Comment fonctionne la gestion des incidents dans Jira Service Management ?
Vue d'ensemble
La gestion des incidents désigne la pratique qui consiste à répondre à un événement imprévu ou à une interruption et à rétablir le service.
- Incident : toute interruption non planifiée d'un service ou réduction de la qualité d'un service.
- Incident majeur : incident ayant un impact métier significatif et qui requiert une résolution coordonnée immédiate.
Un problème est la cause profonde encore inconnue derrière un ou plusieurs incidents.
La plateforme de gestion des incidents d'Atlassian vous permet d'intégrer tout le contexte et toutes les données dont vous avez besoin pour résoudre un incident rapidement et efficacement.
- Au sein de Jira Service Management, les agents peuvent facilement gérer les tickets et les incidents signalés par les utilisateurs.
- Les agents peuvent rapidement faire remonter les incidents majeurs sous forme d'alerte pour l'équipe d'astreinte. Jira Service Management permet aux équipes informatiques et DevOps de garder le contrôle d'un incident en centralisant les alertes, en informant les bonnes personnes, et en leur donnant les moyens de collaborer et d'agir rapidement.
- Les fonctionnalités natives de gestion des ressources et des configurations de Jira Service Management (incluses dans les offres Premium et Enterprise) aident les agents à comprendre les dépendances au sein de leur infrastructure informatique afin de localiser les causes potentielles de l'incident.
- Enfin, les espaces de travail partagés permettent de centraliser les pratiques, les processus et les procédures relatifs aux incidents à partir de runbooks, de bases de connaissances et de revues post-incident.
Cette solution transparente de gestion des incidents de bout en bout aide les équipes à faire remonter les problèmes, à solliciter les bons intervenants, à « swarmer » et finalement à réduire les temps d'arrêt.
Processus de gestion des incidents
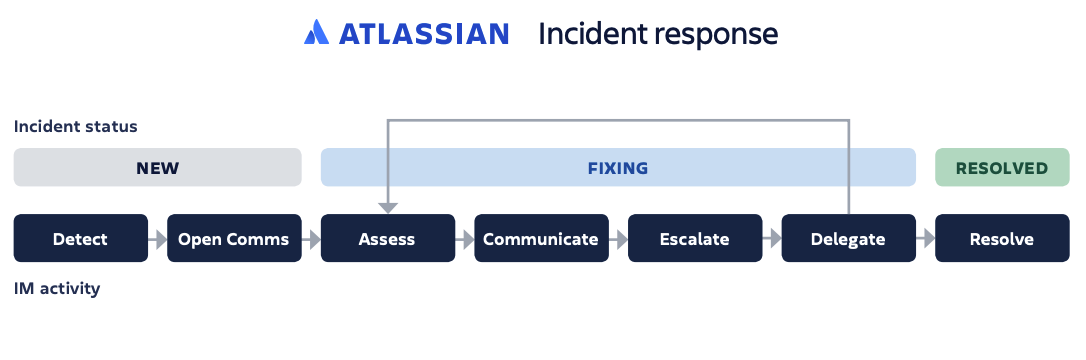
La clé de la gestion des incidents ? Adopter un processus de qualité et s'y tenir. Le terme de réponse aux incidents a une acception large. Décomposons-le et analysons les étapes que vous êtes le plus susceptible de suivre lorsque vous aurez identifié, catégorisé et hiérarchisé un incident.
- Diagnostic initial : les équipes de type DevOps sont généralement propriétaires d'un incident du diagnostic à la résolution, tandis que les centres de services à plusieurs niveaux disposent d'une équipe de première ligne avec les mêmes fonctions, mais qui peut, si nécessaire, faire remonter les tickets à des équipes de support de 2e ou 3e niveau.
- Remontée : si nécessaire, l'équipe suivante prend les données consignées et poursuit le processus de diagnostic, et, si cette équipe ne peut pas diagnostiquer l'incident, elle passe la main à l'équipe suivante.
- Communication : l'équipe partage régulièrement des mises à jour avec les parties prenantes internes et externes impactées.
- Enquête et diagnostic : le processus se poursuit jusqu'à ce que la nature de l'incident soit identifiée. Les équipes font parfois appel à des ressources extérieures ou à des membres d'autres services internes pour aider à la résolution.
- Résolution et récupération : lors de cette étape, l'équipe établit un diagnostic et suit les étapes nécessaires pour résoudre l'incident. La récupération implique simplement l'effort nécessaire pour une restauration totale du service, car certaines corrections (comme les corrections de bug, par exemple) peuvent nécessiter des tests et un déploiement, et ce, même après que la résolution appropriée a été identifiée.
- Clôture : si l'incident a fait l'objet d'une remontée, il est ensuite renvoyé au support de première ligne pour être clôturé. Afin de maintenir la qualité et d'assurer un processus en douceur, seuls les employés du centre de services sont autorisés à clôturer les incidents. En outre, le propriétaire de l'incident devrait vérifier auprès de la personne qui l'a signalé que la résolution est satisfaisante et que l'incident peut réellement être clôturé.

Pour plus d'informations, consultez notre page Gestion des incidents.
Comment se lancer avec la gestion des incidents dans Jira Service Management ?
Comment se lancer avec la gestion des incidents
Jira Service Management fournit un workflow de gestion des incidents conforme à ITIL (Information Technology Infrastructure Library) appelé : workflow de gestion des incidents pour Jira Service Management. Nous vous recommandons de commencer par ce workflow et de l'adapter aux besoins spécifiques de votre entreprise au fil du temps. En savoir plus sur la modification des workflows.
Par défaut, les champs suivants sont affichés dans la vue d'un incident de vos agents. Si vous avez besoin de champs supplémentaires, vous pouvez également ajouter des champs personnalisés.
Comment créer des accords de niveau de service (SLA) pour les enregistrements d'incidents
Jira Service Management fournit de puissants SLA intégrés, afin que les équipes puissent suivre le niveau de service attendu par leurs clients. Les administrateurs de projet peuvent créer des objectifs de SLA qui spécifient les types de demandes que vous souhaitez suivre et le temps nécessaire pour les résoudre. Ensuite, vous pouvez définir les conditions et les calendriers qui se répercutent sur le début, l'interruption ou l'arrêt des mesures de SLA.
Pour créer un SLA :
- Dans votre projet de services, accédez à Project settings > SLAs (Paramètres du projet > SLA). Tous les SLA existants sont affichés ici.
