Gerenciamento de incidentes para equipes de alta velocidade
Como escolher KPIs e métricas de gerenciamento de incidentes
Acompanhamento e melhoria do gerenciamento de incidentes ao longo do tempo
No mundo sempre ativo de hoje, incidentes de tecnologia trazem consequências significativas.
O tempo de inatividade do sistema custa às empresas uma média de US$ 300.000 por hora em perda de receita, produtividade dos funcionários e encargos de manutenção. Interrupções significativas podem superar muito esses custos (basta perguntar à Delta Airlines, que perdeu cerca de US$ 150 milhões após uma interrupção de TI em 2017). E os clientes que não conseguem pagar suas contas, fazer videoconferência para uma reunião importante ou comprar uma passagem de avião são rápidos em transferir seus negócios para um concorrente.
Com tanta coisa em jogo, é mais importante do que nunca que as equipes acompanhem KPIs de gerenciamento de incidentes e usem suas descobertas para detectar, diagnosticar, consertar e — por fim — evitar incidentes.
A boa notícia é que, com incidentes na web e software (ao contrário dos sistemas mecânicos e off-line), as equipes costumam ser capazes de capturar muito mais dados para ajudar na compreensão e aprimoramento.
A má notícia? Às vezes, muitos dados podem ocultar itens em vez de evidenciá-los.
O valor dos KPIs, métricas e análises de incidentes
Os KPIs (Indicadores-chave de desempenho) são métricas que ajudam as empresas a determinar se estão atingindo metas específicas. Para o gerenciamento de incidentes, essas métricas podem ser o número de incidentes, tempo médio para resolver ou tempo médio entre incidentes.
O acompanhamento de KPIs para gerenciamento de incidentes pode ajudar a identificar e diagnosticar problemas com processos e sistemas, definir benchmarks e metas realistas para a equipe trabalhar e oferecer um ponto de salto para perguntas maiores.
Por exemplo, supondo que o objetivo da empresa seja resolver todos os incidentes em 30 minutos, mas, no momento, a equipe está com uma média de 45 minutos. Sem métricas específicas, é difícil saber o que está dando errado. Seu sistema de alerta está demorando muito? Seu processo está quebrado? Suas ferramentas de diagnóstico precisam ser atualizadas? É um problema de equipe ou um problema de tecnologia?
Agora, adicione algumas métricas: se você sabe exatamente quanto tempo o sistema de alerta está demorando, você pode identificá-lo como um problema ou descartá-lo. Se você perceber que os diagnósticos estão ocupando mais de 50% do tempo, você pode concentrar sua solução de problemas neles. Se você observar que a equipe B está levando 25% mais tempo do que as equipes A, C e D, você pode começar a investigar o motivo.
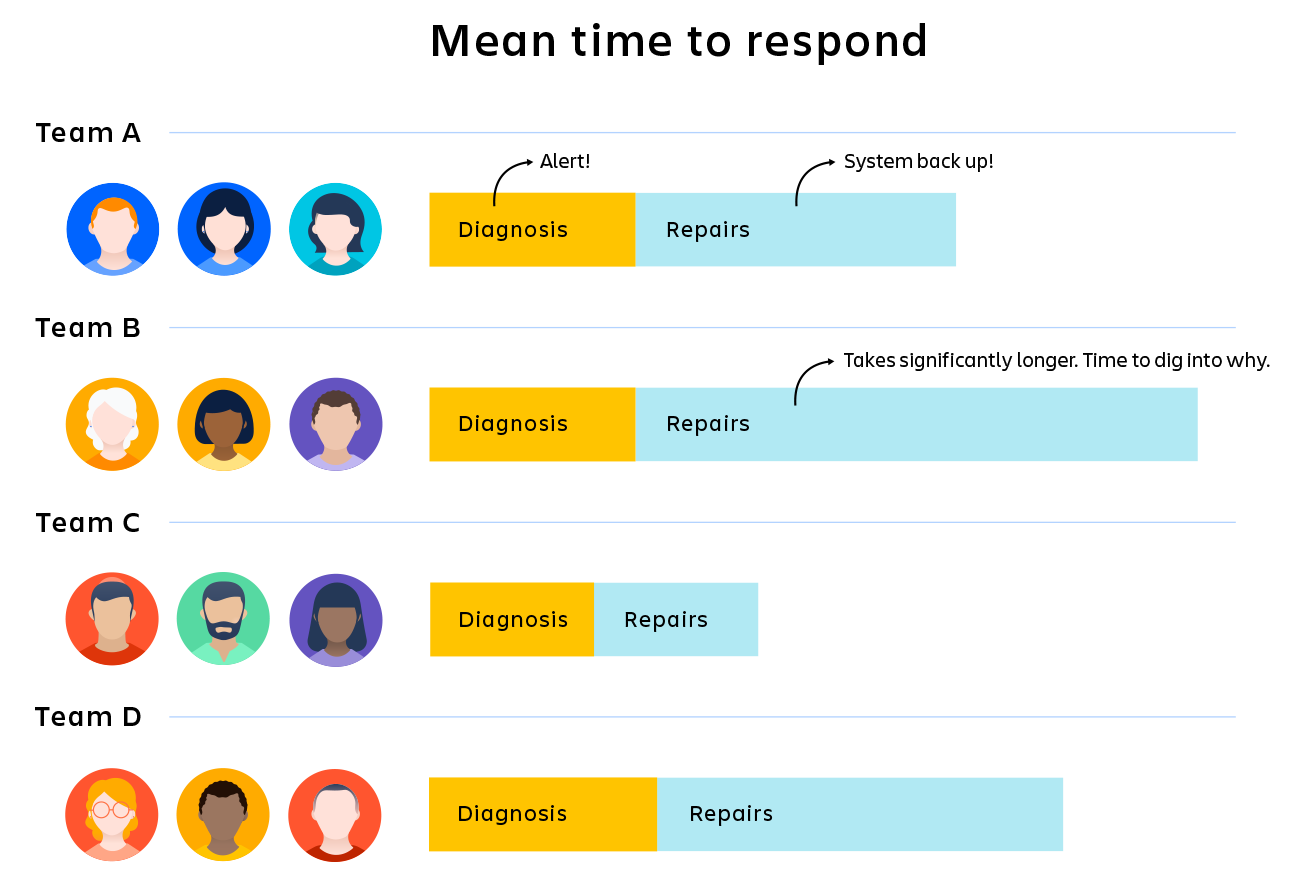
Os KPIs não fazem correções automáticas dos problemas, mas vão ajudar você a entender onde está o problema e focar sua energia nos lugares certos.
KPIs e métricas populares de incidentes
Alertas criados
Se você estiver usando uma ferramenta de alerta, é útil saber quantos alertas são gerados em um determinado período. Usando uma solução como o Jira Service Management, você pode enviar alertas e criar relatórios e painéis para rastreá-los.
