Compass を無料で試す
開発者のエクスペリエンスを向上させ、すべてのサービスをカタログ化し、ソフトウェアの健全性を高めましょう。
記事
チュートリアル
インタラクティブ ガイド
DevOps の手順
DevOps の実装を希望するチーム向けのステップバイステップ ガイド
.png?cdnVersion=2659)
Warren Marusiak
シニア テクニカル エバンジェリスト
ソフトウェア開発ライフサイクルがツールやワークフローで乱雑になっていますか? チームやプロジェクトがサイロ化されていますか? これらの質問のいずれかの答えが「はい」の場合、DevOps を検討する最適な時期です。DevOps によって、新しいソフトウェア開発エコシステムを作成することで、開発やデプロイのワークフローを簡素化および最適化できるようになります。
しかし、どのように DevOps を実装するのでしょうか? DevOps の主な課題の 1 つは、チームごとにニーズや目標が異なるために、標準プロセスがないということです。DevOps ツールとリソースの数が非常に多いことで「分析麻痺」に陥り、採用が妨げられてしまう可能性があります。チームが DevOps を実装するには、次のステップが役立ちます。
DevOps を選ぶ理由
簡単に言えば、DevOps では開発者が最も得意とする作業を行えるようにすることで生産性を向上させます。手動でログ ファイルを確認するなど、価値の低い作業を手動で実行するのではなく、優れたソフトウェアを構築できます。DevOps プラクティスによって、テストやデプロイの実行、本番ソフトウェアの問題の監視、問題に対する回復力のあるデプロイ手法などの反復的な作業が自動化できます。開発者が構築や実験を行えるようになるため、生産性が向上します。
DevOps にはさまざまな定義があります。この記事では、DevOps とはチームがソフトウェアのライフサイクル全体を管理するということです。DevOps チームが設計、実装、デプロイ、監視、問題の修正、ソフトウェアの更新を行い、コードや、コードが実行されるインフラストラクチャを管理します。DevOps チームはエンドユーザー エクスペリエンスだけでなく、本番での問題に関しても責任を負います。
