ベロシティの高いチームのためのインシデント管理
インシデントと問題管理の役割の変化
過去 10 年間で、インシデント管理は大きく変わりました。
ITIL のガイドラインが更新されました。IT チームは、DevOps および SecOps と責任を共有しています。これまで以上に複雑なシステムのおかげで、インシデント管理ソリューションもより複雑になりました。さらに、多くの企業では、誰も責めることのない事後分析やパフォーマンスの新しい測定方法を採用しています。
インシデント管理が変化し進化し続けている中で、インシデント管理と密接な関係にある問題管理、そしてこの 2 つのプラクティスの関係も変化しています。
問題とは何でしょうか? また、インシデントとどう違うのでしょうか?
ITIL は、問題を「1 つ以上のインシデントの原因、または潜在的な原因」と定義しています。
インシデントとは、サービスの中断を引き起こす単一の予期しないイベントです。
言い換えれば、インシデントとは、オンコールの従業員が可能な限り迅速かつ完全に解決するために奔走する厄介な出来事のことです。そして問題とは、そのような中断を引き起こす根本的な原因のことです。
問題によって 1 つのインシデントが発生したり、複数のインシデントが発生したりする場合があります。また、インシデントは 1 つの問題に起因する場合もあれば、複数の問題に起因する場合もあります

たとえば、2016 年に Delta Airlines が 1 億 5000 万ドルの損害を出した 5 時間の停電はインシデントでした。インシデントの原因となった問題は、オペレーション センターでの電源の損失であり、おそらく、電源が失われた場合のバックアップ プランがなかったことです。
同様に、Apple に推定 2500 万ドルの損害を与えた 12 時間のアプリ ストアの停止もインシデントでした。その背景にある問題とは何でしょうか? DNS の問題です。
テクノロジーの世界の外でこれらの用語を使用するならば、たとえば片頭痛で医者に駆け込むことはインシデントになります。アレルギーや視力の問題、ストレスなど、片頭痛の原因が問題となります。
問題管理とインシデント管理の比較
問題とインシデントが密接にリンクしていることは明らかです。一方が他方を引き起こしますが、チームは両方に注意を払わなければなりません。
従来の IT チームにとって、最新の ITIL ガイドラインでは、問題とインシデントの両方を管理するように求められますが、それらは別々に管理することになっています。問題管理は、インシデントの防止またはその影響の軽減に重点を置いたプラクティスです。インシデント管理は、インシデントにリアルタイムで対処することに重点を置いています。
ITIL アプローチのメリットは、問題管理とインシデント管理の両方の中核となる目標に優先順位を付ける点です。おそらくこのガイドラインは、これらを分離して同様に重要なプラクティスにすることで、IT チームがインシデントの根本原因に対処することなく、インシデントを常に解決するという、よくある問題を回避しようとしています。