- Sélectionnez Add SLA (Ajouter un SLA).
- Dans le champ en regard de l'icône d'horloge, saisissez un nouveau nom pour le SLA ou choisissez un nom existant.
- (Vous ne pourrez pas modifier le nom de votre SLA une fois qu'il aura été créé, choisissez donc un nom qui indique clairement ce qui est mesuré.)
- Fixez des objectifs et des conditions pour le SLA. En savoir plus sur la définition d'objectifs de SLA et la configuration de métriques de temps des SLA.
- Sélectionnez Save (Enregistrer).
Comment marquer les incidents comme majeurs dans Jira Service Management
Lorsque des services critiques subissent une panne, Jira Service Management Cloud fournit les outils nécessaires pour aider les agents à résoudre rapidement les incidents. Marquer un incident comme majeur augmente sa visibilité parmi les autres incidents. En outre, ces incidents sont regroupés dans leur propre file d'attente « Incidents majeurs » optimisée par JQL.
Pour marquer un incident comme majeur :
- Accédez à l'incident que vous souhaitez marquer comme majeur.
- Dans la section Details (Informations) du ticket, cliquez sur le bouton Major incident (Incident majeur).
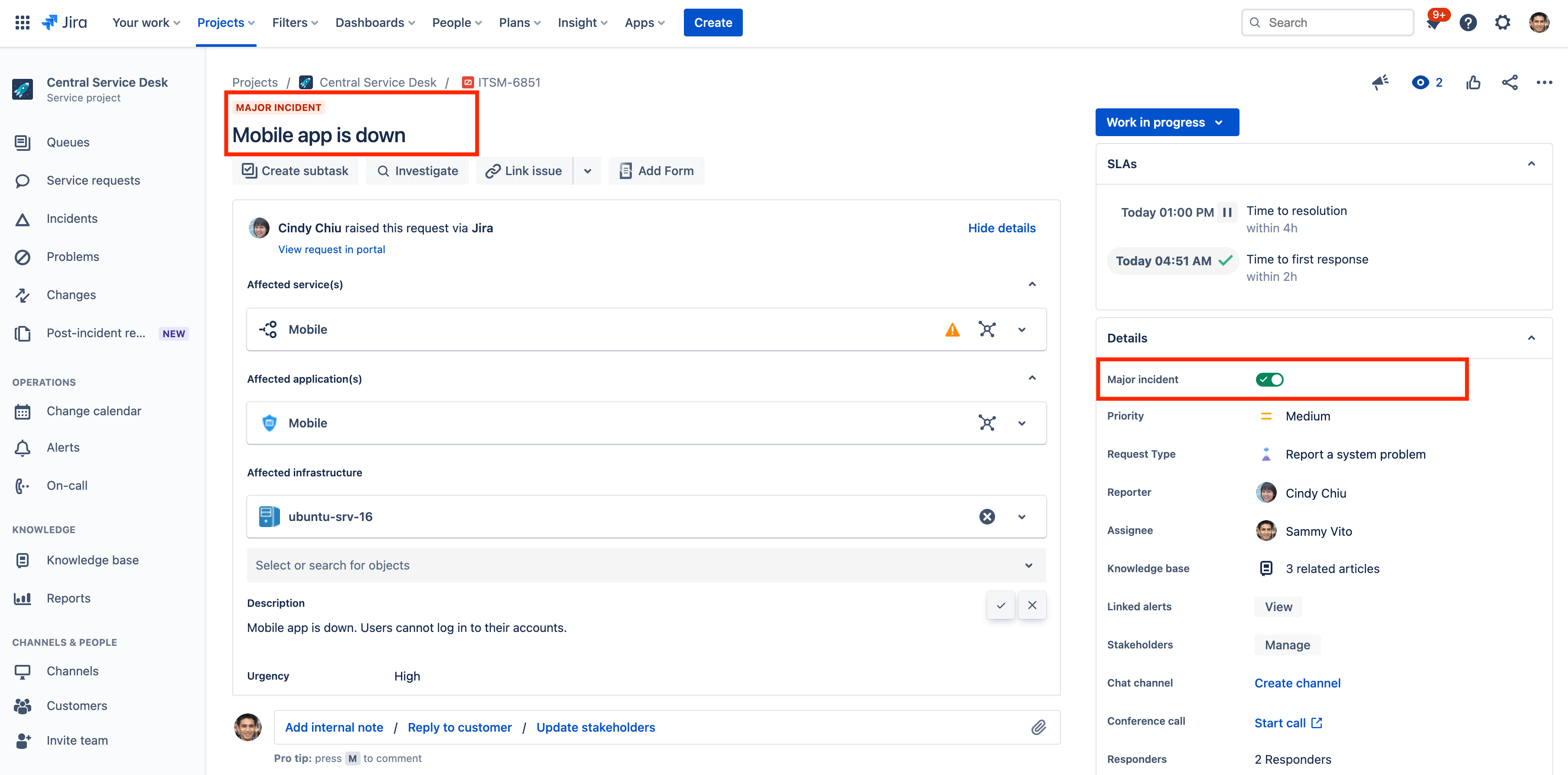
Remarque : si le champ Major incident (Incident majeur) n'apparaît pas pour vos incidents, assurez-vous d'avoir ajouté le champ à votre vue du ticket. Pour ajouter des champs à un type de ticket, vous devez être un administrateur Jira.
Comment créer des mises à jour et les envoyer à un canal Slack directement à partir d'un incident
Jira Service Management vous permet de connecter votre espace de travail et de créer un canal Slack dédié pour chaque incident. En connectant les espaces de travail Slack à votre projet de services, vous pouvez créer des canaux Slack pour vos incidents, ajouter des intervenants sur l'incident à vos canaux Slack, mettre à jour vos priorités d'incident, agir en réponse aux incidents et aider votre équipe à intervenir rapidement durant les incidents.