DevOps の理念は、問題を予測し、開発者がその問題に効果的に対処できるようにするプロセスを構築することです。DevOps プロセスでは、各デプロイ後のシステムの健全性に関して開発者に素早くフィードバックを提供する必要があります。問題発生の発見が早ければ早いほど、影響は小さくなり、チームはより迅速に次の作業に進むことができます。変更のデプロイや問題からの回復が容易であれば、開発者は新しいアイデアを実験、構築、リリース、試行することができます。
DevOps は、テクノロジーではありません。DevOps ツールを購入し、それを DevOps と呼ぶというのは、本末転倒です。DevOps の本質は、責任の共有と透明性が実現されてスピーディーなフィードバックが行われる文化を形成することです。テクノロジーは、単にこれを可能にするツールにすぎません。
関連資料
無料で始める
関連資料
DevOps のベスト プラクティスに関する詳細
免責事項
すべてのチームには独自の出発点があるため、次のステップの一部は適用されない場合があります。また、このリストではすべてを網羅していません。ここでご紹介するステップは、チームが DevOps を実装する際に役立つ出発点となるものです。
この記事では、DevOps を実現させる文化、プロセス、テクノロジーの総称として DevOps を使用しています。
DevOps への 8 つのステップ
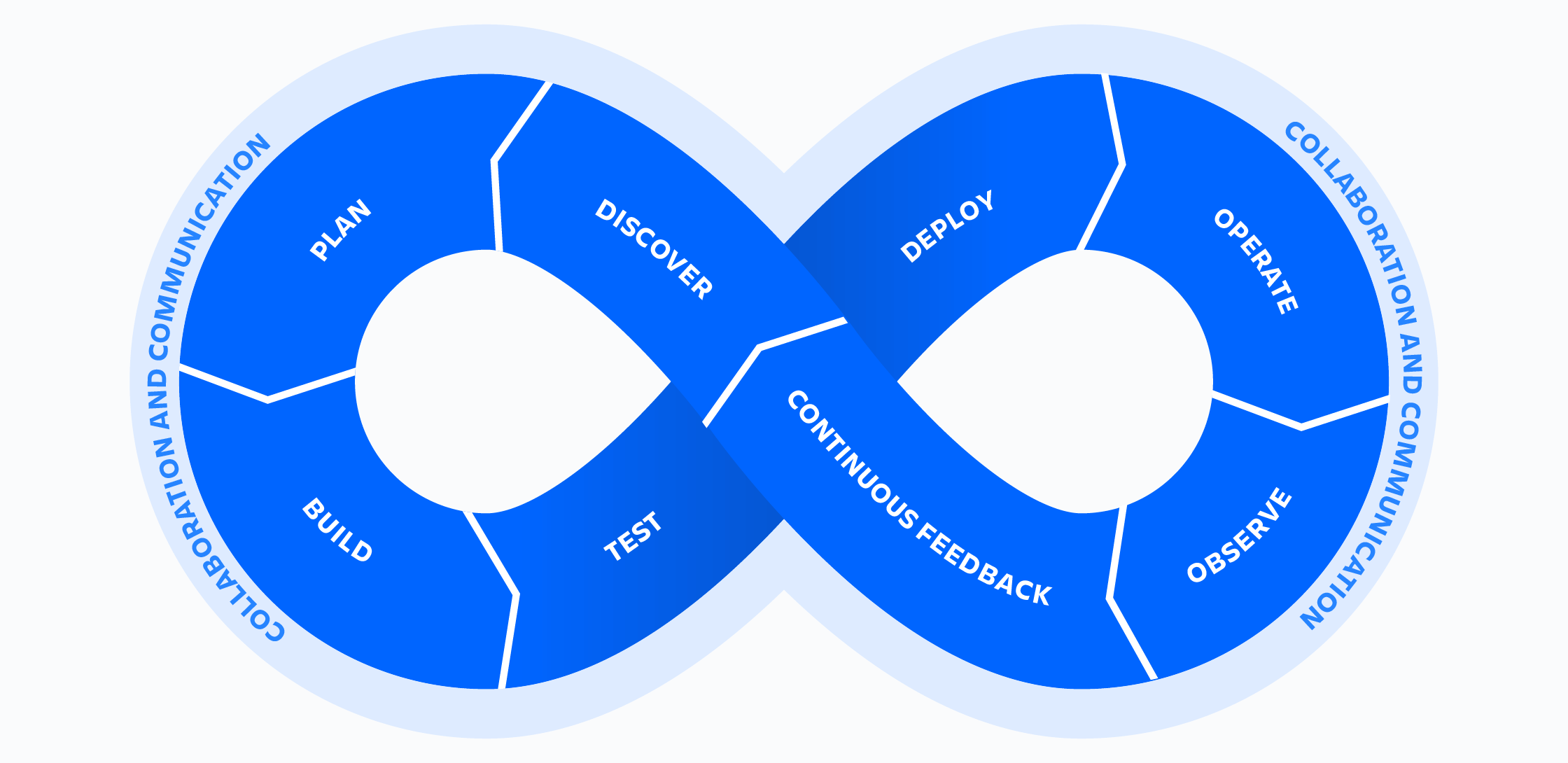
ステップ 1: コンポーネントを選択する
最初のステップは小さく始めます。現在の本番環境のコンポーネントを選択します。理想的なコンポーネントは、依存関係がほとんどなく、最小限のインフラストラクチャを備えたシンプルなコード ベースです。このコンポーネントは、チームが DevOps の実装で経験を積む場所になります。
ステップ 2: スクラムなどのアジャイル手法の採用を検討する
DevOps では多くの場合、アジャイル作業手法 (スクラムなど) を組み合わせます。スクラムのような方法に関連するすべての日課やプラクティスを採用する必要はありません。一般的に採用しやすく、すぐに価値を与えるスクラムの 3 つの要素は、バックログ、スプリント、スプリント計画です。
DevOps チームは、スクラム バックログに作業を追加して優先順位付けし、その作業のサブセットをスプリントにまとめ、一定の時間をかけて特定の作業を完了できます。スプリント計画は、バックログから次のスプリントに移行するタスクを決定するプロセスです。
ステップ 3: Git ベースのソース管理を使用する
