Gestion des incidents pour les équipes haute vélocité
Optimisation de la gestion des incidents pour les opérations informatiques
Les pannes influent sur le résultat.
Les temps d'arrêt entraînent souvent non seulement une baisse du chiffre d'affaires, mais aussi des atteintes à la réputation, des sanctions réglementaires ou pour non-conformité, une perte de clients et une augmentation des coûts opérationnels et des retards, car les professionnels de l'informatique doivent interrompre leur travail sur d'autres projets pour résoudre les incidents.
En fait, un rapport d'IHS a estimé que les temps d'arrêt coûtaient aux entreprises nord-américaines plus de 700 milliards de dollars par an, 78 % étant attribuables à la perte de productivité des employés.
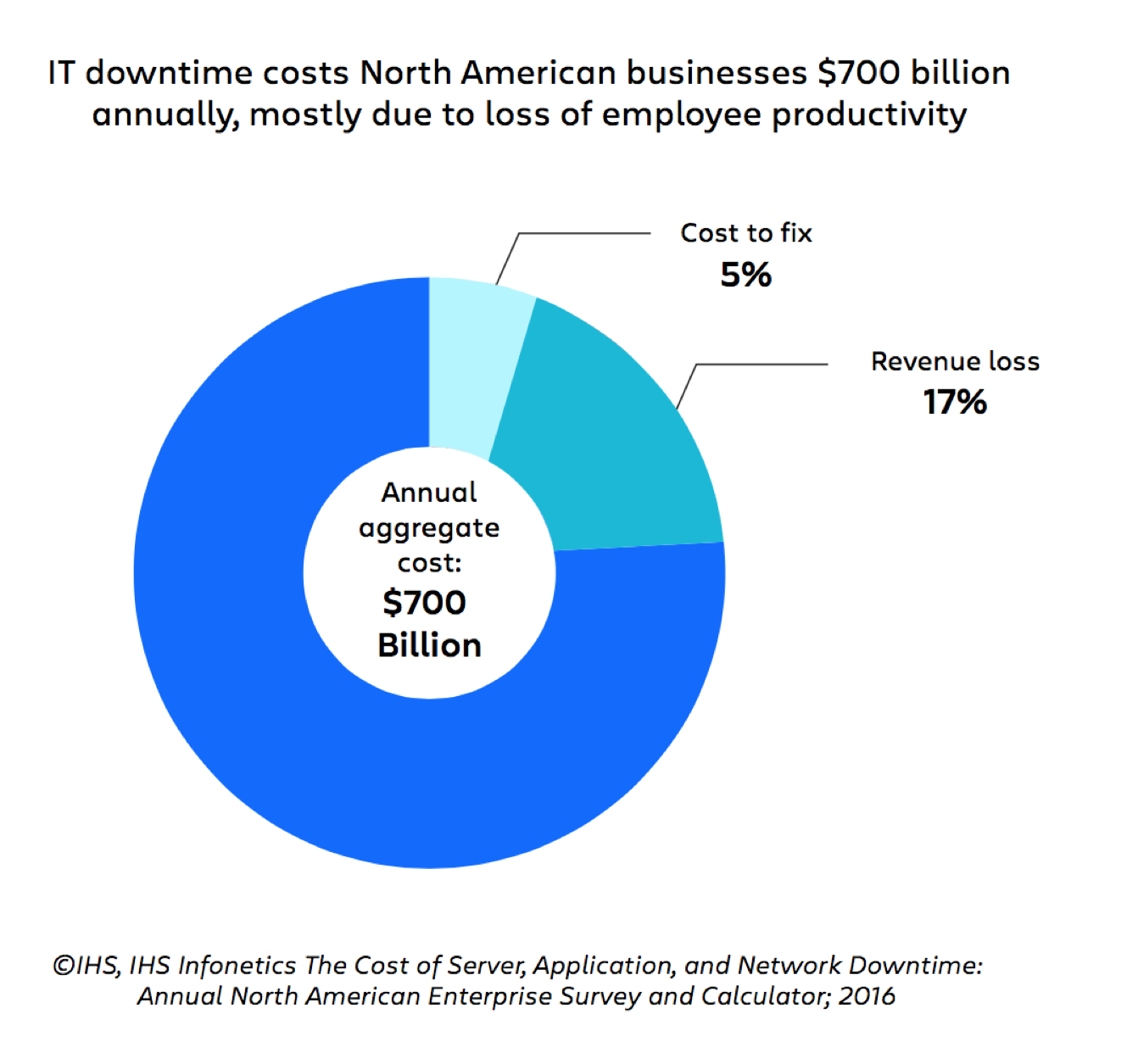
Des chiffres comme ceux-ci montrent clairement que la perte de chiffre d'affaires n'est pas la seule, ni même la plus importante, priorité de la gestion des incidents. Un processus de gestion des incidents optimisé doit également relever les défis bien réels et très coûteux que représentent les personnes, les processus et la technologie sur lesquels repose la gestion des incidents.