Pour créer un canal d'incident Slack :
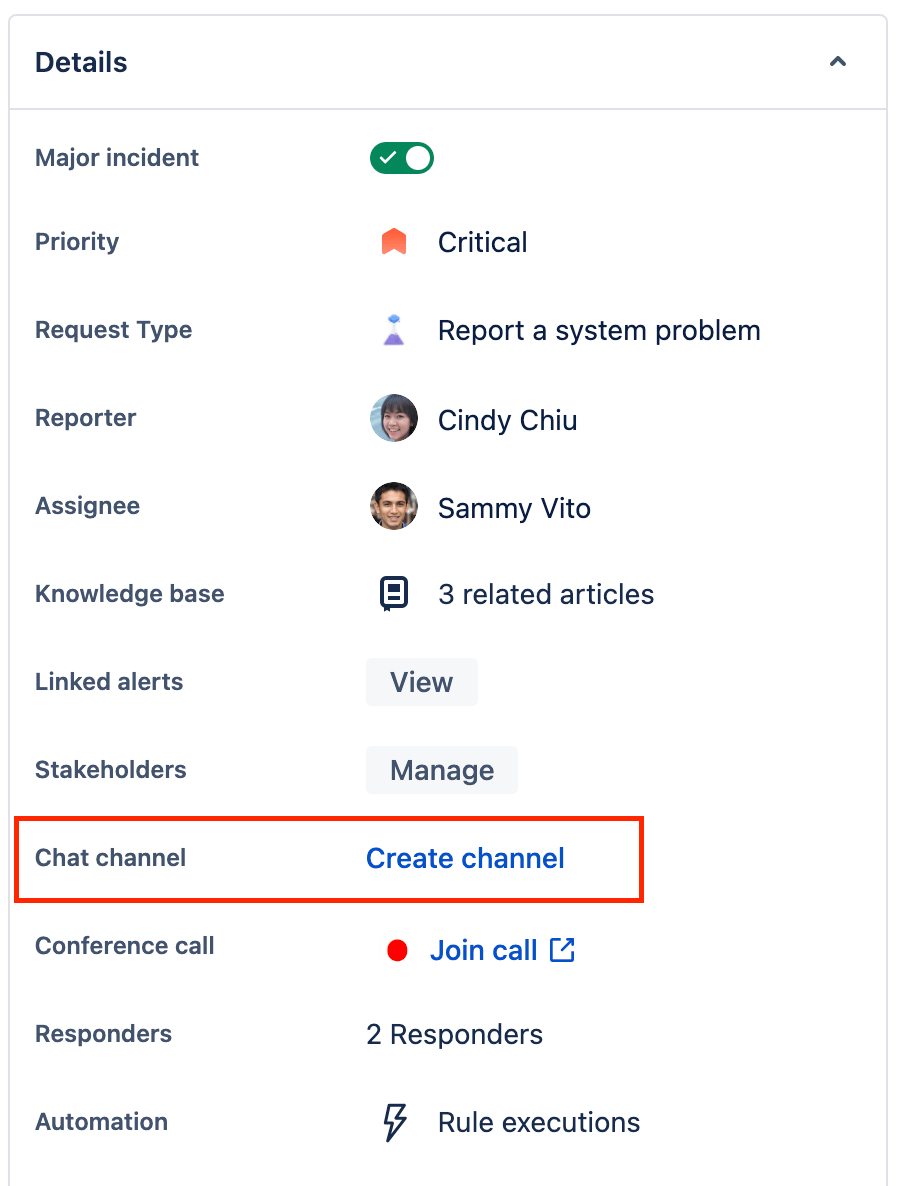
- Accédez à l'incident pour lequel vous souhaitez créer un canal Slack.
- Sélectionnez Create channel (Créer un canal) dans la section Details (Informations) du ticket.
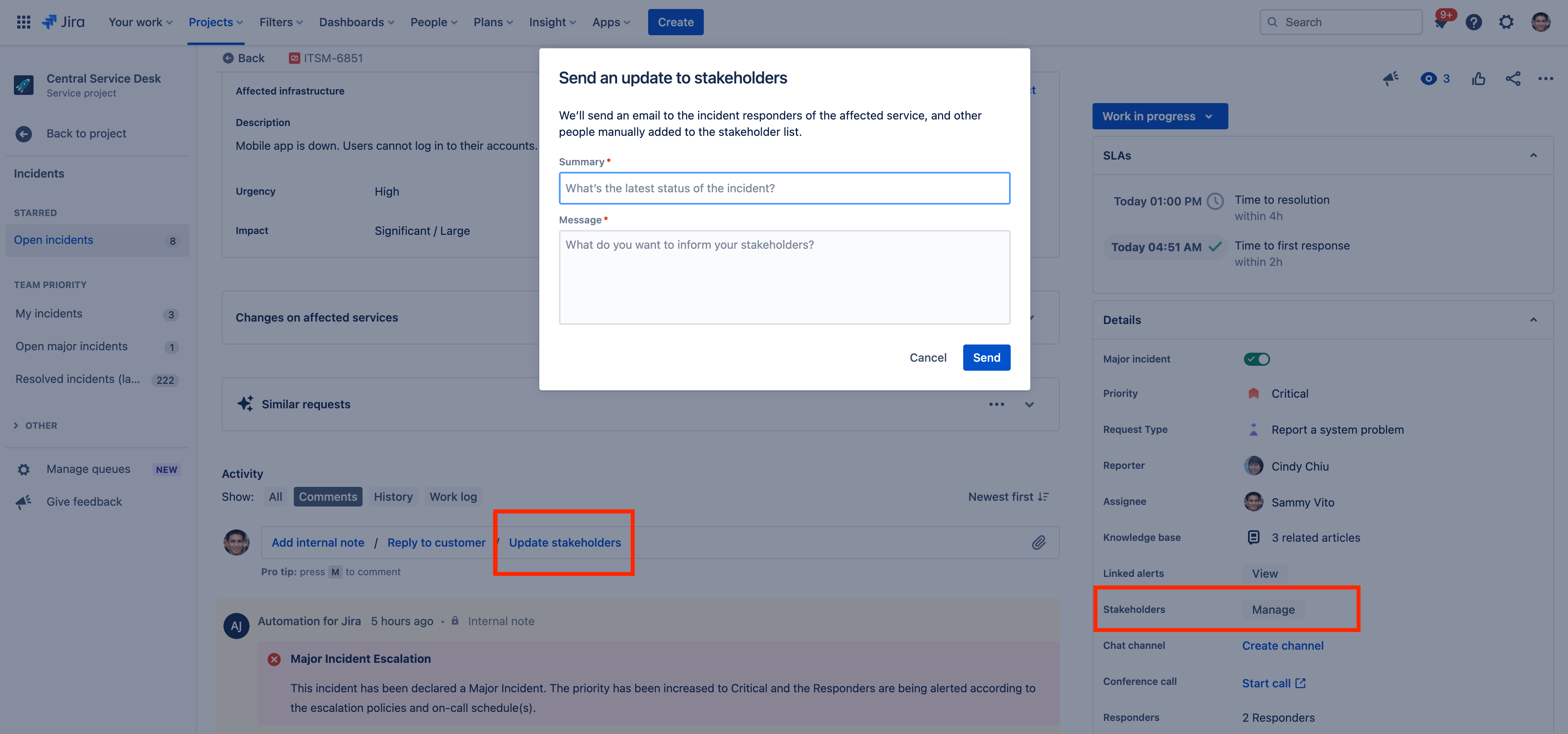
Comment envoyer des mises à jour d'incident aux parties prenantes internes
Les parties prenantes internes sont des personnes qui ne sont pas des intervenants, mais doivent tout de même être informées de l'avancement des incidents afin de prendre des précautions et des mesures. Jira Service Management vous permet d'ajouter des personnes en tant que parties prenantes et de les informer par e-mail.