バージョン管理は、コラボレーションを促進し、リリース サイクルを短縮できる DevOps のベスト プラクティスです。Bitbucket などのツールによって、開発者はソフトウェアの共有、コラボレーション、マージ、バックアップが可能になります。
ブランチ モデルを選択します。この記事では、このコンセプトの概要を説明しています。GitHub フローは、わかりやすく、実装も簡単なため、Git をこれまで使ったことがないチームにとって、適切な出発点です。多くの場合、トランクベース開発が好まれますが、より多くの規律が必要となるため、Git への最初の一歩がより困難になります。
ステップ 4: ソース管理と作業追跡を統合する
ソース管理ツールと作業追跡ツールを統合します。特定のプロジェクトに関連するすべての内容を 1 か所で確認することで、開発者と経営管理者は時間を大幅に節約できます。Git ベースのソース管理リポジトリからの更新を伴う Jira 作業項目の例を以下に示します。Jira 作業項目には、ソース管理での Jira 作業項目に対して実行された作業を集約する開発セクションが含まれます。この課題には、単一のブランチ、6 つのコミット、1 つのプル リクエスト、単一のビルドがありました。
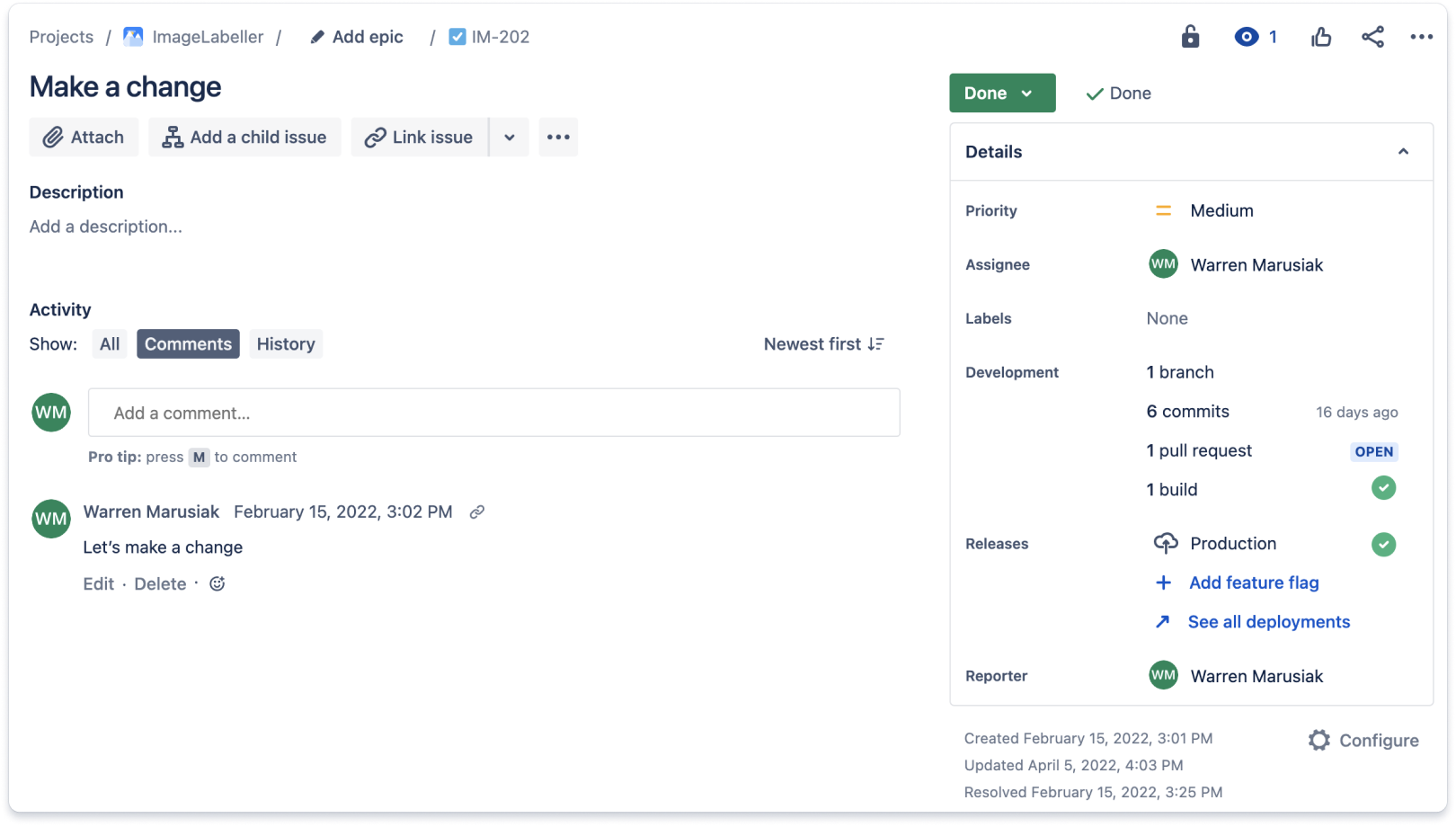
Jira 作業項目の開発セクションを掘り下げると、その他の詳細を確認できます。コミット タブには、Jira 作業項目に関連するすべてのコミットが一覧表示されます。

このセクションには、Jira 作業項目に関連するすべてのプル リクエストが一覧表示されます。
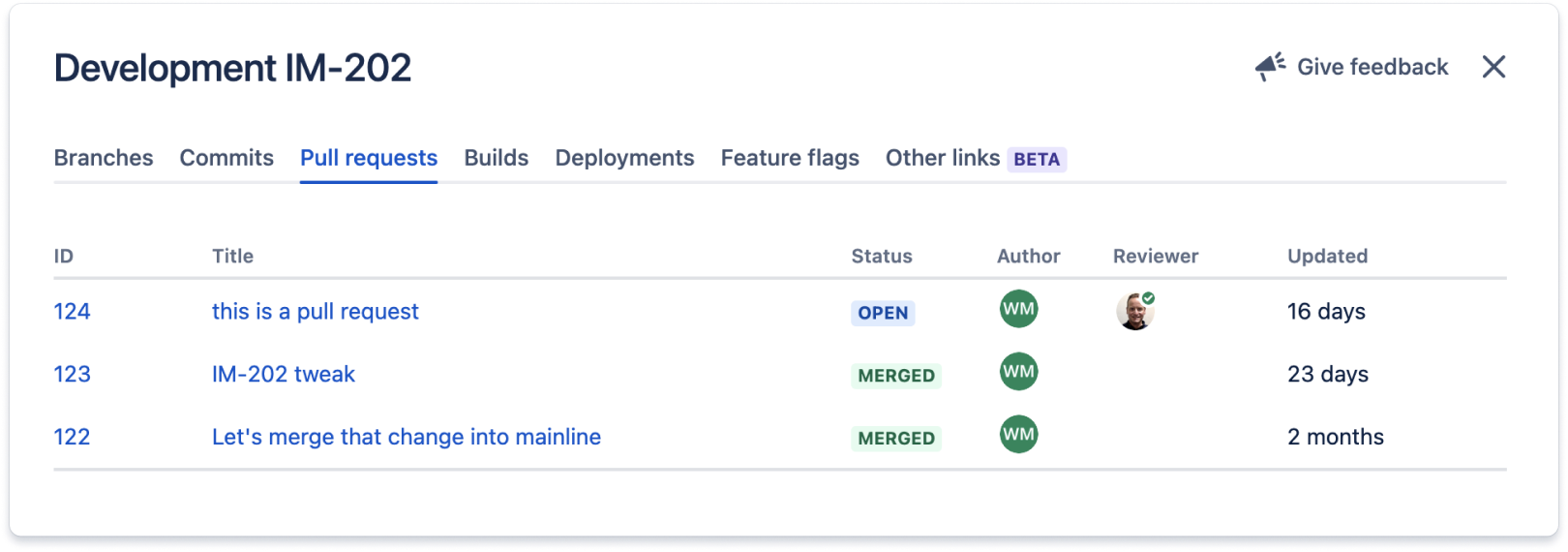
この Jira 作業項目に関連するコードは、[デプロイ] セクションに一覧表示されているすべての環境にデプロイされます。通常、Jira 作業項目 ID (この場合は IM-202) を Jira 作業項目に関連する作業のコミット メッセージやブランチ名に追加することによって、これらの統合が機能します。
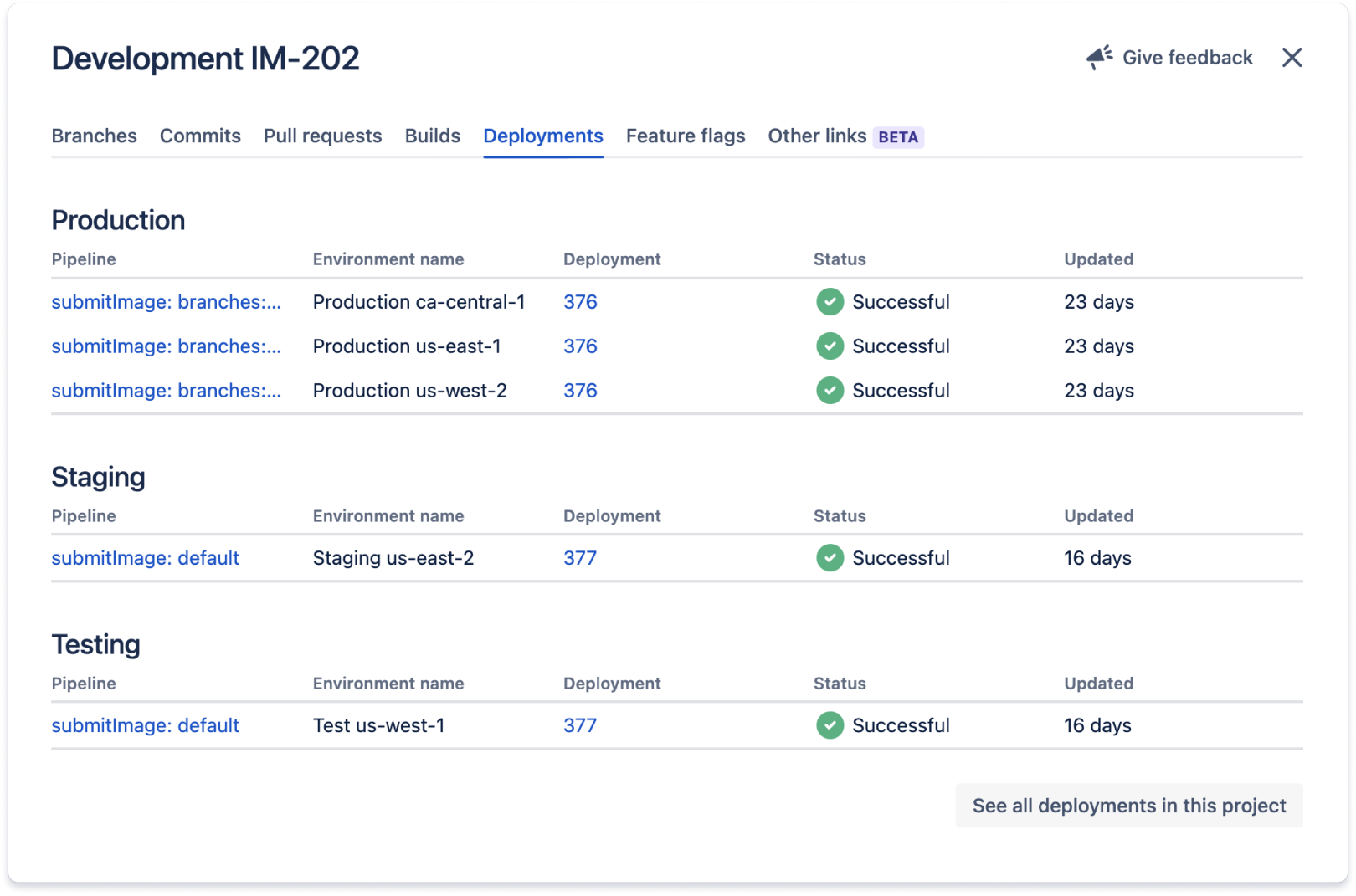
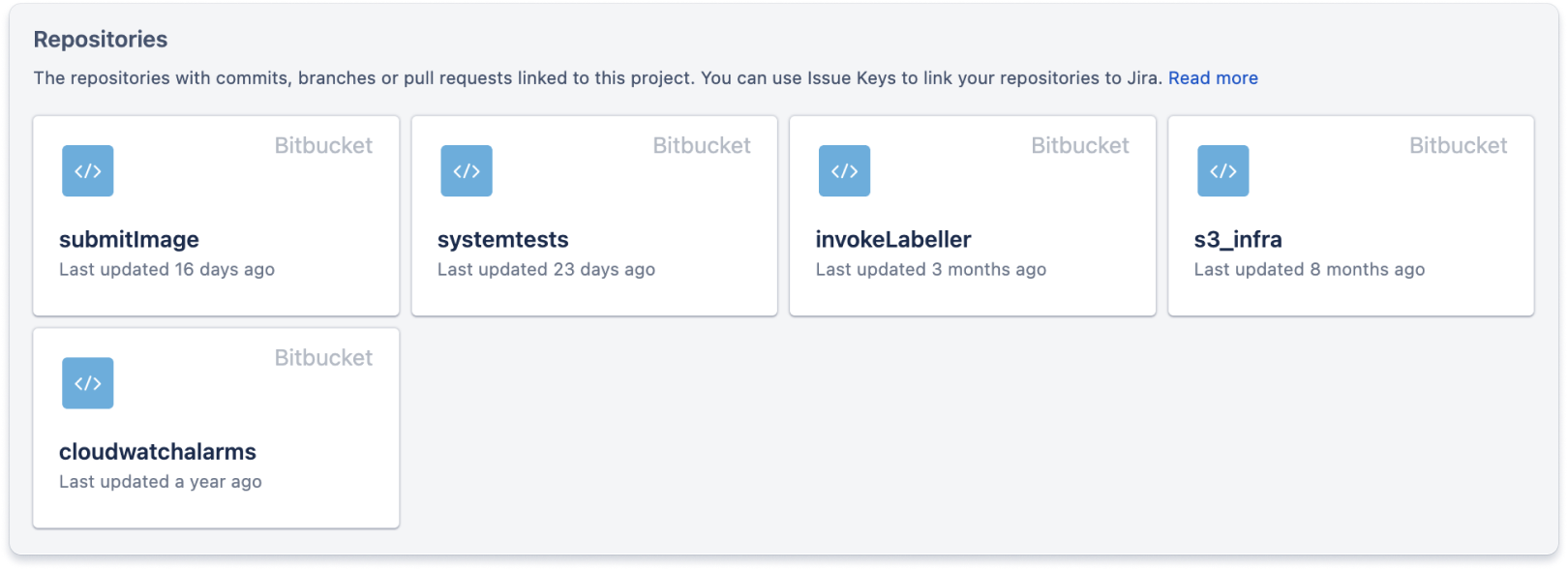
コード タブには、プロジェクトに関連するすべてのソース管理リポジトリへのリンクが提供されます。これにより、開発者は Jira 作業項目に割り当てられた際に、対処する必要があるコードを見つけることができます。
ステップ 5: テストを作成する