Observe os períodos com aumentos ou diminuições significativos e atípicos ou números com tendência crescente e, quando os vir, aprofunde-se no motivo dessas mudanças estarem acontecendo e em como suas equipes estão lidando com elas.
Incidentes ao longo do tempo
Acompanhar incidentes ao longo do tempo significa analisar o número médio de incidentes ao longo do tempo. Esse acompanhamento pode estar semanal, mensal, trimestral, anual ou até mesmo diário.
A frequência dos incidentes está aumentando ou diminuindo ao longo do tempo? O número de incidentes é aceitável ou poderia ser reduzido? Depois de identificar um aumento inaceitável no número de incidentes, você pode começar a fazer perguntas sobre por que esse número está aumentando ou permanecendo alto e o que a equipe pode fazer para resolver o item.
MTBF
MTBF (tempo médio entre falhas) é a média de tempo entre falhas reparáveis de um produto tecnológico. Ele pode ajudá-lo a acompanhar a disponibilidade e a confiabilidade em todos os produtos.
Assim como as outras métricas, é um bom ponto de salto para perguntas maiores. Se o seu MTBF for menor do que você quer que seja, é hora de perguntar por que os sistemas estão falhando com tanta frequência e como você pode reduzir ou evitar falhas futuras.
MTTA
MTTA (tempo médio de reconhecimento) é o tempo médio entre um alerta do sistema e quando um membro da equipe reconhece o incidente e começa a trabalhar para resolvê-lo. O valor aqui é entender como a equipe é responsiva aos itens.
Depois de constatar que há um problema de responsividade, você pode começar a se aprofundar de novo. Por que o seu MTTA está alto? As equipes estão sobrecarregadas? Distraídas? Não está claro de quem é a responsabilidade por um alerta? O MTTA pode ajudar a identificar um problema e perguntas como essa podem ajudar a chegar à raiz desse problema.
MTTD
O MTTD (tempo médio para detectar) é a média de tempo que a equipe leva para descobrir um item. Este termo costuma ser usado em cibersegurança quando as equipes estão focadas em detectar ataques e violações.
Se essa métrica muda muito ou não está atingindo a marca, é, mais uma vez, hora de perguntar por quê.
MTTR
MTTR pode significar tempo médio para reparar, resolver ou recuperar. Sem dúvidas, a mais útil dessas métricas é o tempo médio para a resolução, que rastreia não apenas o tempo gasto diagnosticando e corrigindo um problema imediato, mas também o tempo gasto garantindo que o item não aconteça de novo. A recuperação é uma métrica de DevOps básica, destacada pelo DevOps Research and Assessment (DORA) como fundamental para medir a estabilidade de uma equipe de DevOps.
De novo, essa métrica é melhor quando usada em diagnósticos. Os tempos de resolução são tão rápidos e eficientes quanto você quer que sejam? Se não, é hora de fazer perguntas mais profundas sobre como e por que esse tempo de resolução não está sendo cumprido.
A recuperação é uma métrica de DevOps importante que avalia a estabilidade de uma equipe de DevOps, como observado pelo DevOps Research and Assessment (DORA). Consiste no tempo total necessário para detectar, mitigar e resolver um problema.
