Teste Compass kostenlos
Als Unterstützung beim Entwickeln, zum Katalogisieren von Diensten und zum Optimieren des Softwarezustands.
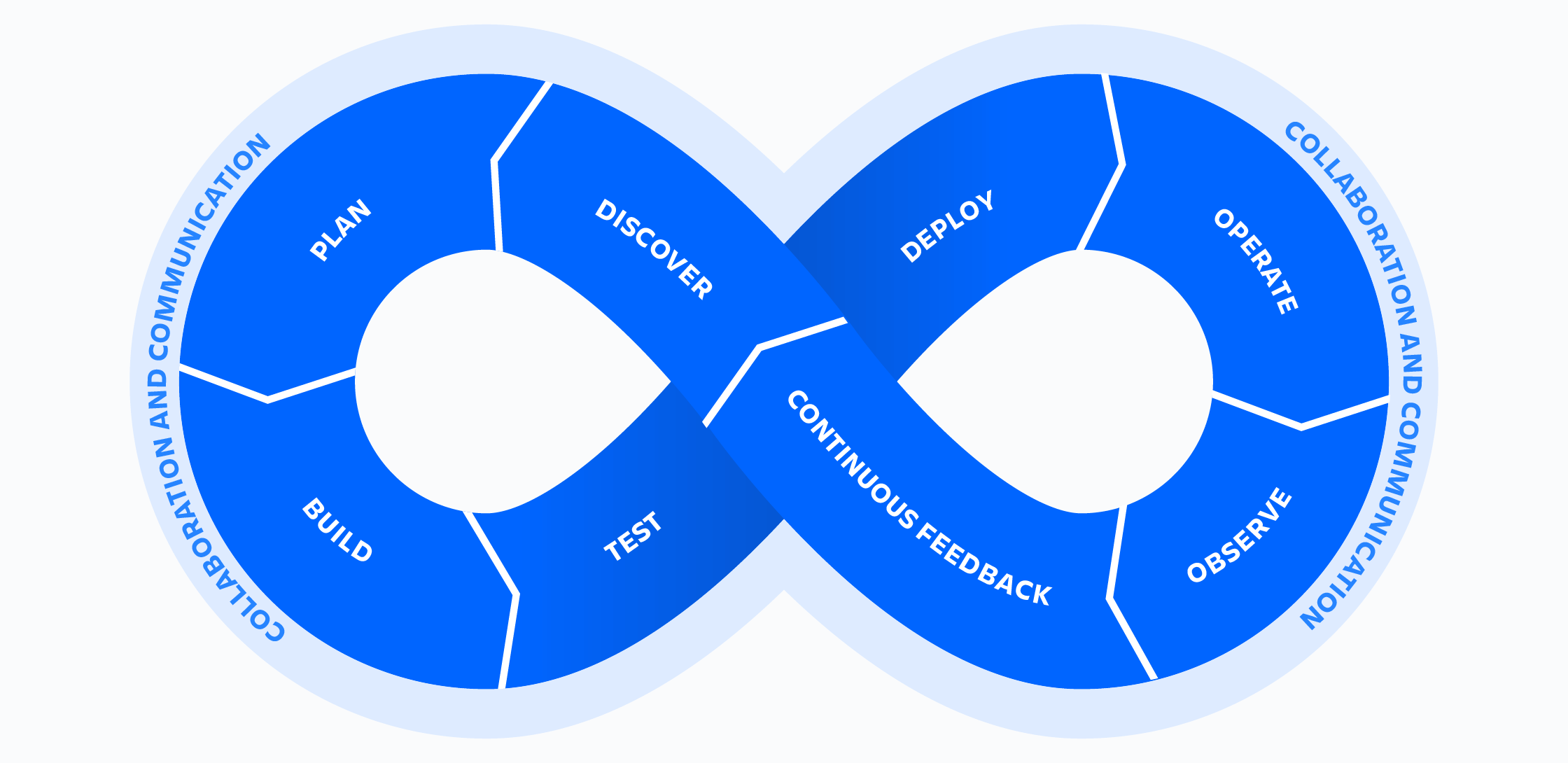
So funktioniert DevOps
Eine detaillierte Anleitung für Teams, die DevOps implementieren möchten
.png?cdnVersion=2661)
Warren Marusiak
Senior Technical Evangelist
Erscheint dir der Softwareentwicklungszyklus als verwirrendes Durcheinander von Tools und Workflows? Stecken deine Teams und Projekte in Silos fest? Falls du eine dieser Fragen mit "Ja" beantworten kannst, ist dies der perfekte Zeitpunkt, um DevOps in Erwägung zu ziehen. DevOps schafft eine neue Umgebung für die Softwareentwicklung und hilft dir so, die Workflows für Entwicklung und Deployment zu vereinfachen und zu optimieren.
Aber wie läuft die Implementierung von DevOps ab? Eine der größten Herausforderungen von DevOps ist die Tatsache, dass es keinen Standardprozess gibt, da jedes Team andere Bedürfnisse und Ziele hat. Die bloße Anzahl der DevOps-Tools und -Ressourcen kann zu einer "Analyselähmung" führen, was die Einführung erschwert. Die folgenden Schritte können deinem Team bei der Implementierung von DevOps helfen.
Warum DevOps?
Die kurze Antwort: DevOps steigert die Produktivität. Entwickler können sich mit DevOps auf das zu konzentrieren, was sie am besten können – fantastische Software entwickeln, anstatt Aufgaben von geringem Wert manuell ausführen, wie das Prüfen von Protokolldateien. DevOps-Praktiken automatisieren sich wiederholende Arbeiten wie das Ausführen von Tests und Deployments, das Überwachen von Produktionssoftware auf Probleme und das Entwickeln einer problemsicheren Deployment-Methode. Entwickler können in Ruhe entwickeln und experimentieren, was zu einer höheren Produktivität führt.
Es gibt viele Definitionen von DevOps. In diesem Artikel meint DevOps, dass ein Team für den gesamten Lebenszyklus einer Software verantwortlich ist. Ein DevOps-Team übernimmt den Entwurf, die Implementierung, das Deployment, die Überwachung, die Problembehebung und die Aktualisierung einer Software. Es besitzt den Code und die Infrastruktur, auf der dieser Code ausgeführt wird. Es ist nicht nur für die Endbenutzererfahrung verantwortlich, sondern auch für Produktionsprobleme.