CI/CD パイプラインには、さまざまな環境にデプロイされたコードが正しく機能していることを検証するためのテストが必要です。まず、コードのユニット テストを作成します。野心的な目標としては、90 パーセントのコード カバレッジですが、始めたばかりでは非現実的です。コード カバレッジのベースラインは低く設定し、時間の経過とともにユニット テストの対象範囲を段階的に増やします。作業項目をバックログに追加して、これに対処できます。
本番コードで発見されたバグの修正時にテスト駆動開発を使用します。バグを発見したら、バグが存在する環境で失敗するユニット テスト、統合テスト、システム テストを作成します。その後、バグを修正して、テストが合格するようになったことを確認します。時間が経つと、このプロセスによってコード カバレッジは組織的に拡大します。バグがテスト環境またはステージング環境で発見された場合、これらのテストによって、本番環境に進んだ際にコードが適切に機能していることを確信できます。
最初から始める場合、このステップは大きな労力を要しますが重要です。テストによって、チームはこれらのコード変更をエンドユーザーに提供する前に、コード変更によるシステムの動作への影響を確認できます。
ユニット テスト
ユニット テストでソース コードが正しいことを検証し、CI/CD パイプラインの最初のステップの 1 つとして実行する必要があります。開発者は、未完成のパス、問題がある入力、既知の珍しいケースに対してテストを作成する必要があります。テストの作成時には、開発者は入力や予想される出力をモックできます。
統合テスト
統合テストによって、2 つのコンポーネントが相互に正しく通信していることを検証します。入力や予想される出力をモックします。これらのテストは、環境にデプロイする前の CI/CD パイプラインの最初のステップの 1 つです。通常、これらのテストを機能させるには、ユニット テストよりも広範囲にわたるモックが必要になります。
システム テスト
システム テストでは、システムのエンドツーエンドのパフォーマンスを検証し、システムが各環境で想定どおりに動作していることを確認します。コンポーネントが受け取ってシステムを実行する可能性のある入力をモックします。次に、システムが必要な値を返し、システムの他の部分が適切に更新されることを検証します。これらのテストは、各環境へのデプロイ後に実行する必要があります。
ステップ 6: CI/CD プロセスを構築してコンポーネントをデプロイする