Pour ajouter/supprimer des parties prenantes internes :
- Accédez à l'incident pour lequel vous souhaitez ajouter des parties prenantes internes.
- Sélectionnez Manage (Gérer) en regard du champ Stakeholders (Parties prenantes) sous Details (Informations).
- Recherchez les personnes que vous souhaitez ajouter comme parties prenantes.
Pour envoyer une mise à jour aux parties prenantes internes :
- Dans la section Activity (Activité) de la vue du ticket, sélectionnez Update stakeholders (Informer les parties prenantes).
- Saisissez un résumé et un message.
- Appuyez sur Send (Envoyer).
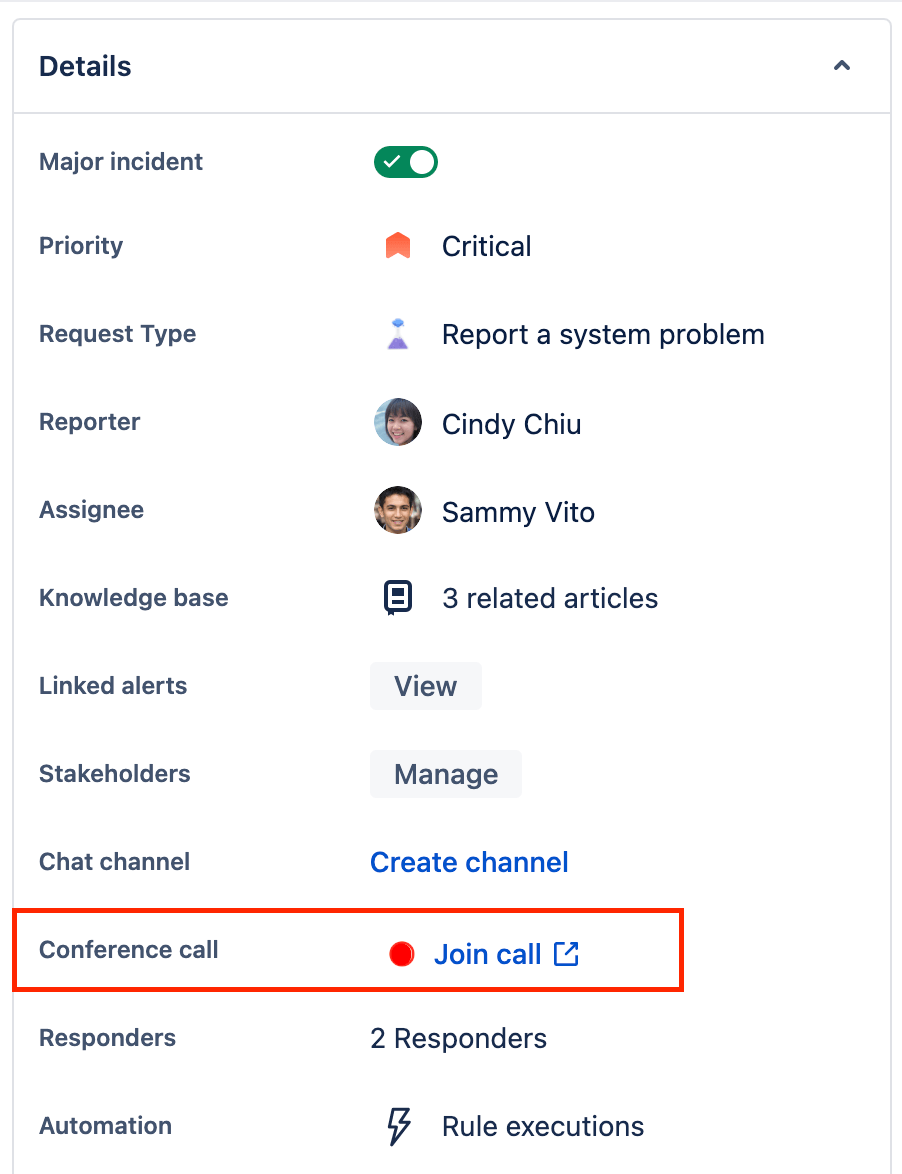
Comment « swarmer » sur les incidents avec votre équipe via des téléconférences
Jira Service Management propose des salles de conférence audio/vidéo pour coordonner les incidents et les gérer depuis un emplacement centralisé.
Pour lancer une téléconférence :
- Accédez à l'incident pour lequel vous souhaitez lancer une téléconférence.
- Sélectionnez Start call (Démarrer l'appel) ou Join call (Rejoindre l'appel) pour un appel existant en regard du champ Conference call (Téléconférence) sous Details (Informations).