Ein Grundsatz von DevOps ist es, einen Prozess zu entwickeln, der mögliche Probleme einberechnet und Entwickler befähigt, wirksam darauf zu reagieren. Ein DevOps-Prozess sollte Entwicklern nach jedem Deployment sofort Feedback über den Zustand des Systems geben. Je früher ein Problem entdeckt wird, desto geringer ist seine Auswirkung und desto eher kann das Team mit der nächsten Aufgabe fortfahren. Wenn es leichter ist, Änderungen bereitzustellen und Probleme zu beheben, können Entwickler experimentieren, entwickeln, veröffentlichen und neue Ideen ausprobieren.
Was DevOps nicht ist: Technologie. Wenn du DevOps-Tools kaufst und es DevOps nennst, spannst du den Karren vor das Pferd. Das Wesentliche an DevOps ist der Aufbau einer Kultur der geteilten Verantwortung, Transparenz und des schnelleren Feedbacks. Technologie ist nur das Werkzeug, um dies zu erreichen.
Zugehöriges Material
Kostenlos loslegen
Zugehöriges Material
Weitere Informationen zu bewährten DevOps-Methoden
Ein Hinweis
Jedes Team startet an einem anderen Ausgangspunkt und daher können einige der folgenden Schritte unter Umständen nicht zutreffen. Außerdem ist diese Liste nicht vollständig. Die hier dargestellten Schritte sind als Ausgangspunkt zu verstehen, um ein Team bei der Implementierung von DevOps zu unterstützen.
In diesem Artikel wird DevOps als Sammelbegriff für die Kultur, Prozesse und Technologien verwendet, mit denen DevOps funktioniert.
In 8 Schritten zu DevOps
Schritt 1: Wähle eine Komponente
Der erste Schritt ist, klein anzufangen. Suche dir eine Komponente aus, die gerade entwickelt wird. Die ideale Komponente hat eine einfache Codebasis mit wenigen Abhängigkeiten und minimaler Infrastruktur. Diese Komponente ist das Testgelände, auf dem sich das Team an der Implementierung von DevOps versucht.
Schritt 2: Erwäge die Einführung einer agilen Methode wie Scrum
DevOps wird oft mit einer agilen Arbeitsmethode kombiniert, beispielsweise mit Scrum. Es ist nicht notwendig, alle Rituale und Praktiken einzuführen, die mit einer Methode wie Scrum verbunden sind. Diese drei Elemente von Scrum sind im Allgemeinen leicht zu übernehmen und zeigen schnell ihren Wert: Backlog, Sprint und Sprint-Planung.
Ein DevOps-Team kann Arbeit einem Scrum-Backlog hinzufügen und priorisieren und dann einen Teil dieser Arbeit in einen Sprint einbinden – eine feste Zeitspanne, in der bestimmte Aufgaben erledigt werden. Sprint-Planung ist der Prozess, bei dem entschieden wird, welche Aufgaben aus dem Backlog in den nächsten Sprint übertragen werden.
Schritt 3: Verwende eine Git-basierte Quellcodeverwaltung
Die Versionskontrolle ist eine bewährte DevOps-Methode, die eine bessere Zusammenarbeit und schnellere Release-Zyklen ermöglicht. Tools wie Bitbucket ermöglichen es Entwicklern, Software zu teilen, daran zusammenzuarbeiten, sie zusammenzuführen und zu sichern.
Wähle ein Branching-Modell. Dieser Artikel gibt einen Überblick über das Konzept. GitHub-Flow ist einfach zu verstehen und zu implementieren und daher ein guter Ausgangspunkt für Teams, die neu bei Git sind. Trunk-basierte Entwicklung wird oft bevorzugt, erfordert aber mehr Disziplin und erschwert die ersten Annäherungsversuche an Git.
Schritt 4: Integriere Quellcodeverwaltung mit Arbeitsverfolgung
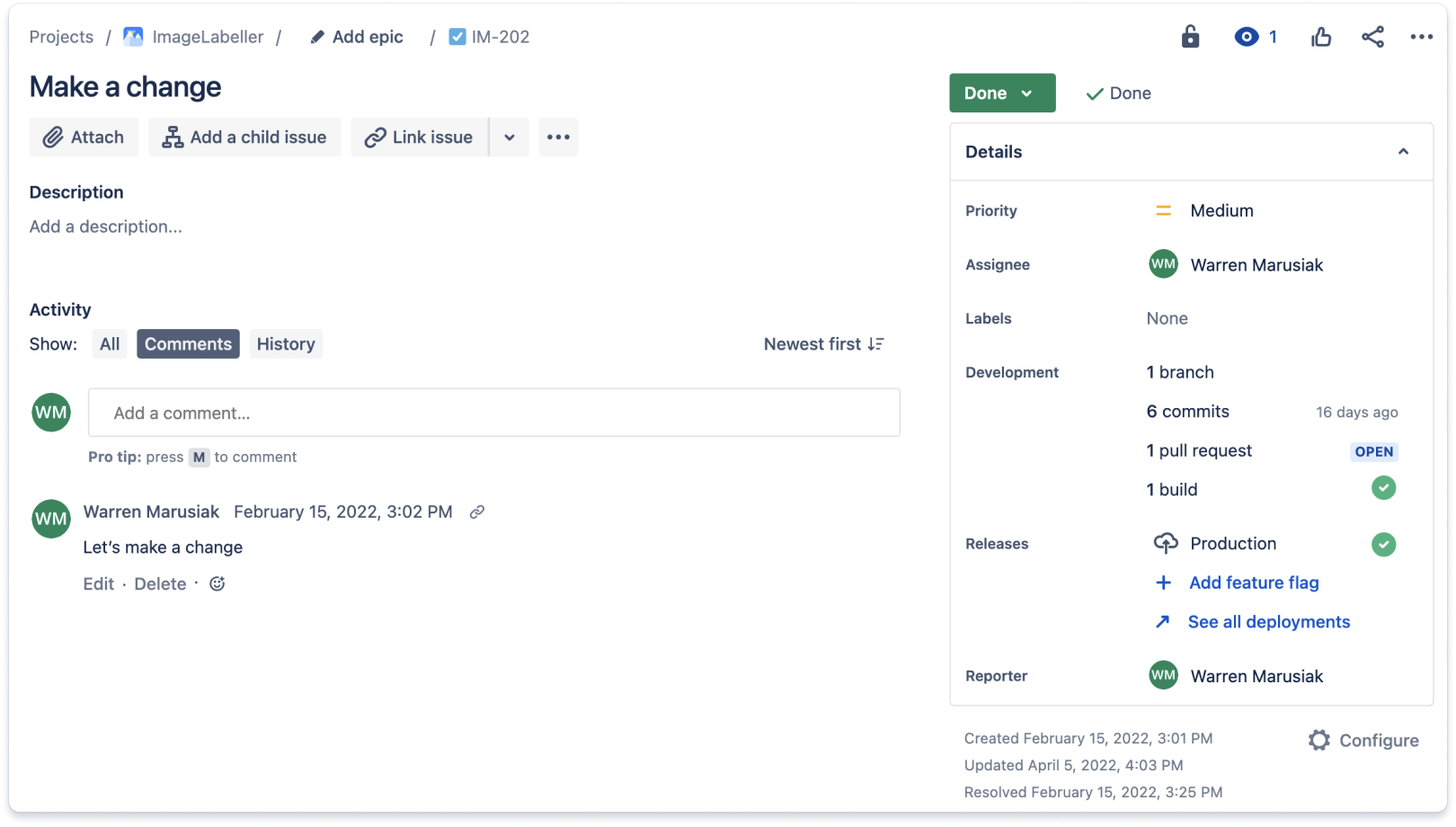
Integriere das Tool zur Quellcodeverwaltung in das Tool zur Vorgangsverfolgung. Wenn Entwickler und Management alles, was mit einem bestimmten Projekt zu tun hat, an einem Ort sehen können, sparen sie erheblich Zeit. Unten ist ein Beispiel für einen Jira-Vorgang mit Updates von einem Git-basierten Quellcodeverwaltungs-Repository abgebildet. Jira-Vorgänge beinhalten einen Entwicklungsbereich, der die für den Jira-Vorgang geleistete Arbeit in der Quellcodeverwaltung zusammenfasst. Dieser Vorgang hatte einen einzelnen Branch, sechs Commits, eine Pull-Anfrage und einen einzigen Build.