CI/CD パイプラインを構築する際には、複数の環境へのデプロイを検討します。チームが単一の環境のみにデプロイする CI/CD パイプラインを構築すると、変更できない状況になります。インフラストラクチャとコードのために CI/CD パイプラインを構築することが重要です。まず CI/CD パイプラインを構築し、各環境に必要なインフラストラクチャをデプロイします。次に、コードをデプロイするために、別の CI/CD パイプラインを構築します。
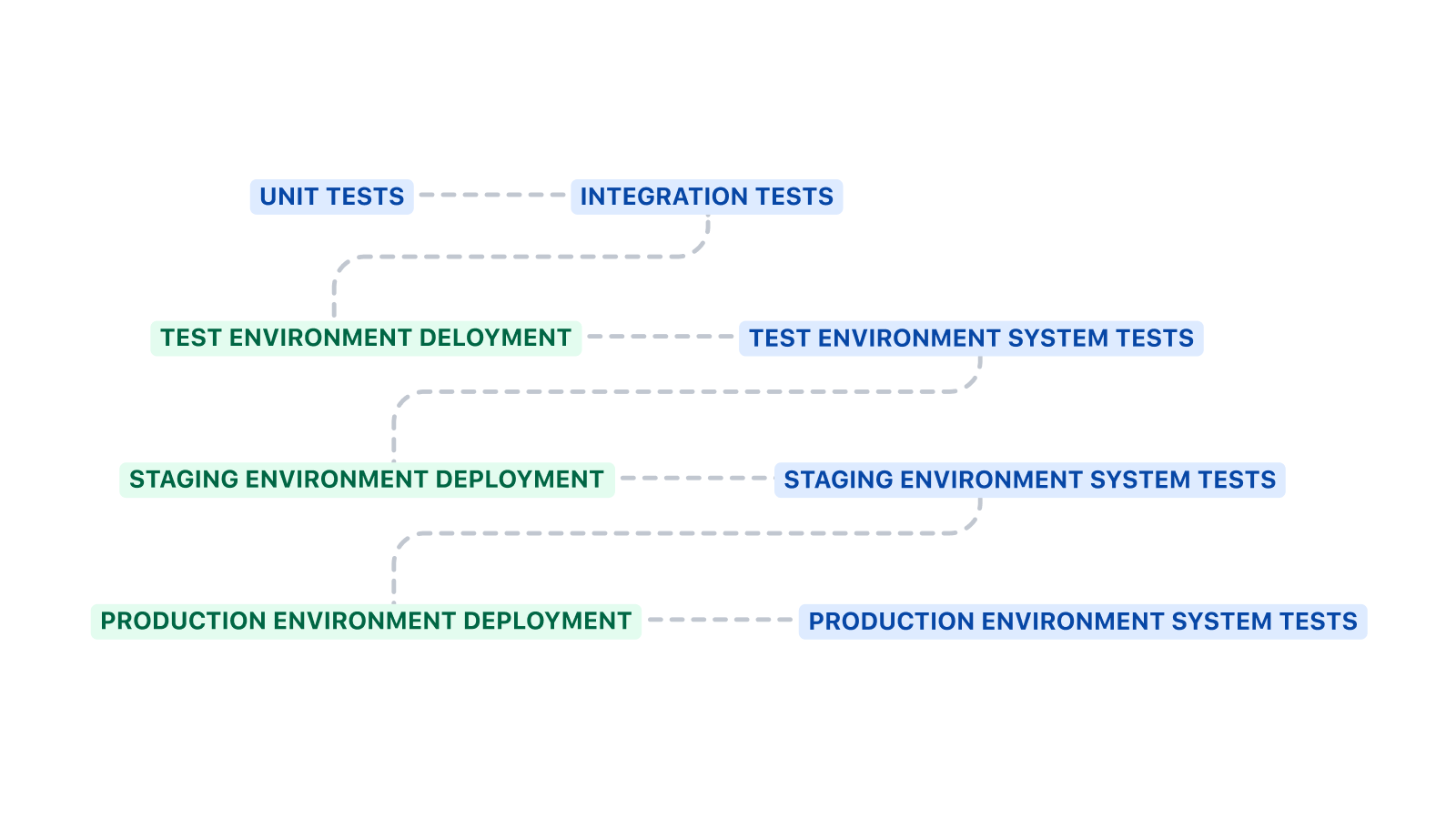
パイプラインの構造
このパイプラインは、テスト環境にデプロイする前にユニット テストと統合テストを実行して始めます。システム テストは、環境へのデプロイ後に実行します。
上記の大まかなテンプレートは、さまざまな方法で拡張できます。コードのリンティング、静的解析、セキュリティ スキャンは、ユニット テストや統合テストの前に追加すべき適切なステップです。コードのリンティングではコーディング標準を適用し、静的解析では不適切なパターンをチェックし、セキュリティ スキャンでは既知の脆弱性の存在を検出できます。
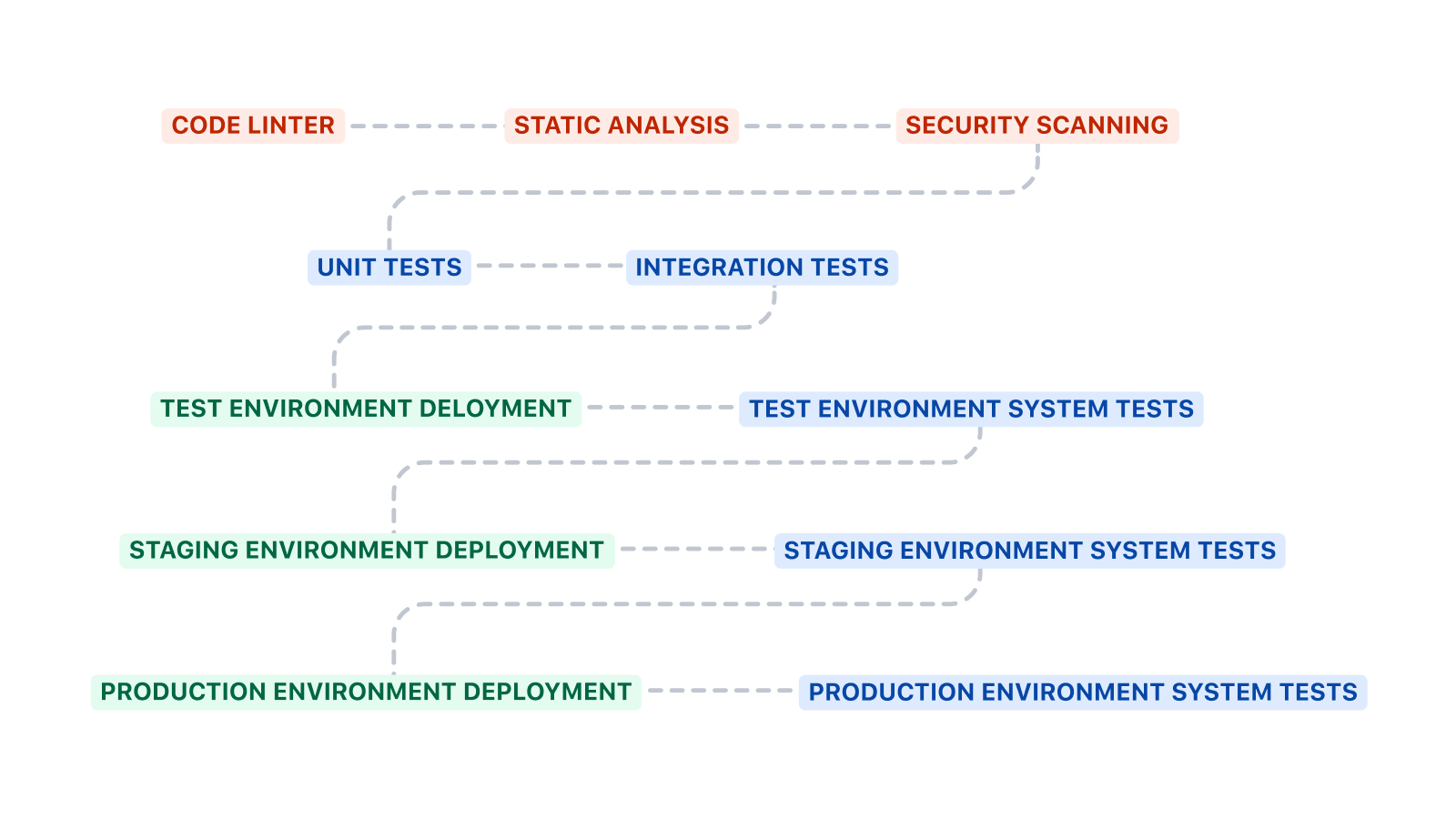
インフラストラクチャをデプロイするための CI/CD パイプラインと、コードをデプロイするための CI/CD パイプラインは異なることがあります。インフラストラクチャの CI/CD パイプラインでは、多くの場合、ユニット テストや統合テストは行いません。デプロイ後に常にシステム テストを実行し、システムが動作し続けていることを確認します。
インフラストラクチャ
環境によってインフラストラクチャは異なるため、ソフトウェアがその環境で正常に動作することは困難になります。ソフトウェアが適切に動作するには、ファイアウォール ルール、ユーザー権限、データベース アクセス、他のインフラストラクチャ レベルのコンポーネントが既知の構成である必要があります。手動でのインフラストラクチャのデプロイは、正確に繰り返すのが難しい場合があります。このプロセスには多くのステップがあるため、正確な順序で、正しいパラメーターで忘れずに各ステップを実行するというのは、エラーにつながる可能性があります。インフラストラクチャはできる限りコードで定義し、このような問題を軽減する必要があります。
インフラストラクチャは、AWS CloudFormation、Terraform、Ansible、Puppet、Chef などのさまざまなツールによって、コードで定義できます。