Les défis de la gestion moderne des incidents informatiques
Processus et technologies déconnectés
L'inconvénient de 40 années d'innovation informatique ? Beaucoup d'entreprises exploitent désormais un mélange éclectique d'apps et de systèmes. Certaines apps sont hébergées dans leurs propres data centers, où elles peuvent être contrôlées de près, tandis que d'autres sont fournies dans le cloud et gérées par des fournisseurs tiers.
Cette collection d'apps, de services et de systèmes se traduit souvent par un patchwork étroitement connecté de solutions et de processus de journalisation, de surveillance et d'alerte. Il n'est pas rare que les entreprises utilisent des dizaines d'outils de surveillance pour suivre chaque jour des milliers d'événements applicatifs ou d'alertes.
Cette approche fragmentée peut conduire à un volume incalculable d'alertes, à une rupture de la communication, à l'absence de priorités claires pour les employés d'astreinte et à une situation dans laquelle le moindre échec à un point ou l'autre de ce processus peut mettre à mal l'ensemble.
Un volume incalculable d'alertes/d'incidents
De nombreux services informatiques opérationnels redirigent les alertes vers les boîtes de réception pour remédier au problème de volume. Mais cela ne fait qu'empirer les choses : elles créent une situation dans laquelle les e-mails doivent être surveillés 24 h/24 et 7 j/7 par du personnel expérimenté chargé de hiérarchiser les incidents et de faire remonter les messages critiques.
Ce flux sans fin d'alertes peut être envahissant et conduire à une fatigue d'alerte, au burn-out, au mécontentement professionnel, à de l'anxiété et à des délais de réponse allongés. Cela impacte à la fois le bien-être des employés au travail et la productivité, et se répercute directement sur les résultats de l'entreprise.
Augmentation des coûts d'exploitation
Bien que les coûts d'infrastructure aient diminué, les coûts d'exploitation ont augmenté. Cette augmentation est en partie due au débogage complexe des problèmes lorsque vous ne contrôlez pas l'ensemble du système.
Mesure des mauvaises métriques de réussite
Le succès des équipes opérationnelles au sein du centre de services a souvent été mesuré à l'aide de métriques telles que le nombre d'appels et la durée moyenne d'appel, qui n'améliorent et ne mesurent pas directement l'efficacité de la gestion des incidents.
Même des métriques utiles telles que la MTTR et le MTBF ne sont pas suffisantes pour optimiser la gestion des incidents. Elles sont là pour nous aider à identifier un problème, mais elles ne peuvent pas répondre aux questions de qualité plus délicates, c'est-à-dire pourquoi et comment les incidents se produisent et sont résolus, ou encore comment améliorer ces métriques.
Structures obsolètes de l'équipe de réponse aux incidents
Jusqu'à la dernière décennie, la réponse aux incidents informatiques était la principale tâche des équipes opérationnelles. Les organisations implémentaient généralement une structure d'équipe par niveau (Niveau 1, Niveau 2, Niveau 3) pour répondre aux tickets créés par les clients ou les outils de surveillance.
À l'époque, les objectifs de la gestion des incidents étaient les mêmes, à savoir : minimiser les coûts opérationnels tout en maintenant les niveaux de service. Pour cette raison, les intervenants de niveau 1 étaient généralement des employés débutants et peu coûteux. S'ils ne parvenaient pas à résoudre un incident, ils faisaient remonter au niveau 2 (généralement des professionnels de niveau intermédiaire plus expérimentés). Ce processus de remontée se poursuivait jusqu'à ce que le problème soit résolu.
Bien que ce processus priorise les économies en matière de coûts, il le fait au détriment de l'agilité. Le temps de réponse plus lent d'une équipe qui débute la gestion des incidents avec des employés débutants et nécessite plusieurs niveaux de remontée peut avoir un impact immédiat sur les délais de résolution des incidents. Cela se répercute directement sur la réputation de l'entreprise lorsque la frustration des clients se répand sur les réseaux sociaux.
De plus, comme 78 % du budget de gestion des incidents des entreprises est alloué à la productivité des employés, il est évident qu'un modèle de remontées ne permet pas à l'entreprise de réaliser des économies. Si la personne qui a développé le logiciel peut corriger le bug en 15 minutes et que votre employé débutant y consacre deux heures et doit de toute façon le faire remonter, ce n'est pas un système efficace.