Weitere Informationen findest du, wenn du dir den Entwicklungsabschnitt eines Jira-Vorgangs genauer ansiehst. Die Commit-Registerkarte listet alle Commits auf, die mit einem Jira-Vorgang verbunden sind.
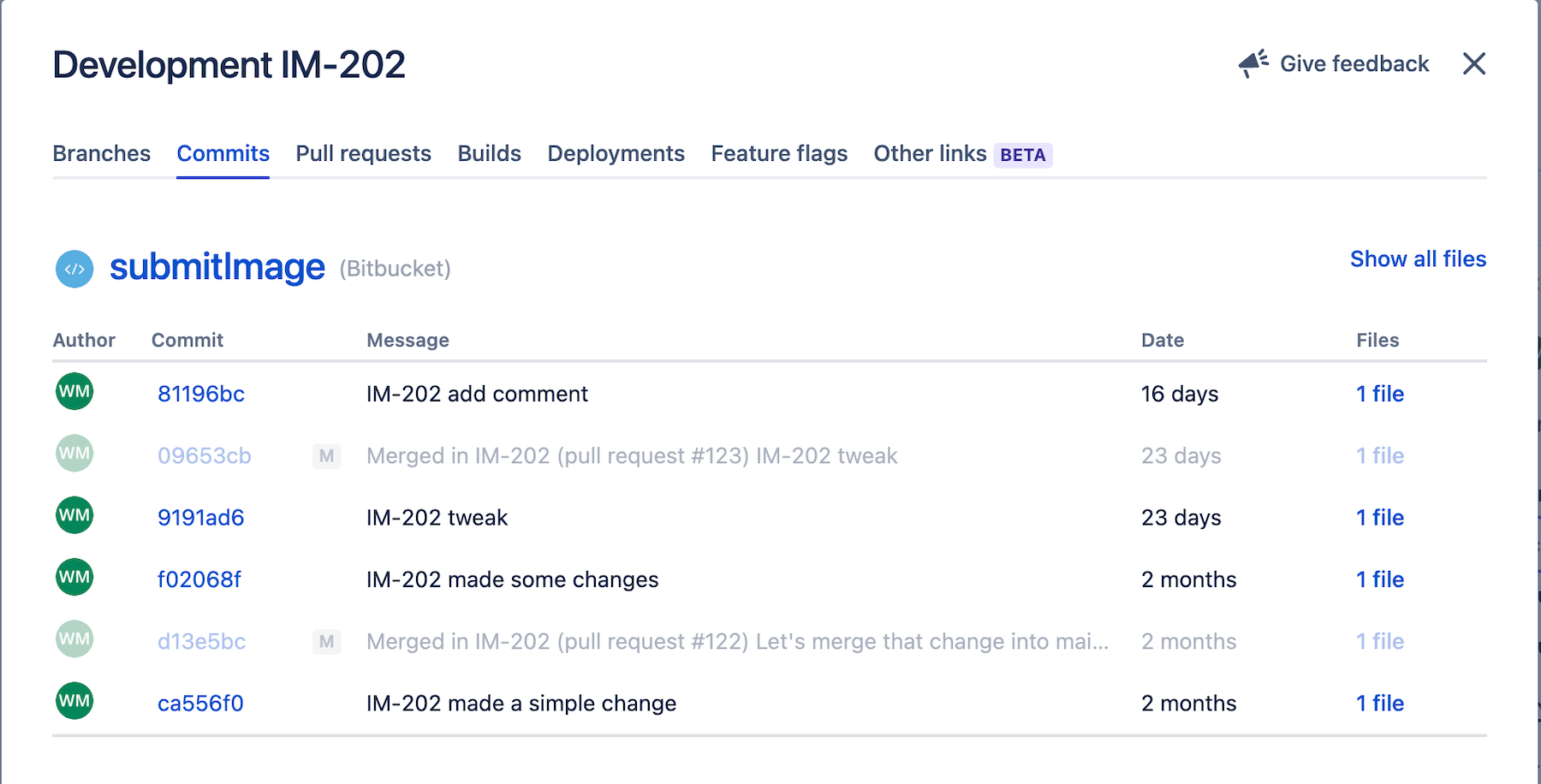
Dieser Abschnitt listet alle Pull-Anfragen auf, die mit dem Jira-Vorgang verbunden sind.