複数のパイプラインを作成して、インフラストラクチャをデプロイします。コードの記述など、インフラストラクチャのデプロイ モジュールを保持すると役立ちます。可能であれば、必要なインフラストラクチャを別個のサブセットに分解します。A、B、C、D を、相互に依存するインフラストラクチャ コンポーネントから抽出したとします。たとえば、A は EC2 ボックスで、B は S3 バケットだとします。インフラストラクチャ コンポーネント A (A のみ) がコンポーネント B に依存する依存関係は、同じ CI/CD パイプラインにまとめられる可能性が高くなります。A、B、C は D に依存するが、A、B、C は独立しているという依存関係は、複数の CI/CD パイプラインに分割されます。この場合、4 つの独立したパイプラインになります。この例では、A、B、C のコンポーネントすべてが依存する D に対して 1 つのパイプラインを構築し、A、B、C のそれぞれに 1 つずつ構築する必要があります。
コーディング
コードをデプロイするために CI/CD パイプラインを構築します。以前の作業によってインフラストラクチャがすでに利用可能であるため、これらのパイプラインは通常、簡単に実装できます。ここでの重要な考慮事項は、テスト、再現性、不正なデプロイからの回復力です。
再現性とは、システムに害を及ぼすことなく、同じ変更を何度もデプロイできることです。デプロイは再入可能かつ、べき等である必要があります。デプロイでは、既存の状態に修飾子を適用するのではなく、システムの状態を既知の構成に設定する必要があります。修飾子の適用を繰り返すことはできません。最初のデプロイ後、修飾子が適切に機能するのに必要な開始状態は変更されているためです。
繰り返し不可能な更新の簡単な例は、構成ファイルにデータを追加して更新することです。構成ファイルに行を追加したり、そのような修正方法を使用したりしないでください。追加によって更新すると、構成ファイルが数十行も重複してしまう可能性があります。代わりに、構成ファイルを、ソース管理によって正しく書き込まれたファイルに置き換えます。
また、この原則はデータベースの更新にも適用する必要があります。データベースの更新では問題が生じる可能性があり、細部にわたり注意する必要があります。データベース更新プロセスを、繰り返し可能で耐障害性のあるものにすることが不可欠です。変更を適用する直前にバックアップを取り、復旧できるようにします。