インシデント マネージャーの主な目標がインシデントの迅速な解決であり、問題マネージャーの主な目標が予防である場合、これらの役割を組み合わせてしまうと、それらの目標の一方 (いずれも組織にとって不可欠です) が、他方の優先順位を低下させてしまう可能性があります。
このアプローチの欠点は、実際には非常に密接に関連している 2 つのプラクティスを分離すると、知識のギャップが生じ、インシデントの解決と根本的な原因につながる原因分析との間のコミュニケーションが断絶してしまうことです。
DevOps、および問題管理とインシデント管理の役割の変化
例に漏れず、コラボレーションによる DevOps の取り組みは、従来の IT 思考の境界を曖昧にしています。つまり、問題管理とインシデント管理を 2 つの異なるプラクティスとしてではなく、全体的な視点の中で重なり合う部分として捉えます。
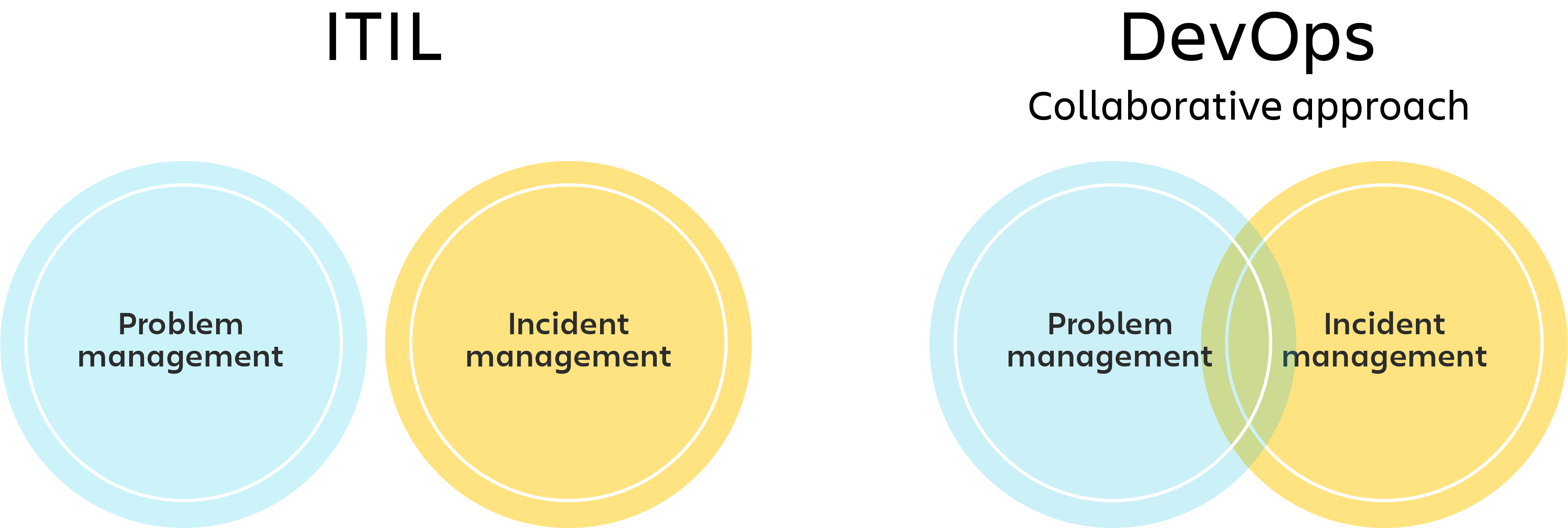
この変化は、問題管理とインシデント管理が表裏一体である (インシデントを防ぎ、解決する) という事実だけでなく、一般的に次のことを肯定する DevOps のアプローチからも生じています。
- 多くの場合、インシデントには複数の根本原因がある
- 事後分析は誰かを責めるべきではなく、インシデントによって影響を受けるすべてのチームを含める必要がある
- 継続的改善の中核をなしているのはコラボレーションである
問題管理とインシデント管理の重複は、業界全体が「コードを作った人が、運用の責任も持つ」というアプローチに移行していることと関係があるかもしれません。システムを構築するチームが、それらのシステム内のインシデントを解決する責任を負うようになると、事後分析の実施、インシデントの根本原因究明のための調査作業、将来、インシデントの影響を防止または軽減する推奨事項の作成を、同じチームが責任を負うことは理にかなっています。
ここでいう問題管理とインシデント管理の橋渡しとは、誰も責めることのない事後分析のことであり、緊急性が薄れると、インシデント マネージャーは探偵のように問題管理と予防の作業に専念することになります。
これら 2 つのプラクティスの境界を曖昧にしている DevOps チームが直面する重要な課題は、インシデント管理の緊急性を優先することで、問題管理 (緊急性は低いが、非常に価値のある長期目標が絡む) が優先度を下げられないようにすることです。
もちろん、インシデント管理と問題管理を一体化することは、言うは易し行うは難しですが、根本原因を突き止めて解決するためには不可欠なことです。インシデント管理ソリューションの Jira Service Management により、チームがインシデントを解決しながらコンテキストを記録し、豊富なタイムラインを作成して、問題をよりよく管理できるようになり、チームが柔軟に共同作業を行えるようになる方法についてご覧ください。
Opsgenie を使用したオンコール スケジュールの設定
このチュートリアルでは、オンコール スケジュールの設定、オーバーライド ルールの適用、オンコール通知の設定などの方法を学習します。すべて Opsgenie 内で行います。
このチュートリアルを読む