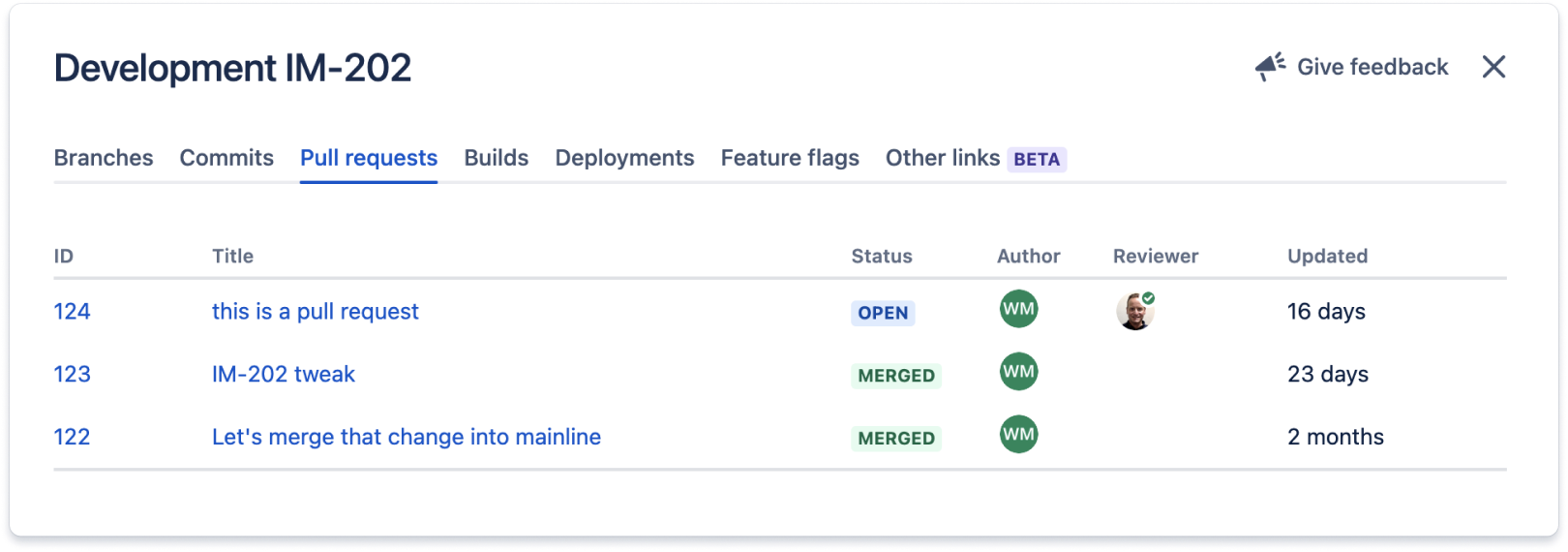
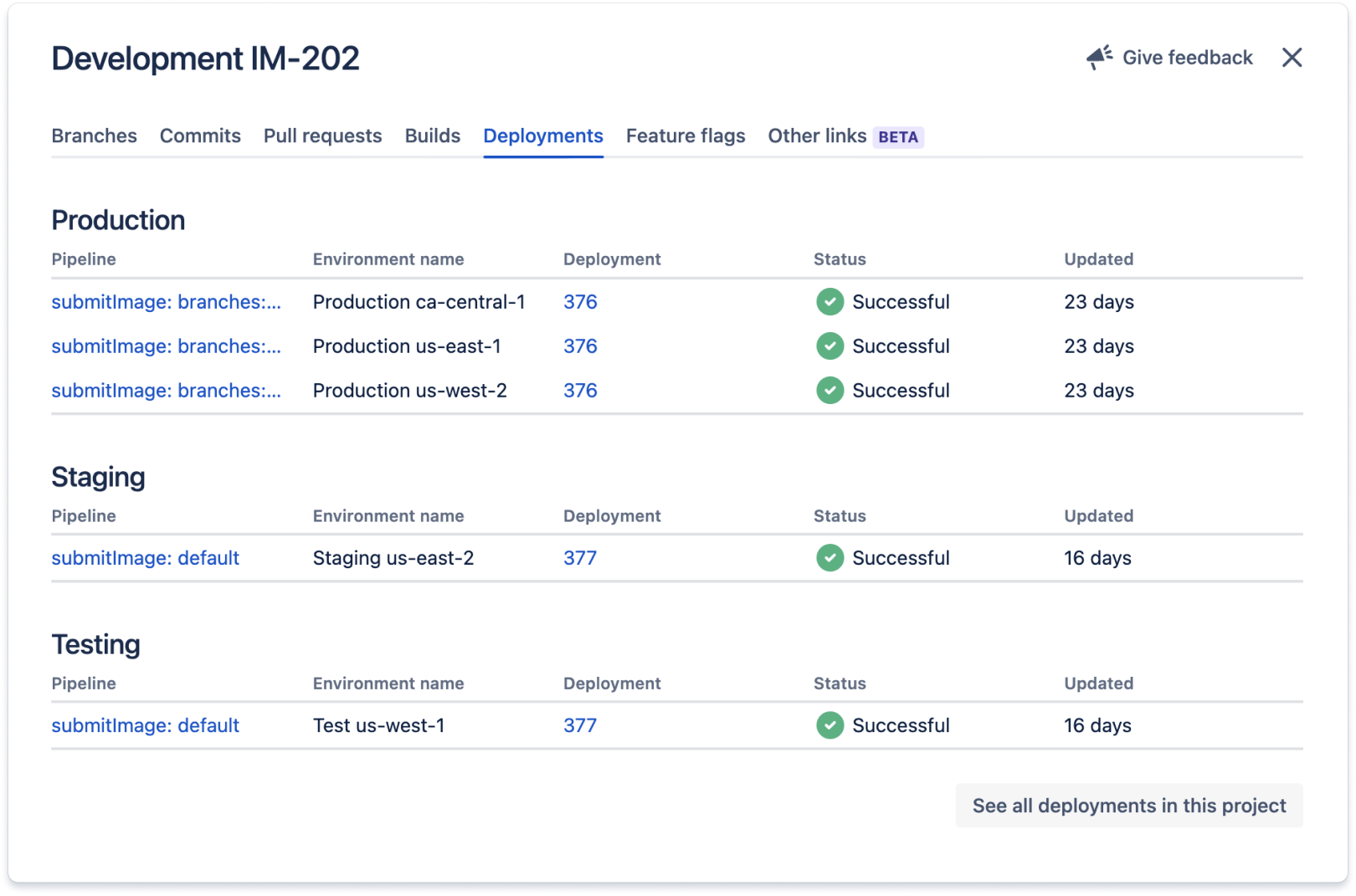
Der Code zu diesem Jira-Vorgang wird in allen Umgebungen bereitgestellt, die im Deployment-Abschnitt aufgeführt sind. Diese Integrationen funktionieren normalerweise, indem die ID des Jira-Vorgangs – in diesem Fall IM-202 – hinzugefügt wird, um Nachrichten und Branch-Namen, die mit dem Jira-Vorgang zusammenhängen, zu committen.