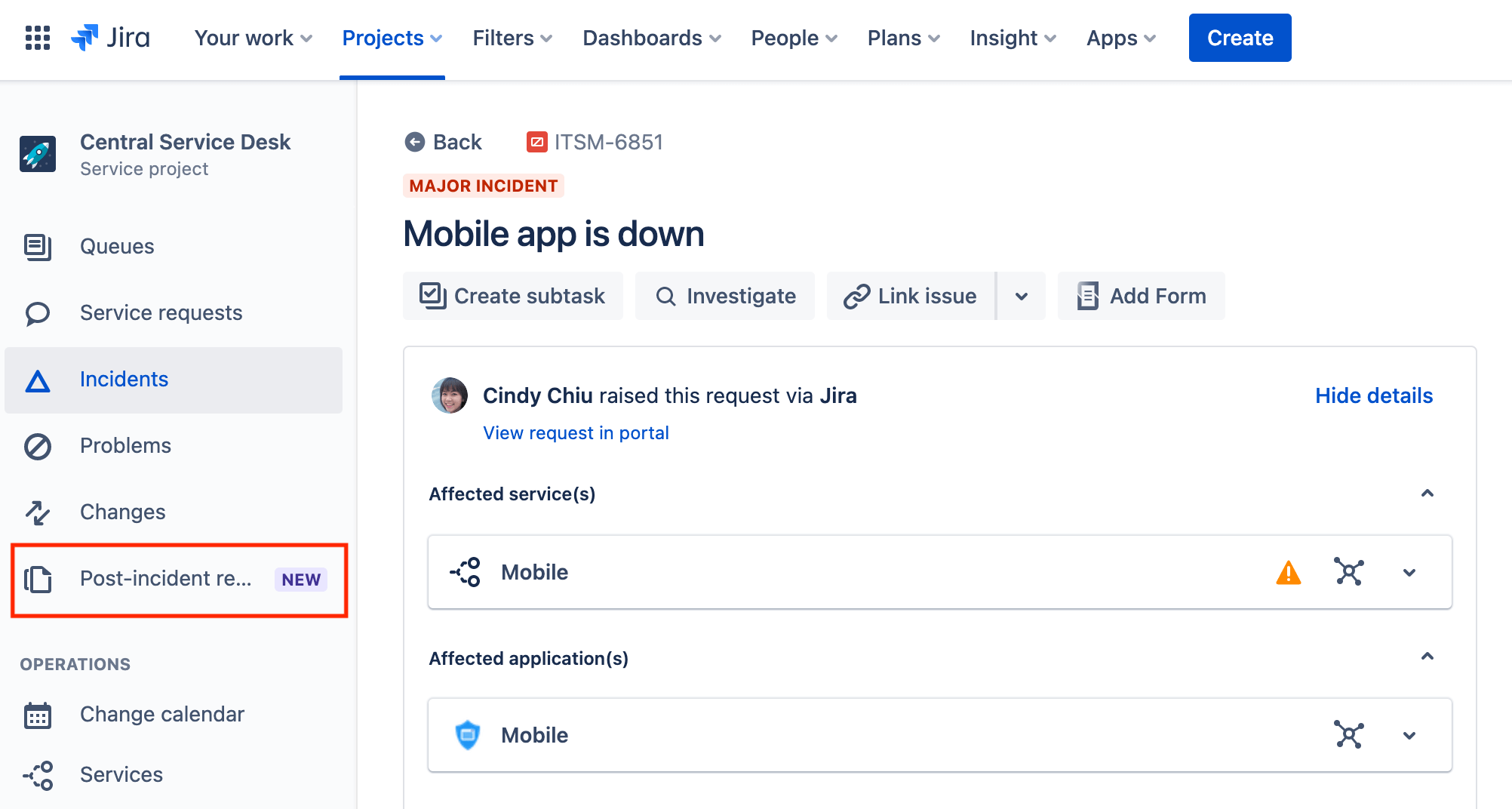
Découvrir comment créer des revues post-incident (PIR) et y accéder
Les revues post-incident vous permettent de détecter les vulnérabilités de votre système, de briser le cycle des incidents et de réduire le délai de résolution des incidents à l'avenir. Elles constituent une étape importante dans le cycle de vie d'un service disponible en continu. Les résultats de votre revue doivent être intégrés à votre processus de planification afin de garantir que les corrections critiques seront présentes dans les tâches à venir. Consigner l'incident et la manière dont l'équipe l'a résolu peut influencer la gestion future des incidents. Les équipes peuvent créer des solutions à long terme pour pallier les problèmes menant à un incident et lier la revue post-incident à l'incident dans Jira Service Management.
Pour activer la fonctionnalité de revue post-incident :
- Accédez à Project Settings (Paramètres du projet), puis Features (Fonctionnalités).
- Activez Post-incident reviews (Revues post-incident) sous ITSM categories (Catégories ITSM).
En activant cette catégorie, vous accéderez à de nouvelles fonctionnalités pour vos demandes. Vous devrez créer des types de demandes ou assigner vos types de demandes existants à la catégorie Post-incident reviews (Revues post-incident) pour vous lancer.
Pour accéder à vos revues post-incident :
- Sélectionnez Post-incident review (Revue post-incident) dans le menu latéral de votre projet.
- Sélectionnez la file d'attente appropriée pour les revues post-incident.
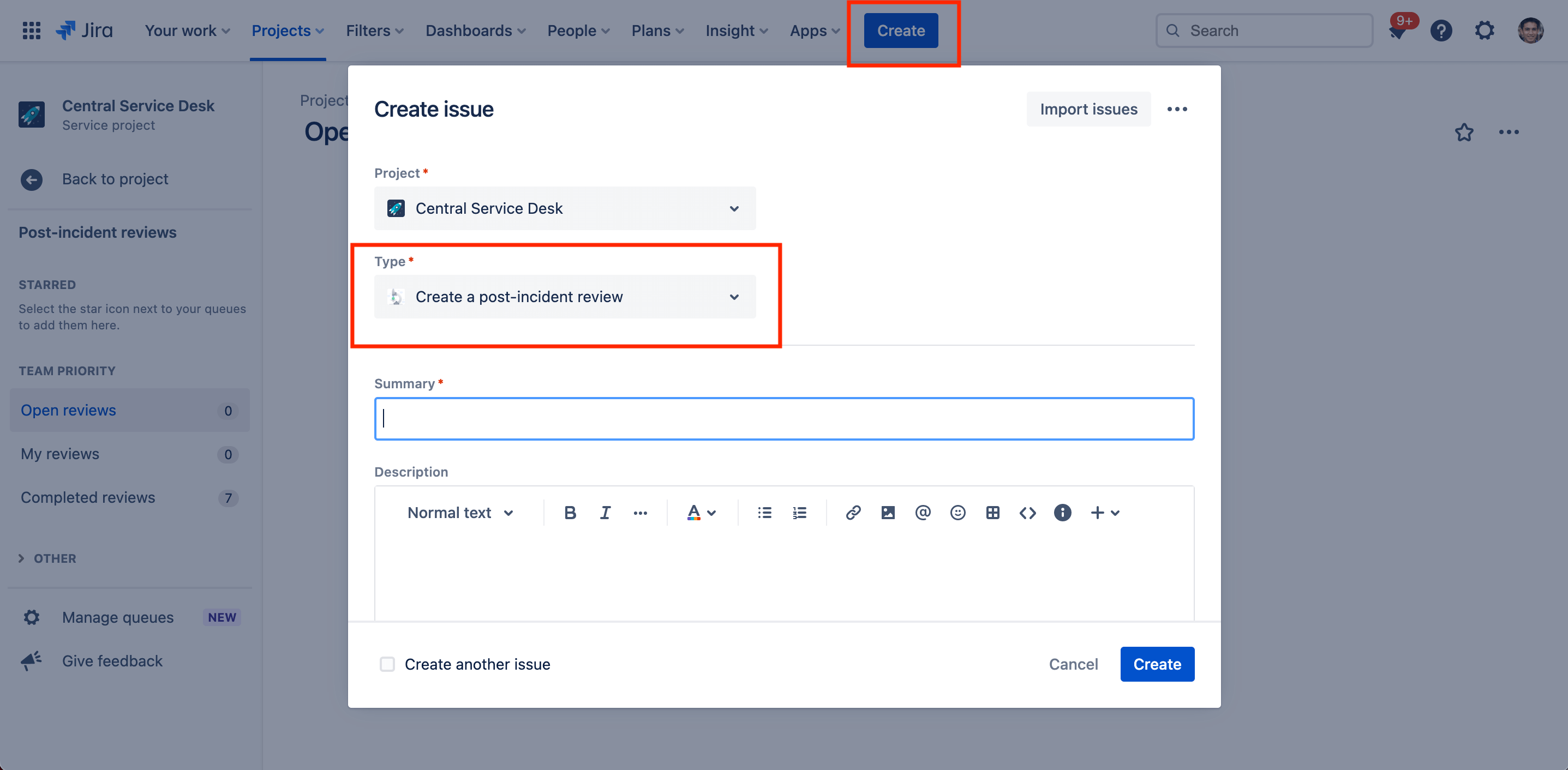
Pour créer une revue post-incident :
- Sélectionnez Create (Créer) dans la barre de menus supérieure.