Dans un monde de services disponibles en continu, l'agilité est devenue plus importante que jamais. Des métriques telles que le temps moyen de réponse et la durée moyenne de résolution ont gagné en popularité précisément parce que les entreprises doivent maximiser leur agilité si elles veulent minimiser les coûts.
Comment optimiser votre processus de gestion des incidents informatiques
Il est clair que le moment est venu de recentrer nos efforts de gestion des incidents grâce à des processus, des structures d'équipe et des pratiques qui reflètent les nouvelles réalités commerciales. Mais à quoi ressemble ce processus de recentrage ?
Priorisez et consolidez les alertes
Le surplus d'alertes inutiles et non exploitables est le principal responsable de la fatigue d'alerte et un facteur clé de la perte de productivité. La solution la plus simple ? Identifiez les systèmes essentiels, dédupliquez les notifications redondantes et créez une hiérarchie de priorisation claire des alertes.
Créez un planning d'astreinte qui fonctionne pour vos équipes
Éviter la fatigue d'alerte, le burn-out et les inefficacités implique également de créer un planning d'astreinte qui fonctionne pour vos équipes. Cela signifie ne pas surcharger une personne ou une équipe, prévoir un back-up au besoin et réévaluer régulièrement l'efficacité de votre planning.
Automatisez ce qui peut l'être
Il est facile de perdre de vue votre objectif lorsque vous fouillez manuellement dans des dizaines de rapports pour identifier et reproduire ceux qui comptent. La bonne nouvelle ? Grâce à l'automatisation, cette tâche n'a plus à être réalisée manuellement par un membre de l'équipe, et vous pouvez éviter la perte de productivité et la fatigue d'alerte associées.
L'acheminement des alertes, les notifications, la déduplication, les workflows de messages, la création de ponts de conférence, les mises à jour de pages d'état, la planification des astreintes, les processus de remontée et le suivi des KPI sont des tâches qui peuvent également être automatisées en tout ou partie pour faire gagner du temps à l'équipe et réduire les erreurs humaines pour les tâches répétitives définies. Sans parler du fait que l'automatisation permet à l'entreprise d'économiser de l'argent au fil du temps.
Communiquez efficacement entre les canaux et les parties prenantes
Les incidents impactent différentes parties prenantes, souvent internes et externes, et elles doivent être informées. Les études montrent que 87 % des parties prenantes métier veulent des mises à jour sur les incidents (et 56 % sont plus frustrées par le manque de communication que par l'incident lui-même). De plus, les clients ressentent certainement la même chose.
À une époque qui exige une disponibilité continue, avoir un solide plan de communication sur les incidents en place est une pièce essentielle du puzzle de l'optimisation.
Facilitez le suivi des bonnes métriques
Plus il est facile de suivre les métriques de réussite et de les examiner, plus votre équipe est susceptible de s'y adapter. Automatisez les rapports lorsque cela est possible et déterminez dès le départ les indicateurs qui sont importants pour votre équipe et pourquoi.
Menez des post-mortems sans reproches
Un incident n'est pas terminé simplement parce que l'app ou la base de données est de nouveau en ligne. Pour prévenir les incidents, réduire le temps consacré aux incidents futurs et mieux comprendre l'impact de vos processus, équipes et stratégies sur votre gestion des incidents, vous devez mener des post-mortems.
Chez Atlassian, nos post-mortems sont sans reproches, ce qui signifie qu'ils se concentrent sur l'amélioration des performances et l'avancement dans le travail, sans pointer quiconque du doigt.
Choisissez une technologie qui soutient vos processus et vos besoins
Automatisation. Priorisation des alertes. Planification des astreintes. Suivi des KPI. Pour être efficace, chacun de ces processus essentiels doit reposer sur une technologie. Avant de choisir votre technologie, assurez-vous de bien comprendre vos objectifs, vos processus et les besoins de votre équipe. Si vous souhaitez organiser, dédupliquer et prioriser automatiquement les alertes, vous avez besoin d'une solution dotée de ces fonctionnalités, comme Jira Service Management.
Découvrez la communication sur les incidents grâce à Statuspage
Dans ce tutoriel, nous allons vous montrer comment utiliser des modèles d'incident pour communiquer efficacement pendant les pannes. Vous pouvez les adapter à de nombreux types d'interruption de service.
Lire ce tutorielModèles et exemples de communication sur les incidents
Lorsque vous répondez à un incident, les modèles de communication sont d'une valeur inestimable. Obtenez les modèles que nos équipes utilisent, ainsi que d'autres exemples pour les incidents courants.
Lire cet article