Gestion des incidents pour les équipes haute vélocité
Comment créer un playbook de réponse aux incidents ?
Inspirez-vous de notre manuel.
Notre mission chez Atlassian est de libérer le potentiel de chaque équipe. Le point commun des équipes performantes ? Elles utilisent des playbooks pour gérer les nombreux processus formulés pour assurer le bon fonctionnement de leur organisation.
Cet article couvre cinq étapes essentielles pour créer un playbook de réponse aux incidents efficace. Nous utiliserons notre propre Manuel de gestion des incidents Atlassian comme modèle pour développer un plan de réponse aux incidents.
Que contient un playbook de réponse aux incidents ?
Les playbooks sont un élément clé de la gestion des incidents DevOps et ITOps, ainsi que de la cybersécurité. Ils définissent les politiques et les pratiques de l'organisation pour répondre aux pannes imprévues, aident les équipes à mettre de l'ordre dans le chaos et veillent à ce que chacun réponde de manière cohérente aux incidents et aux menaces de sécurité.
Un manuel de gestion des incidents fournit à votre équipe un ensemble de processus permettant de répondre à chaque incident, de le résoudre et d'en tirer des leçons, qu'il s'agisse d'un problème de sécurité ou d'une autre vulnérabilité émergente. Le contenu peut tout inclure, des runbooks et des checklists aux modèles, aux exercices de formation, aux scénarios d'attaque de sécurité et aux exercices de simulation.
Élaboration d'un playbook de réponse aux incidents
En créant notre propre Manuel de gestion des incidents Atlassian, nous avons identifié cinq bonnes pratiques en matière de gestion d'un incident. Ces étapes peuvent être traduites pour diverses équipes DevOps et ITOps et aident à guider le processus de création d'un playbook de réponse aux incidents efficace.
1. Définissez les incidents pour votre organisation
À inclure : une définition précise de ce qui constitue un incident
Pourquoi : vous ne pouvez pas résoudre efficacement un incident si vous ne savez pas quand il se produit. Différentes équipes définissent les incidents de différentes manières. Si quelque chose ne va pas, chaque seconde compte, et la dernière chose dont vous avez besoin, c'est de débats sémantiques.
Exemple :
La définition d'un incident telle qu'elle apparaît dans le Manuel de gestion des incidents Atlassian :
Qu'est-ce qu'un incident ?
Nous définissons un incident comme un événement ayant provoqué une perturbation ou une réduction de la qualité d'un service nécessitant une réponse d'urgence. Les équipes qui adoptent les pratiques ITIL ou ITSM utilisent parfois le terme « incident majeur ».
Un incident est résolu lorsque le service affecté fonctionne de nouveau de manière habituelle. Cela inclut uniquement les tâches nécessaires à la restauration de toutes les fonctionnalités et exclut les tâches de suivi, telles que l'identification et l'atténuation de la cause profonde, qui font partie du post-mortem.
Le post-mortem de l'incident est réalisé après l'incident pour en déterminer la cause profonde et mettre en œuvre des mesures pour la corriger avant qu'elle ne provoque un nouvel incident.
2. Établissez des rôles prédéfinis
À inclure : les rôles et responsabilités associés aux incidents
Pourquoi : un playbook de réponse aux incidents approprié définit des rôles et des responsabilités clairs. Les membres de l'équipe de réponse aux incidents connaissent chaque rôle et leurs responsabilités lors d'un incident.
Exemple :
Les rôles que nous utilisons chez Atlassian ont été mis en place pour garantir que toutes les étapes nécessaires sont couvertes, qu'aucun travail n'est effectué en double et que la communication se déroule de manière fluide et efficace.
- Le gestionnaire d'incident est responsable et dispose de toute autorité pour l'incident. Il est habilité à prendre toutes les mesures nécessaires pour résoudre l'incident, ce qui implique notamment de contacter tout intervenant de l'organisation et de veiller à ce que les personnes impliquées dans un incident restent concentrées sur une restauration aussi rapide que possible du service.
- Responsable technique, un intervenant technique senior. Il est chargé de développer des théories sur les défaillances et leurs causes, de décider des changements et de diriger l'équipe technique. Il travaille en étroite collaboration avec le gestionnaire d'incident.
- Responsable des communications, une personne expérimentée en matière de communications publiques, éventuellement issue de l'équipe de support client ou des relations publiques. Il est chargé de la rédaction et de l'envoi des communications internes et externes.
3. Imposez un processus cohérent
À inclure : les étapes du processus et des workflows
Pourquoi : il n'y a pas deux incidents identiques. Mais rien n'empêche vos intervenants de mettre en place un workflow cohérent pour répondre aux incidents.
Décrivez les étapes et les phases clés et assurez-vous que les membres de l'équipe savent clairement ce qui est attendu au cours de chaque phase et ce qui va suivre. Par exemple, Atlassian décrit le flux de réponse aux incidents en sept étapes et en trois phases pour passer de la détection à la résolution.