- Sélectionnez le type de demande de revue post-incident que vous avez défini dans le menu déroulant.
- Indiquez les informations requises et liez l'incident approprié à la revue post-incident dans le champ linked issues (tickets liés).
- Sélectionnez Create (Créer) lorsque vous avez terminé.
Conseil de pro : vous pouvez également créer des revues post-incident à l'aide du moteur d'automatisation natif de Jira Service Management. Par exemple, vous pouvez définir une règle d'automatisation pour créer une revue post-incident dès qu'un incident de priorité majeure ou critique est résolu par votre équipe.
Comment lier plusieurs incidents à un rapport de problème
Jira Service Management vous permet de lier plusieurs tickets entre eux. Par exemple, vous pouvez lier plusieurs enregistrements d'incidents à un rapport de problème de plus grande envergure.
Pour lier plusieurs incidents à un rapport de problème :
- Consultez l'enregistrement de l'incident.
- Sélectionnez Link Issue (Lier un ticket).
- Dans le champ linked issues (tickets liés), sélectionnez is caused by (est causé par).
- Saisissez le ticket (ou sélectionnez-le dans le menu déroulant) correspondant au ticket vers lequel vous souhaitez créer un lien dans le champ Issue (Ticket).
- Sélectionnez Link (Lier).
Bonnes pratiques et conseils en matière de gestion des incidents
Facilitez la capture des incidents signalés par les utilisateurs et le système
Jira Service Management est la source de référence pour les incidents mineurs et majeurs. Le portail client rassemble les incidents signalés par les utilisateurs de manière complète et cohérente, avec toutes les informations dont l'équipe de support a besoin pour évaluer l'incident. Lorsque des employés ou des clients constatent un incident, ils peuvent le signaler dans Jira Service Management. Les incidents sont ensuite acheminés vers les files d'attente des agents appropriés.
Pour la détection rapide des incidents et des pannes, la surveillance efficace est le plus grand allié des équipes ITOps. Pour les incidents détectés par le système, Jira Service Management s'intègre facilement à plus de 200 apps et services web (comme Slack, Datadog, Sumo Logic et Nagios) afin de synchroniser les données d'alerte et de simplifier votre workflow d'incident.
Réduisez la fatigue d'alerte grâce à des plannings d'astreinte intelligents
Lorsque les équipes d'astreinte sont inondées d'alertes non pertinentes, une fatigue d'alerte peut s'installer et leur faire manquer des notifications importantes. Les capacités intégrées de gestion des incidents de Jira Service Management permettent à votre équipe de ne jamais manquer une alerte critique.
En mettant en place des plannings et en définissant des règles de remontée ou d'« escalade » (ITIL) au sein d'une interface unique, votre équipe sait toujours qui est d'astreinte et qui est responsable en cas d'incident. La solution regroupe les alertes, filtre les interférences et avertit les membres de l'équipe via différents canaux (SMS, appel téléphonique, notifications Push ou e-mail), tout en leur fournissant le contexte pertinent nécessaire pour démarrer immédiatement la résolution.