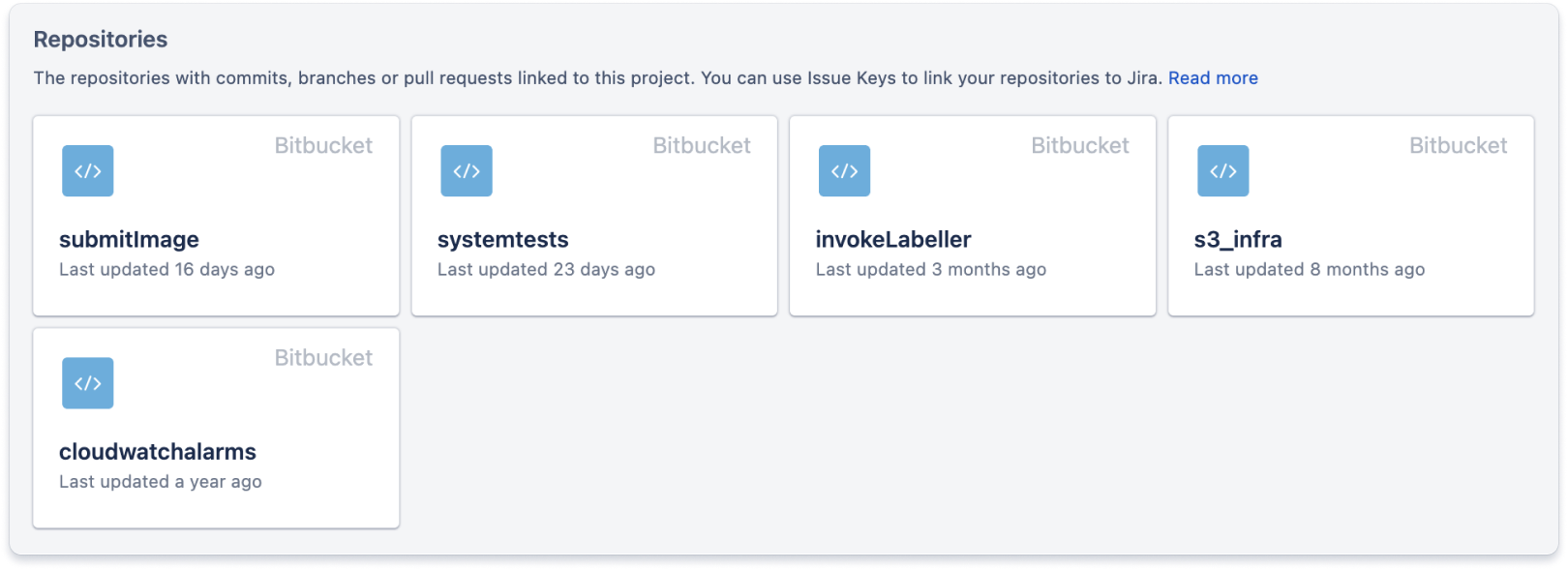
Eine Code-Registerkarte enthält Links zu allen mit dem Projekt verbundenen Quellcode-Repositorys. So können Entwickler den Code, an dem sie arbeiten müssen, leichter finden, wenn sie sich selbst einen Jira-Vorgang zuweisen.
Schritt 5: Tests schreiben
CI/CD-Pipelines benötigen Tests, um zu überprüfen, ob der in verschiedenen Umgebungen bereitgestellte Code korrekt funktioniert. Beginne damit, Unit-Tests für den Code zu schreiben. Eine 90-prozentige Codeabdeckung ist zwar ein ehrgeiziges Ziel, aber für den Anfang unrealistisch. Lege eine niedrige Baseline für die Codeabdeckung fest und hebe die Messlatte für die Unit-Testabdeckung im Laufe der Zeit schrittweise an. Dafür kannst du dem Backlog Aufgabenelemente hinzufügen.
Setze auf eine testgetriebene Entwicklung, wenn du Bugs im Produktionscode behebst. Wenn du einen Bug findest, schreibe Unit-Tests, Integrationstests und/oder Systemtests, die in Umgebungen fehlschlagen, in denen der Bug live ist. Behebe dann den Bug und beobachte, ob die Tests jetzt erfolgreich sind. Dieser Prozess wird die Codeabdeckung im Laufe der Zeit ganz natürlich steigern. Falls der Bug in einer Test- oder Staging-Umgebung entdeckt wurde, erhältst du mit den Tests die Gewissheit, dass der Code ordnungsgemäß funktioniert, wenn er zur Produktion hochgestuft wird.
Wenn man ganz von vorne beginnt, ist dieser Schritt sehr arbeitsintensiv, aber wichtig. Anhand von Tests können Teams die Auswirkungen von Codeänderungen im System beobachten, ehe die Änderungen an den Kunden weitergeleitet werden.
Unit-Tests
Unit-Tests überprüfen, ob der Quellcode korrekt ist und sollten als einer der ersten Schritte in einer CI/CD-Pipeline ausgeführt werden. Entwickler sollten Tests für den Green Path, problematische Eingaben und bekannte Fallbeispiele schreiben. Beim Schreiben von Tests können Entwickler die Eingaben und erwarteten Ausgaben simulieren.
Integrationstests
Integrationstests überprüfen, ob zwei Komponenten korrekt miteinander kommunizieren. Simuliere die Eingaben und erwarteten Ausgaben. Diese Tests sind einer der ersten Schritte einer CI/CD-Pipeline vor der Bereitstellung in einer beliebigen Umgebung. Sie erfordern in der Regel umfangreichere Simulationen als Unit-Tests, damit sie funktionieren.
Systemtests
Systemtests überprüfen die End-to-End-Leistung des Systems und geben Gewissheit, dass das System in jeder Umgebung erwartungsgemäß funktioniert. Simuliere die Eingabe, die eine Komponente erhalten könnte, und führe das System aus. Überprüfe als Nächstes, ob das System die nötigen Werte zurückgibt und den Rest des Systems korrekt aktualisiert. Diese Tests sollten nach dem Deployment zu jeder Umgebung ausgeführt werden.