Exemple :
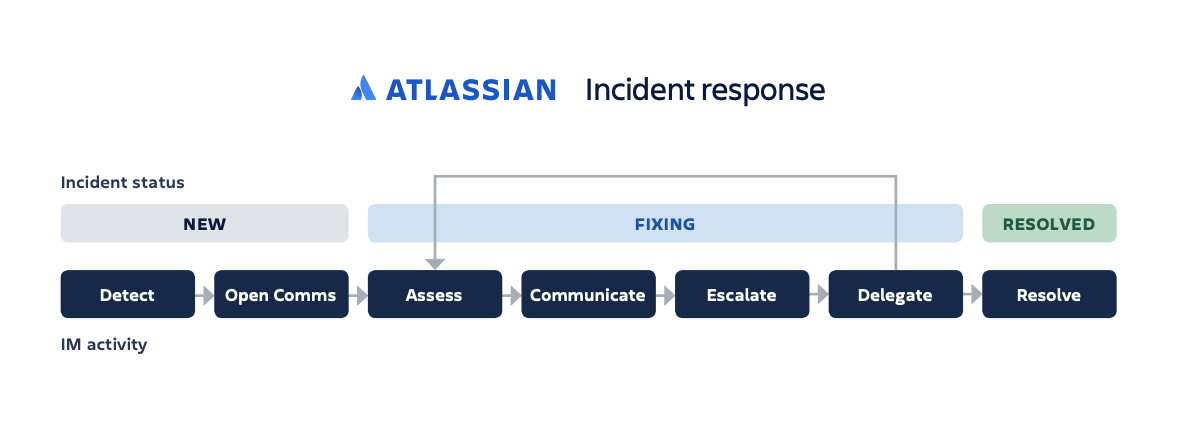
Lorsqu'un nouvel incident est détecté, le gestionnaire d'incident commence par initier une communication interne et l'organisation de la réponse. L'équipe peut alors commencer à travailler à la correction de la cause de l'incident et à la résolution de celui-ci. Une organisation solide à ce stade facilite l'action, qui est optimisée par une communication fréquente. L'adhésion à un processus cohérent permet une résolution plus rapide, y compris avec un exercice de post-mortem que nous allons aborder ci-dessous.
4. Assurez une réponse rapide
À inclure : des modèles et des checklists
Pourquoi : les playbooks d'incidents doivent être suffisamment simples pour que les équipes puissent les suivre en période de stress. Notre propre processus comprend une « aide-mémoire » du responsable de la gestion des incidents majeurs, qui décrit les étapes clés telles que l'évaluation, la remontée et la délégation dans un format d'une page.
Suivre un processus de réponse aux incidents prédéterminé ne signifie pas que toute improvisation est exclue. Il est nécessaire de faire preuve de flexibilité et de savoir quand s'adapter à une situation changeante. Les incidents, par définition, sont des scénarios dans lesquels les choses ne se déroulent pas comme prévu, mais cela ne signifie pas que vous ne pouvez pas les planifier. Les équipes qui s'entraînent et pratiquent différents scénarios sont généralement celles qui réussissent.
Utilisez ceci :
Essayez d'exécuter un scénario Valeurs de réponse aux incidents pour améliorer la cohésion de l'équipe et éliminer tout malentendu potentiel avant un incident. Utilisez notre ressource, Playbook des équipes Atlassian, pour mieux comprendre le processus de votre équipe afin de créer un playbook dynamique.
5. Facilitez des post-mortems complets
À inclure : un aperçu du processus de post-mortem et des champs du ticket
Pourquoi : un post-mortem cherche à maximiser la valeur d'un incident en comprenant toutes les causes qui y contribuent, en documentant l'incident pour référence future et la découverte de modèles, et en mettant en place des actions préventives efficaces pour réduire la probabilité de l'incident ou son impact lorsqu'il se produit de nouveau.
Si vous considérez un incident comme un investissement imprévu pour améliorer la fiabilité de votre système, le post-mortem est idéal pour maximiser le retour sur investissement.
Essayez ceci :
Pour que les post-mortems soient efficaces, le processus doit permettre aux équipes d'identifier facilement les causes et de les corriger. Les méthodes exactes que vous utilisez dépendent de la culture de votre équipe. Chez Atlassian, nous avons trouvé une combinaison de méthodes qui fonctionnent pour nos équipes de post-mortem :
- Les réunions en face à face aident à conduire une analyse appropriée et à aligner l'équipe sur les points qui nécessitent une résolution.
- Des approbations de post-mortems par les responsables des équipes de livraison et des opérations incitent les équipes à les mener à bien.
- Les actions prioritaires désignées ont des objectifs de niveau de service (SLO) assignés, avec des rappels et des rapports pour s'assurer qu'elles sont mises en œuvre.
Un aperçu étape par étape du post-mortem de réponse aux incidents d'Atlassian se trouve à la page 46 de notre Manuel de gestion des incidents.
En fin de compte, un playbook de réponse aux incidents doit être utilisé pour inciter les équipes à collaborer efficacement afin de résoudre les incidents le plus rapidement possible. Lorsqu'un incident se produit, personne n'a le temps de débattre des bonnes pratiques et de chercher un coupable. Des playbooks complets et bien conçus permettent aux équipes de donner le meilleur d'elles-mêmes. Chez Atlassian, notre guide pour tous ces scénarios est détaillé dans notre Manuel de gestion des incidents.
Configuration d'un planning d'astreinte grâce à Opsgenie
Ce tutoriel vous apprendra à configurer un planning d'astreinte, à appliquer des règles de remplacement, à configurer les notifications d'astreinte, etc. Et tout cela, sans quitter Opsgenie.
Lire ce tutorielAvantages et inconvénients des différentes approches de gestion des astreintes
Les équipes d'astreinte évoluent rapidement. Découvrez les avantages et inconvénients des différentes approches de gestion des astreintes.
Lire cet article