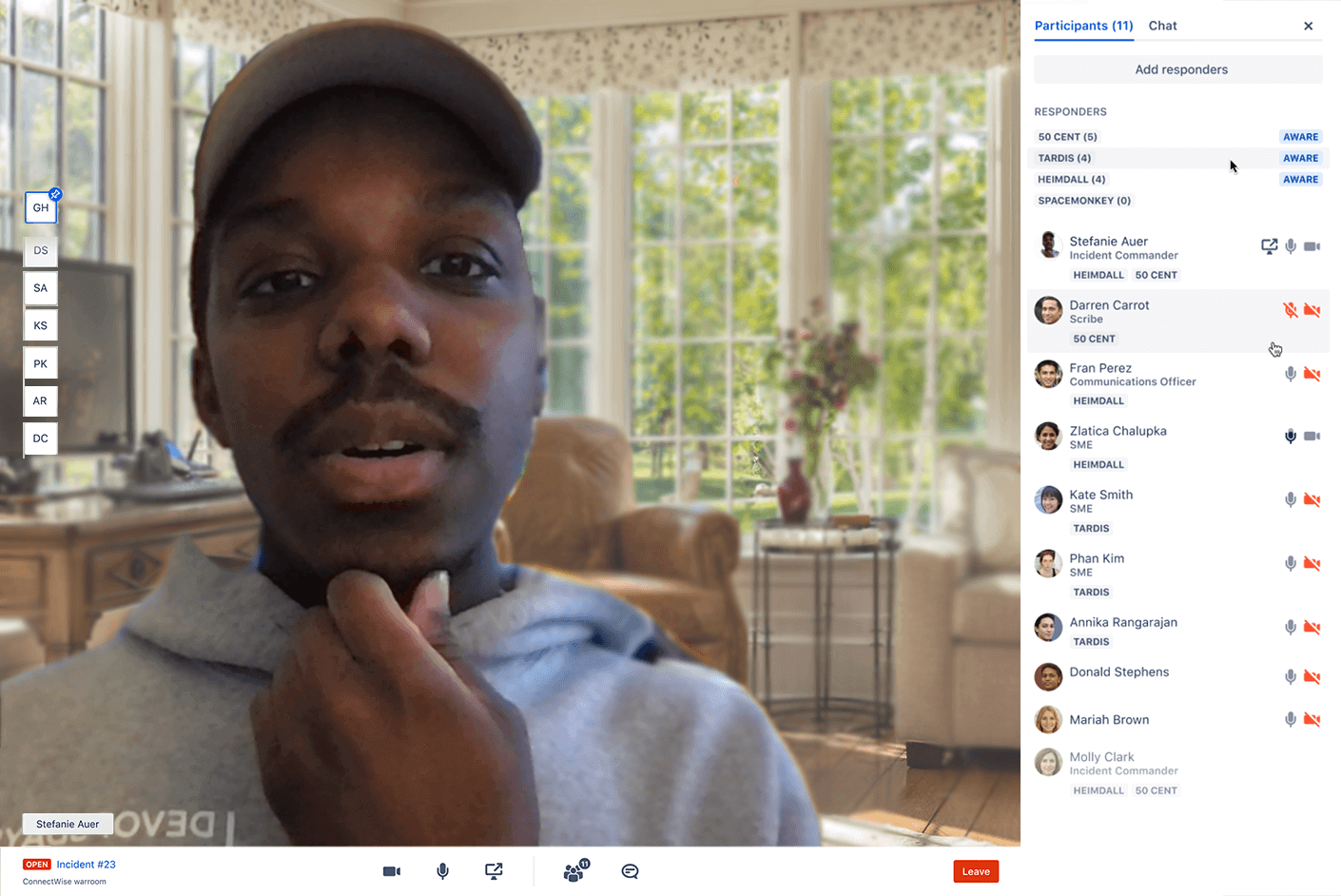
Utilisez ChatOps et les runbooks pour améliorer la coordination des équipes
Grâce à Jira Service Management, les équipes disposent d'un espace centralisé pour collaborer, partager des informations en temps réel et accélérer la résolution avec le centre de commande des incidents (ICC). Plutôt que de naviguer entre des mises à jour fragmentées dans des discussions instantanées privées ou de faire défiler de longs historiques de conversations, prédéfinissez une salle de visioconférence pour que les équipes puissent discuter de façon dynamique, assigner des rôles et même prendre des mesures décisives directement dans l'interface. Les runbooks étant joints aux alertes, les équipes peuvent rapidement lancer des tâches de remédiation ou « rattrapage » (ITIL) standard, soit automatiquement, soit à la demande.
Les runbooks sont également parfaits pour documenter les méthodes de dépannage courantes pour traiter les alertes et résoudre les pannes. Grâce aux runbooks, votre équipe a sous la main toutes les informations dont elle a besoin pour trier rapidement un incident. Dans de nombreux cas, les équipes peuvent réduire de 40 % les délais de résolution des incidents.
Élaborez un manuel de gestion proactive des incidents
Planifiez votre stratégie de réponse aux incidents à l'avance. Vous réduirez le stress, vous maintiendrez la concentration de votre équipe pendant l'incident et vous raccourcirez le délai de résolution. Veillez à inclure des pratiques de collaboration à la fois opérationnelles et basées sur l'équipe :
- Identifiez ce qui importe le plus à votre équipe lors d'une réponse aux incidents et élaborez un plan pour incarner ces valeurs en permanence. Les valeurs peuvent être la collaboration, la communication et les revues post-incident « sans reproches ».
- Définissez clairement les incidents majeurs.
- Documentez vos pratiques de gestion des incidents majeurs.
- Établissez vos communications sur la réponse aux incidents, comme les modèles de réponse et les communications pour les parties prenantes internes et externes.
- Déterminez les membres clés de votre équipe faite d'équipes pour la réponse aux incidents.
- Établissez vos pratiques PIR.
- Menez des PIR sans reproche pour tous les incidents majeurs.
- Publiez et partagez les enseignements tirés des PIR.
- Menez des exercices de simulation pour tous les incidents majeurs.
Concentrez-vous sur le temps moyen jusqu'à la remise en route (MTTR)
La mise en place d'un processus solide de gestion des incidents est essentielle pour réduire l'impact de l'incident et rétablir rapidement les services. La clé pour améliorer la réponse est de réduire le temps moyen jusqu'à la remise en route (MTTR) et de simplifier l'analyse des causes premières afin d'éviter les pannes futures. Le cabinet Forrester a découvert que 70 % du temps de réponse aux incidents était consacré à la phase d'investigation et de diagnostic.
