruebas para detectarlo y soluciónalo; comprueba, también, que se superen las pruebas. Este proceso suele ser complicado desde el principio, pero sale a cuenta a largo plazo ya que reduce la deuda técnica y se mantiene la agilidad operativa.
Optimización del rendimiento
Una vez que se ha establecido la supervisión básica del estado, el siguiente paso suele ser el ajuste del rendimiento. Observa cómo funciona cada parte de un sistema y optimiza las partes lentas. Como señaló Knuth: "la optimización prematura es la raíz de todos los males". No optimices el rendimiento de todo lo que hay en el sistema. Optimiza solo las piezas más lentas y costosas. La supervisión ayuda a identificar qué componentes son lentos y costosos.
Paso 8: usa marcas de función para implementar las pruebas de valor controlado o canarias
Para habilitar las pruebas de valor controlado, incluye cada función en una marca de función con una lista de permisos que contenga a los usuarios de prueba. El nuevo código de función solo se ejecutará para los usuarios de la lista de permisos una vez implementado en un entorno. Deja que la nueva función se sumerja en cada entorno antes de promoverla al siguiente. Mientras la nueva función se sumerge en una región, presta atención a las métricas, las alarmas y demás instrumentos para detectar signos de algún problema. En particular, observa si hay un repunte en los tickets de incidencias.
Aborda los problemas en un entorno antes de hacer la prueba en el siguiente entorno. Los problemas que se encuentren en los entornos de producción deben gestionarse igual que los problemas en entornos de prueba o ensayo. Una vez identificada la causa principal del problema, escribe pruebas para identificar el problema, implementa una solución, comprueba que se superen las pruebas y promueve la solución a través de la canalización de CI/CD. Se superarán las nuevas pruebas y el recuento de tickets de incidencia disminuirá a medida que el cambio se produzca en el entorno en el que se detectó el problema.
Conclusión
Haz una retrospectiva del proyecto para trasladar el primer componente a DevOps. Identifica los puntos débiles o las partes que resultaron complicadas o difíciles. Amplía el plan para abordar estos puntos débiles y pasa al segundo componente.
Usar un enfoque de DevOps para llevar un componente a producción puede parecer una gran cantidad de trabajo al principio, pero sale a cuenta a largo plazo. Una vez se hayan sentado las bases, implementar el segundo componente debería resultar más fácil. Se puede usar el mismo proceso que para el primer componente y modificarlo ligeramente para el segundo, ya que se dispone de las herramientas, se entienden las tecnologías y el equipo está formado para trabajar al estilo de DevOps.
Para empezar tu viaje con DevOps, te recomendamos que pruebes Atlassian Open DevOps, una cadena de herramientas abierta e integrada con todo lo que necesitas para desarrollar y manejar software, y con la capacidad de integrar herramientas adicionales a medida que tus necesidades crezcan.
Compartir este artículo
Tema siguiente
Lecturas recomendadas
Consulta estos recursos para conocer los tipos de equipos de DevOps o para estar al tanto de las novedades sobre DevOps en Atlassian.

La comunidad de DevOps

Ruta de aprendizaje de DevOps