Schritt 6: Baue einen CI/CD-Prozess für das Deployment der Komponente auf
Erwäge das Deployment in mehrere Umgebungen, wenn du eine CI-CD-Pipeline aufbaust. In einer CI/CD-Pipeline, bei der ein Deployment nur in eine einzige Umgebung erfolgt, besteht eher die Tendenz, dass Dinge fest codiert werden. Es ist wichtig, CI/CD-Pipelines für Infrastruktur und Code zu erstellen. Beginne mit dem Aufbau einer CI/CD-Pipeline, um die notwendige Infrastruktur in jeder Umgebung bereitzustellen. Entwickle dann eine weitere CI/CD-Pipeline, um den Code bereitzustellen.
Pipeline-Struktur
Diese Pipeline beginnt mit dem Ausführen von Unit-Tests und Integrationstests, bevor der Code in der Testumgebung bereitgestellt wird. Systemtests werden nach dem Deployment in eine Umgebung ausgeführt.
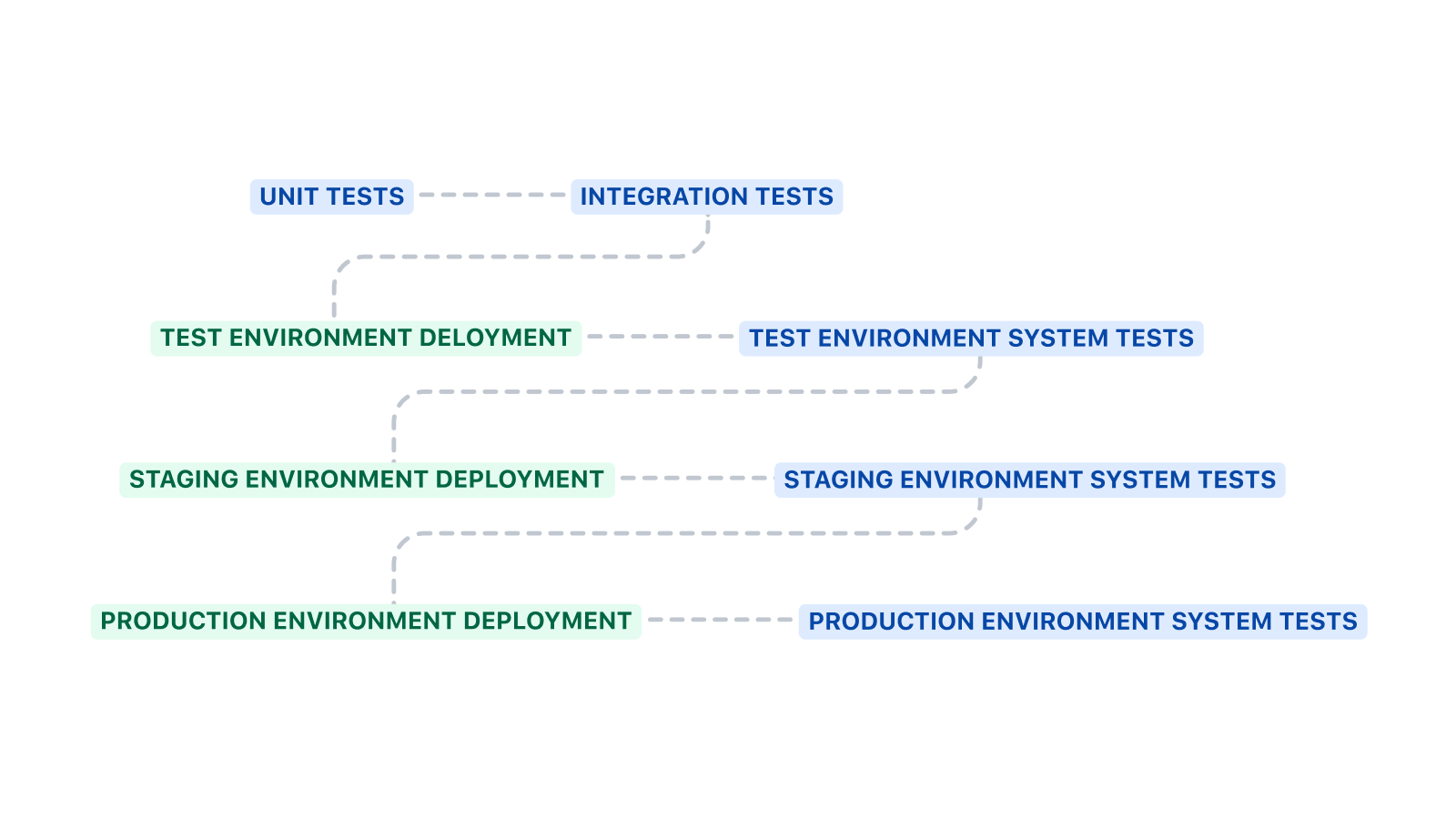
Die obige grobe Vorlage kann auf verschiedene Arten erweitert werden. Code-Linting, statische Analyse und Sicherheitsscans sind gute zusätzliche Schritte, die vor Unit- und Integrationstests durchgeführt werden können. Code-Linting kann Codierungsstandards durchsetzen, statische Analysen können auf Anti-Patterns prüfen und Sicherheitsscans können vorhandene Schwachstellen finden.