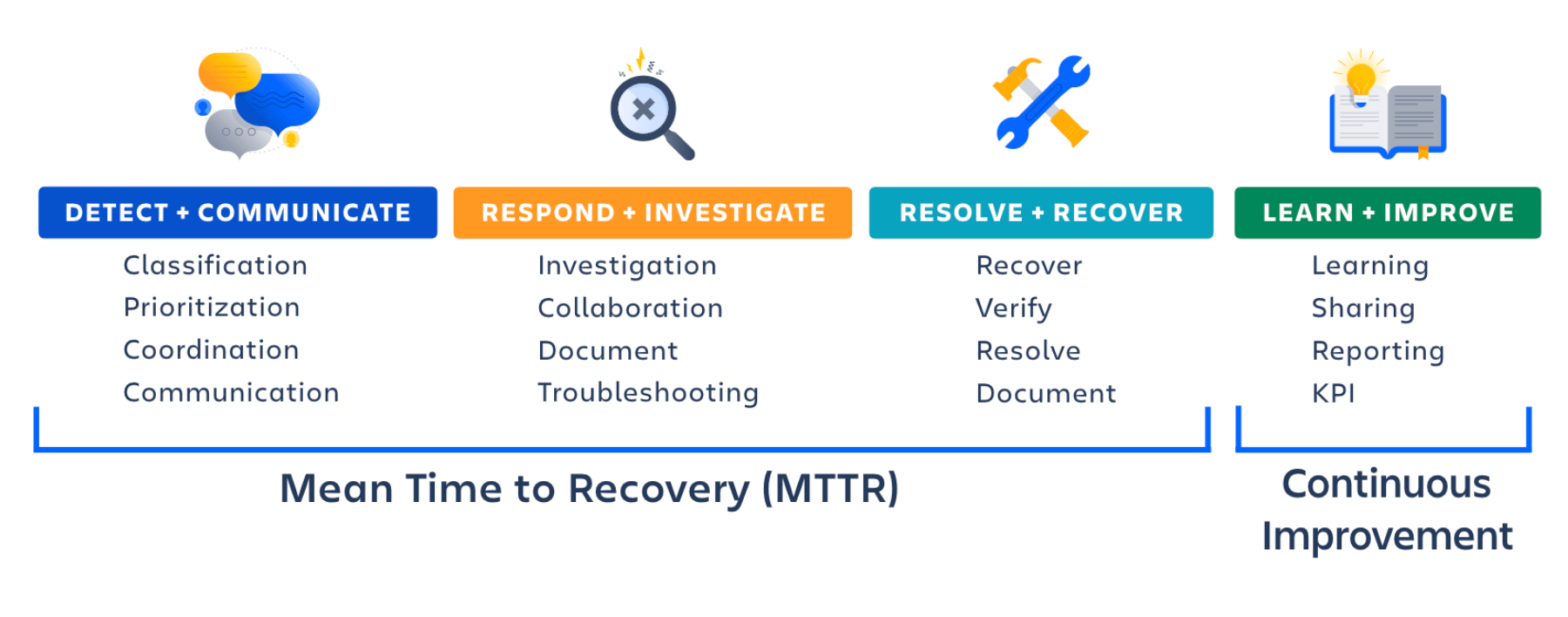
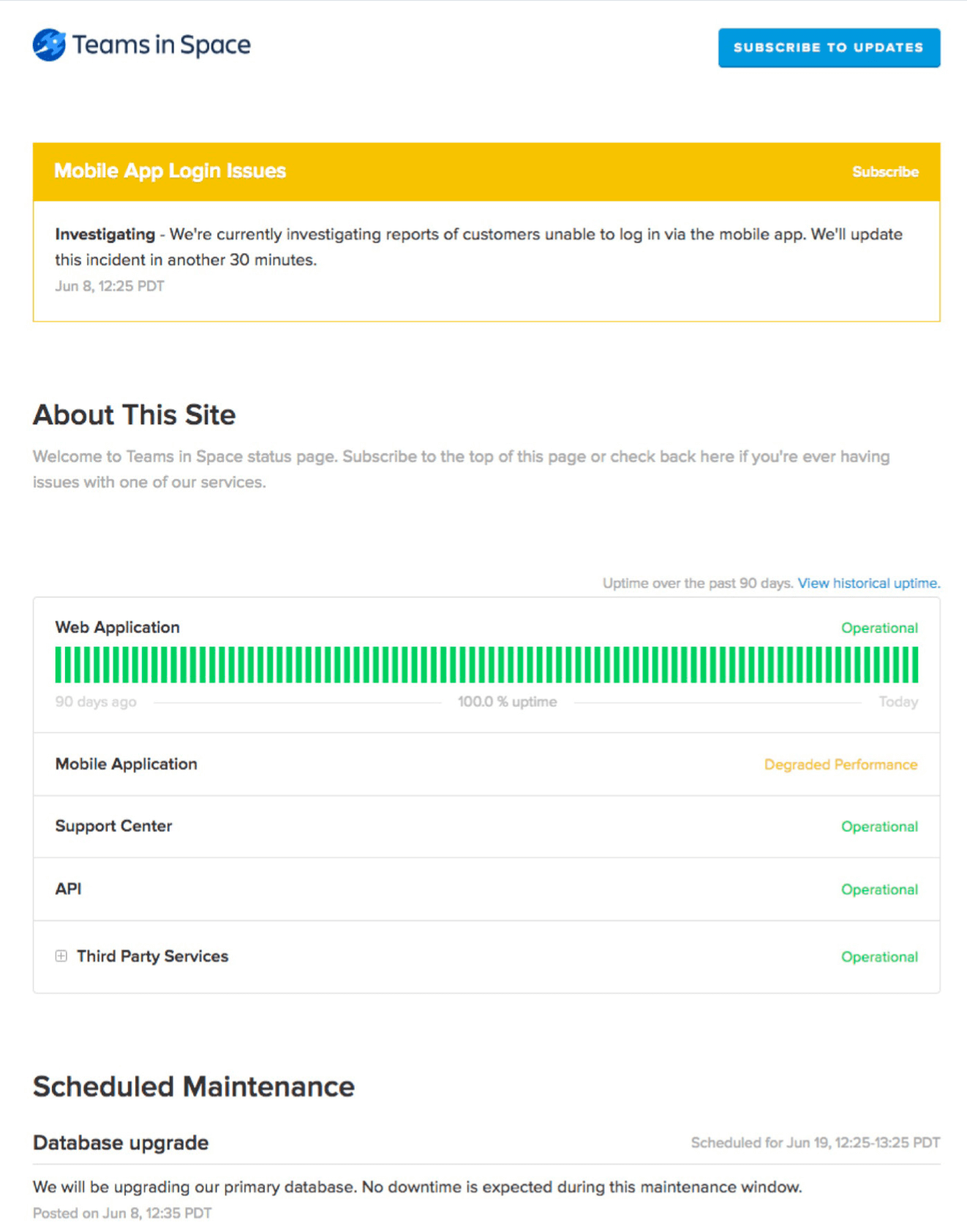
Établissez la confiance grâce à une communication externe centralisée
De nombreuses équipes utilisent un tableau de bord centralisé, comme Statuspage, pour communiquer sur l'état des services stratégiques. Statuspage fonctionne comme un canal unique destiné à une communication de masse claire et proactive pour les utilisateurs internes et externes, avec des notifications et des mises à jour automatisées.
Statuspage tient les équipes internes informées des temps d'arrêt planifiés et non planifiés. Les clients et les employés peuvent s'abonner aux mises à jour, ce qui favorise une communication cohérente et réduit les mises à jour manuelles.
Pour en savoir plus, consultez notre page sur les bonnes pratiques en matière de gestion des incidents.
Introduction
Gestion des demandes de service
Introduction
Gestion des problèmes