もう 1 つの考慮事項は、不正なデプロイから回復する方法です。デプロイが失敗してシステムの状態が不明でも、デプロイが成功しても、アラームがトリガーされて、問題のチケットの送信が開始されます。これに対処するには、一般的に 2 つの方法があります。1 つ目は、ロールバックを実行することです。2 つ目は、機能フラグを使用して必要なフラグをオフに切り替えて、既知の正常な状態に戻すことです。機能フラグの詳細については、この記事のステップ 8 を参照してください。
不正なデプロイが検出されたら、ロールバックによって以前の既知の正常な状態を環境にデプロイします。これは最初に計画する必要があります。データベースに着手する前に、バックアップを取ります。以前のバージョンのコードを迅速にデプロイできることを確認します。テスト環境またはステージング環境で定期的にロールバック プロセスをテストします。
ステップ 7: 監視、アラーム、インストルメンテーションを追加する
DevOps チームは、各環境で実行中のアプリケーションの動作を監視する必要があります。ログにエラーがないか、API の呼び出しがタイムアウトしていないか、データベースがクラッシュしていないか。システムの各コンポーネントに問題がないかを監視します。監視によって問題が検出されたら、問題のチケットを送信して、担当者が問題を解決できるようにします。解決策の一部として、問題を特定できる追加テストを作成します。
バグ修正
問題の監視と対応は、本番ソフトウェアの運用の一環です。DevOps 文化を持つチームは、ソフトウェアの運用を管理し、SRE (サイト信頼性エンジニア) の行動を取り入れています。問題の根本原因分析を行い、問題を検出するためのテストを作成して問題を修正し、テストに合格するようになったことを検証します。多くの場合、このプロセスには事前に労力を要しますが、長期的には利益をもたらします。このプロセスによって技術的負債が減少し、運用の俊敏性が維持されるためです。
パフォーマンスの最適化
基本的な正常性の監視を実施したら、次のステップとして頻繁にパフォーマンスの調整が行われます。各システムの動作を確認し、動作が遅いコンポーネントを最適化します。Knuth 氏が「早すぎる最適化は諸悪の根源」と述べたように、システム内のあらゆるもののパフォーマンスを最適化しないでください。最も動作が遅い、コストのかかるコンポーネントのみを最適化します。監視によって、動作が遅いコストのかかるコンポーネントを特定できます。