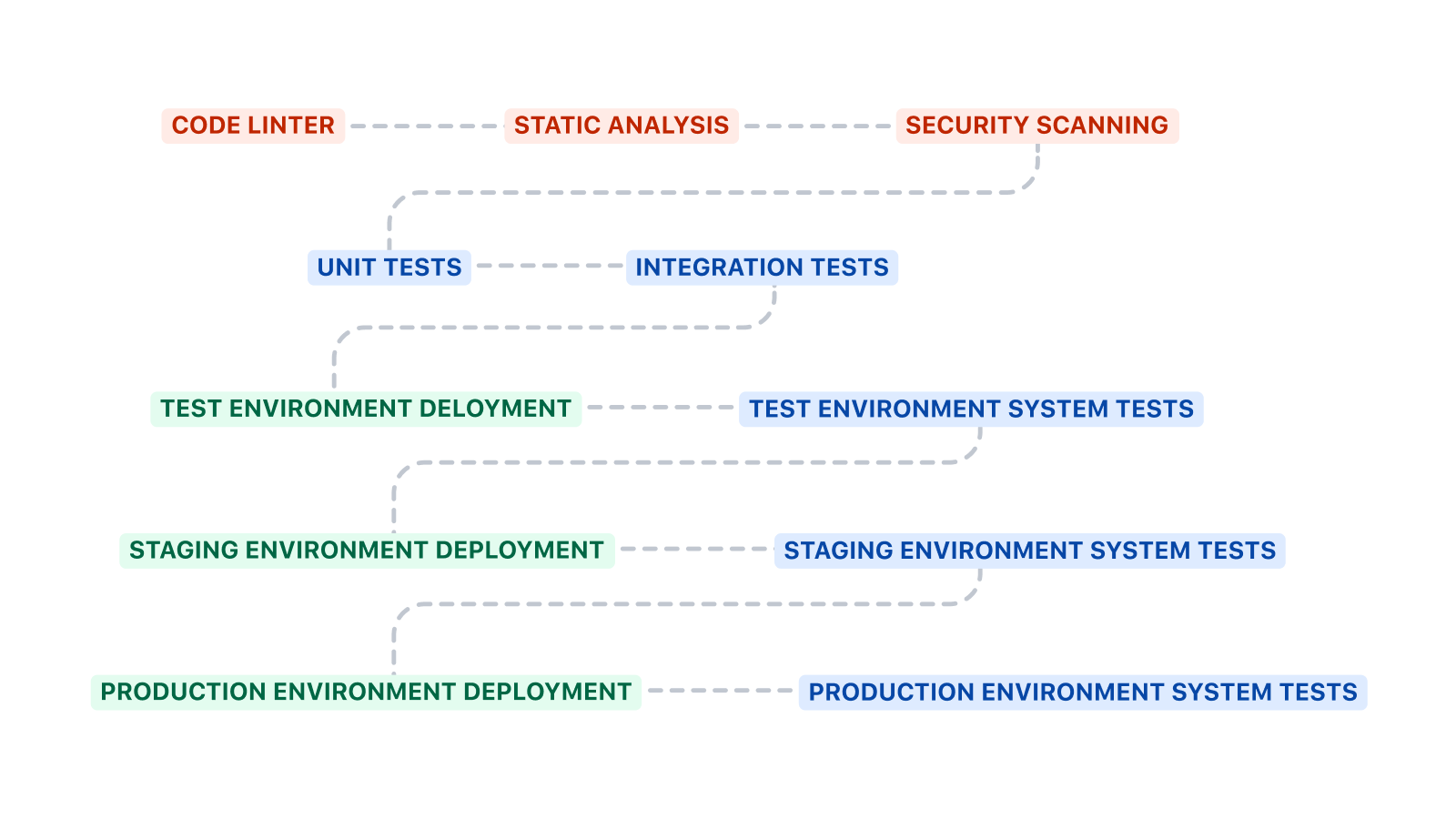
Die CI/CD-Pipelines für das Deployment von Infrastruktur und Code sind wahrscheinlich unterschiedlich. Die CI/CD-Pipeline für Infrastruktur hat oft keine Unit- oder Integrationstests. Nach jedem Deployment werden Systemtests durchgeführt, um sicherzustellen, dass das System noch funktioniert.
Infrastruktur
Unterschiede in der Infrastruktur zwischen den Umgebungen erschweren die korrekte Ausführung der Software in der jeweiligen Umgebung. Firewall-Regeln, Benutzerberechtigungen, Datenbankzugriff und andere Komponenten auf Infrastrukturebene müssen in einer bekannten Konfiguration vorliegen, damit die Software ordnungsgemäß ausgeführt werden kann. Es kann schwierig sein, das manuelle Infrastruktur-Deployment korrekt zu wiederholen. Da der Prozess viele Schritte umfasst, kann es zu Fehlern kommen, jeder Schritt in der richtigen Reihenfolge und mit den richtigen Parametern ausgeführt werden muss. Infrastruktur muss, wo immer möglich, im Code definiert werden, um diesen und anderen Problemen entgegenzuwirken.
Infrastruktur kann mit einer Vielzahl von Tools im Code definiert werden, darunter AWS CloudFormation, Terraform, Ansible, Puppet oder Chef.
Schreibe mehrere Pipelines, um die Infrastruktur bereitzustellen. Wie beim Schreiben von Code ist es hilfreich, das Infrastruktur-Deployment modular zu halten. Zerlege die erforderliche Infrastruktur, soweit möglich, in unzusammenhängende Untergruppen. Angenommen, A, B, C und D sind Abstraktionen für Infrastrukturkomponenten, die voneinander abhängig sein können. A könnte eine EC2-Box sein und B ein S3-Bucket. Abhängigkeiten, bei denen Infrastrukturkomponente A – und nur A – von Komponente B abhängt, sollten wahrscheinlich in derselben CI/CD-Pipeline zusammengehalten werden. Abhängigkeiten, bei denen A, B und C von D abhängen – aber A, B und C unabhängig sind –, sollten in mehrere CI/CD-Pipelines aufgeteilt werden. In diesem Beispiel in vier unabhängige Pipelines. Du solltest eine Pipeline für D aufbauen, von der alle drei anderen Komponenten abhängen, und jeweils eine für A, B und C.
Code
CI/CD-Pipelines werden für das Deployment von Code entwickelt. Die Implementierung dieser Pipelines ist normalerweise einfach, da die Infrastruktur aufgrund früherer Arbeit bereits verfügbar ist. Wichtige Überlegungen sind Tests, Wiederholbarkeit und die Möglichkeit, nach schlecht funktionierenden Deployments weiterzumachen.
Wiederholbarkeit ist die Fähigkeit, dieselbe Änderung immer und immer wieder bereitzustellen, ohne das System zu beschädigen. Das Deployment sollte eintrittsinvariant und idempotent sein. Ein Deployment sollte den Zustand eines Systems auf eine bekannte Konfiguration setzen, anstatt einen Modifikator auf den vorhandenen Status anzuwenden. Das Anwenden eines Modifikators kann nicht wiederholt werden, da sich nach dem ersten Deployment der Startzustand geändert hat, der für die ordnungsgemäße Funktion des Modifikators notwendig ist.