Tempo de plantão
Se você tiver uma rotação de plantão, pode ser útil rastrear quanto tempo os funcionários e contratadas gastam em plantão. Essa métrica pode ajudá-lo a garantir que nenhum funcionário ou equipe fique sobrecarregado.
Com o Jira Service Management, você pode gerar relatórios abrangentes para ver esses números com rapidez.
SLA
Um SLA (acordo de nível de serviço) é um acordo entre o provedor e o cliente sobre métricas mensuráveis, como tempo de atividade, responsividade e responsabilidades.
As promessas feitas nos SLAs (sobre tempo de atividade, tempo médio para recuperação, etc.) são uma das razões pelas quais as equipes de gerenciamento de incidentes precisam acompanhar essas métricas. Se e quando o tempo médio de resposta ou tempo médio entre as falhas mudarem, os contratos precisam ser atualizados e/ou correções precisam ser feitas — com rapidez.
SLO
Um SLO (objetivo de Nível de Serviço) é um acordo dentro de um SLA sobre uma métrica específica, como o tempo de atividade. Assim como o SLA, os SLOs são métricas importantes a serem acompanhadas para garantir que a empresa esteja cumprindo seus objetivos de atendimento ao cliente.
Carimbos de data/hora (ou cronograma)
Um carimbo de data/hora é codificado com informações sobre o que aconteceu em momentos específicos durante, antes ou depois do incidente. Essas informações geralmente não são consideradas como uma métrica, mas são dados importantes para ter ao avaliar a integridade do gerenciamento de incidentes e criar estratégias para melhorar.
Os carimbos de data/hora ajudam as equipes a criar cronogramas do incidente, junto com os esforços de liderança e resposta. Um cronograma claro e compartilhado é um dos artefatos mais úteis durante a análise retrospectiva de um incidente.
Tempo de atividade
O tempo de atividade é o tempo (representado como uma porcentagem) em que seus sistemas estão disponíveis e funcionais.
A crescente conectividade dos serviços on-line e a crescente complexidade dos próprios sistemas significam que normalmente não há tempo de atividade 100% garantido. A meta para a maioria dos produtos é a alta disponibilidade— ter um sistema ou produto em operação sem interrupção por longos períodos. O padrão da indústria afirma que 99,9% de tempo de atividade é muito bom e 99,99% é excelente.
Acompanhar seu sucesso em relação a esta métrica significa fazer e manter as promessas dos clientes. E, como outras métricas, é apenas um ponto de partida. Se o seu tempo de atividade não estiver em 99,99%, a pergunta sobre o motivo vai exigir mais pesquisas, conversas com a equipe e investigação sobre processo, estrutura, acesso ou tecnologia.
Uma advertência sobre a análise de incidentes
A desvantagem dos KPIs é que é fácil se tornar muito dependente de dados rasos. Saber que sua equipe não está resolvendo incidentes com rapidez suficiente por si só não levará a uma solução. Porque você ainda precisa saber como e por que a equipe está ou não resolvendo itens. E você ainda precisa saber se os itens que você está comparando são mesmo comparáveis.
Os KPIs não podem dizer como as equipes abordam itens complicados. Eles não podem explicar por que seu tempo entre incidentes está ficando mais curto em vez de mais longo. Eles não podem dizer por que o Incidente A levou três vezes mais tempo que o Incidente B.
Portanto, você precisa de insights. E embora os dados possam ser um ponto de partida no caminho para esses insights, também podem ser um obstáculo. Eles podem dar a impressão de que a gente está fazendo o suficiente, mesmo que as métricas não estejam melhorando. Eles podem reunir incidentes que são muito diferentes e precisam de uma abordagem diferente. Eles podem desconsiderar a experiência das equipes e a complicação subjacente dos incidentes.
"Os incidentes são muito mais peculiares do que o senso comum diz. Dois incidentes da mesma extensão podem ter níveis muito diferentes de surpresa e incerteza em como as pessoas entenderam o que estava acontecendo. Eles também podem conter riscos muito diferentes no que diz respeito à tomada de ações destinadas a mitigar ou melhorar a situação. Incidentes não são widgets sendo fabricados, onde a variação limitada nas dimensões físicas é vista como marcadores-chave de qualidade.”
- John Allspaw, Transferindo dados de incidentes rasos passados
A questão não é que os KPIs sejam ruins. A gente não quer que você jogue o bebê fora junto com a água do banho. A questão é que os KPIs não são suficientes. São um ponto de partida, uma ferramenta de diagnóstico. São o primeiro passo para uma estratégia mais complexa de melhoria genuína.
O Jira Service Management oferece recursos de relatório para que a equipe possa acompanhar os KPIs, além de monitorar e otimizar a prática de gerenciamento de incidentes.
Configuração de um on-call schedule com o Opsgenie
Neste tutorial, aprenda a configurar um on-call schedule, aplicar regras de substituição, configurar notificações de plantão e muito mais. Tudo no Opsgenie.
Leia este tutorialExemplos e templates de comunicação de incidentes
Ao responder a um incidente, os templates de comunicação são inestimáveis. Veja os templates que as equipes usam e mais exemplos de incidentes comuns.
Leia este artigo