ステップ 8: 機能フラグを使用してカナリア テストを実施する
カナリア テストを有効にするには、テスト ユーザーを含む許可リストによって、それぞれの新機能を機能フラグにまとめます。新機能のコードは、環境にデプロイされると、許可リストのユーザーに対してのみ実行されます。新機能を次の環境に進める前に、それぞれの環境に行き渡るようにします。新機能がある範囲に行き渡ったら、指標、アラーム、他のインストルメンテーションに注意して、問題の兆候を確認します。具体的には、新しい問題のチケットが増加しているかを確認します。
新機能を次の環境に進める前に、1 つの環境で生じた問題に対処します。本番環境で発見された問題は、テスト環境やステージング環境の問題と同様に対処する必要があります。問題の根本原因を特定したら、問題を特定するテストを作成して修正を実施し、テストに合格することを検証し、CI/CD パイプラインによって修正を展開します。新しいテストに合格し、問題のチケット数が減少すると同時に、問題が検出された環境にその変更が行き渡るようになります。
結論
最初のコンポーネントを DevOps に移行するプロジェクトのふりかえりを行います。問題点や困難だった部分を特定します。これらの問題点に対処するための計画を補強したら、2 つ目のコンポーネントに移ります。
DevOps アプローチを使用してコンポーネントを本番稼働させることは、開始時点では相当な作業量に思えるかもしれませんが、これは後で実を結びます。基盤が確立されると、2 つ目のコンポーネントの実装は容易になります。最初のコンポーネントでの同じプロセスを使用して、2 つ目のコンポーネントに若干の変更を加えることができます。ツールの準備は整っており、テクノロジーは把握できており、チームは DevOps スタイルで作業するようトレーニングされているためです。
DevOps のジャーニーを始めるには、Atlassian Open DevOps をお試しいただくことをお勧めします。これは、統合されたオープン ツールチェーンで、ソフトウェアの開発と運用に必要なものがすべて揃っていて、ニーズの拡大に応じて追加のツールを統合できます。
この記事を共有する
次のトピック
おすすめコンテンツ
次のリソースをブックマークして、DevOps チームのタイプに関する詳細や、アトラシアンの DevOps についての継続的な更新をご覧ください。

DevOps コミュニティ

DevOps ラーニング パス