Ein einfaches Beispiel für ein nicht wiederholbares Update ist das Aktualisieren einer Konfigurationsdatei durch Anhängen von Daten. Hänge daher keine Zeilen an Konfigurationsdateien an und verwende auch keine ähnliche Modifizierungstechnik. Wenn Updates über Anhänge erfolgen, kann es passieren, dass eine Konfigurationsdatei am Ende Dutzende doppelter Zeilen enthält. Ersetze stattdessen die Konfigurationsdatei durch eine korrekt geschriebene Datei aus der Quellcodeverwaltung.
Dieses Prinzip sollte auch bei der Aktualisierung von Datenbanken angewendet werden. Datenbank-Updates können problematisch sein und benötigen detailgenaue Arbeit. Es ist wichtig, dass der Prozess des Datenbank-Updates wiederholbar und fehlertolerant ist. Erstelle Backups unmittelbar vor der Anwendung von Änderungen, damit eine Wiederherstellung möglich ist.
Eine weitere Überlegung ist der Umgang mit einem gescheiterten Deployment. Entweder das Deployment ist fehlgeschlagen und das System befindet sich in einem unbekannten Zustand, oder das Deployment war erfolgreich, Alarme werden ausgelöst und Fehlertickets laufen ein. Es gibt allgemein zwei Möglichkeiten, damit umzugehen. Die erste ist ein Rollback. Die zweite besteht darin, Feature-Flags zu verwenden und die erforderlichen Flags zu deaktivieren, um zu einem bekannten funktionierenden Zustand zurückzukehren. Weitere Informationen zu Feature-Flags findest du in Schritt 8 dieses Artikels.
Ein Rollback stellt den vorherigen bekannten guten Zustand in einer Umgebung wieder her, nachdem ein fehlerhaftes Deployment erkannt wurde. Hierfür sollte zu Beginn geplant werden. Erstelle ein Backup, ehe du eine Datenbank veränderst. Stelle sicher, dass du die vorherige Version des Codes schnell bereitstellen kannst. Teste den Rollback-Prozess regelmäßig in Test- oder Staging-Umgebungen.
Schritt 7: Füge Überwachung, Alarme und Instrumentierung hinzu
Ein DevOps-Team muss das Verhalten der laufenden Anwendung in jeder Umgebung überwachen. Gibt es Fehler in den Protokollen? Erreichen API-Aufrufe das Zeitlimit? Stürzen Datenbanken ab? Überwache jede Komponente des Systems auf Probleme. Wird bei der Überwachung ein Problem entdeckt, erstelle ein Ticket, damit jemand sich darum kümmern kann. Schreibe als Teil der Lösung zusätzliche Tests, die das Problem erkennen können.
Fehlerbehebungen
Es gehört zum Ausführen von Produktionssoftware dazu, diese zu überwachen und auf Probleme zu reagieren. Ein Team mit einer DevOps-Kultur ist verantwortlich für den Betrieb der Software und übernimmt auch die Rolle eines Site Reliability Engineer (SRE). Führe eine Ursachenanalyse des Problems durch, schreibe Tests, um das Problem zu erkennen, behebe es und stelle dann sicher, dass die Tests erfolgreich abgeschlossen werden. Dieser Prozess ist im Vorfeld oft mühsam, zahlt sich aber auf lange Sicht aus, da er technische Schulden reduziert und die betriebliche Agilität erhalten bleibt.
Leistungsoptimierung
Sobald die grundlegende Zustandsüberwachung eingerichtet ist, ist die Leistungsoptimierung oft der nächste Schritt. Sieh dir an, wie jeder Teil eines Systems ausgeführt wird und optimiere die langsamen Teile. Wie Knuth bemerkte: „Voreilige Optimierung ist die Wurzel allen Übels.“ Optimiere nicht die Leistung aller Teile eines Systems. Optimiere nur die langsamsten und teuersten Teile. Durch Beobachten kannst du feststellen, welche Komponenten langsam und teuer sind.
Schritt 8: Canary Testing mit Feature-Flags
Um Canary Testing zu aktivieren, muss jede neue Funktion in eine Feature-Flag mit einer Zulassungsliste gekapselt sein, die Testbenutzer enthält. Nach dem Deployment in eine Umgebung wird der neue Funktionscode nur für die Benutzer in der Zulassungsliste ausgeführt. Lass die neue Funktion in jeder Umgebung erst einsickern, bevor du sie in der nächsten einführst. Beobachte in dieser Zeit Metriken, Alarme und andere Instrumentierungen, um Anzeichen für Probleme zu erkennen. Achte besonders auf einen Anstieg an Problemtickets.
Kümmere dich um Probleme in einer Umgebung, ehe Funktionen zur nächsten Umgebung geschickt werden. Probleme, die in Produktionsumgebungen auftreten, sollten genauso behandelt werden wie Probleme in Test- oder Staging-Umgebungen. Hast du die Grundursache des Problems gefunden, schreibe Tests, um das Problem zu identifizieren, implementiere einen Fix, überprüfe, ob die Tests bestanden werden, und schicke das Update über die CI/CD-Pipeline weiter. Die neuen Tests werden bestanden und die Anzahl der Tickets sinkt, solange die Änderungen in der Umgebung aktiv sind, in der das Problem entdeckt wurde.
Fazit
Erstelle eine Retrospektive des Projekts für das Verschieben der ersten Komponente zu DevOps. Identifiziere die Problembereiche oder Teile, die herausfordernd oder schwierig waren. Passe den Plan an, um diese Problembereiche zu beheben, und fahre dann mit der zweiten Komponente fort.
Es mag am Anfang sehr arbeitsintensiv erscheinen, eine Komponente mit einem DevOps-Ansatz in die Produktion zu bringen, aber es wird sich später auszahlen. Die Implementierung der zweiten Komponente sollte einfacher sein, nachdem die Grundlagen geschaffen wurden. Für die zweite Komponente kann mit leichten Modifizierungen der gleiche Prozess wie für die erste verwendet werden, da die Tools vorhanden sind, die Technologie bekannt ist und das Team für die Arbeit in DevOps geschult wurde.
Für den Start mit DevOps empfehlen wir dir, Atlassian Open DevOps auszuprobieren, eine integrierte und offene Toolkette mit allem, was du für die Entwicklung und den Betrieb von Software benötigst. Außerdem ist es möglich, weitere Tools zu integrieren, wenn sich deine Anforderungen ändern.
Diesen Artikel teilen
Nächstes Thema
Lesenswert
Füge diese Ressourcen deinen Lesezeichen hinzu, um mehr über DevOps-Teams und fortlaufende Updates zu DevOps bei Atlassian zu erfahren.

DevOps-Community

DevOps-Lernpfad