ベロシティの高いチームのためのインシデント管理
IT 運用のインシデント管理を最適化する
停止は収益に影響します。
ダウンタイムは、多くの場合、収益の損失だけでなく、風評被害、コンプライアンスおよび規制上の罰則、顧客離れ、および IT の専門家が他のプロジェクトからインシデント解決に振り向けられることによる運用コストと遅延の増加につながります。
実際、IHS のあるレポートでは、北米の組織のダウンタイム コストは年間 7 千億ドルを超えて、そのコストの 78% は従業員の生産性の低下によるものだとされています。
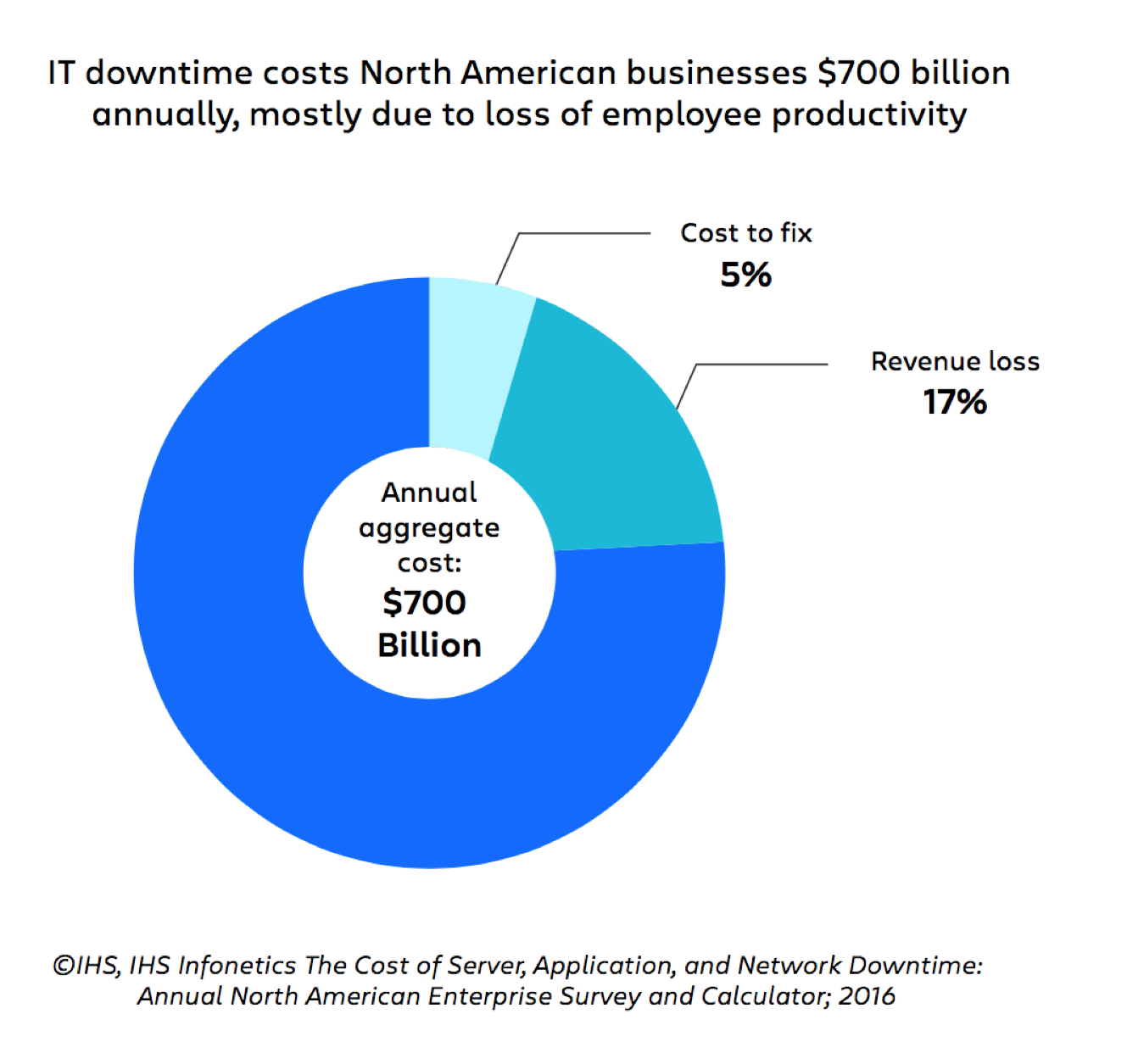
このような数字により、収益の損失がインシデント管理の唯一の優先事項ではなく、最も重要な要素ですらないことが明らかになります。また、最適化されたインシデント管理プロセスでは、インシデント管理の背景にある人、プロセス、テクノロジーが抱える非常に現実的で、コストがかかる課題に対処する必要があります。
最新の IT インシデント管理が直面している課題
分断されたプロセスとテクノロジー
コンピューティング イノベーションの 40 年間がもたらした副作用は、多くの企業がアプリケーションとシステムを折衷的な組み合わせで運用していることです。アプリケーションの中には、密接に制御できる独自のデータ センターで稼働するものもあれば、クラウドで提供されてサードパーティ プロバイダーによって管理されるアプリケーションもあります。
このようなアプリケーション、サービス、システムの集合によって、多くの場合はロギング、監視、アラート用のソリューションとプロセスのパッチワークが緊密に接続されます。企業では、毎日数千ものアプリケーション イベントやアラートを追跡するために、数十個の監視ツールを使用することは珍しくありません。
このパッチワーク アプローチは、膨大な量のアラート、コミュニケーションの断絶、オンコール対応従業員にとっての明確な優先順位の欠如、このパッチワーク プロセスの 1 つの段階での障害によってすべてが停止する可能性がある状況に繋がりかねません。
膨大な量のアラート/インシデント
多くの IT 運用部門では、大量の問題に対処するためにアラートをメール ボックスに注ぎ込みます。しかしこれによって状況はさらに悪化して、インシデントの優先順位付けと重要なメッセージのエスカレーションを担当するシニア レベルのスタッフによる年中無休の監視を必要とする状況に陥ります。
この終わることのないアラートの波に圧倒されそうになると、アラートによる疲弊、燃え尽き症候群、仕事への不満、不安、より長い応答時間を招きます。これは職場における従業員の福利と生産性の両方に影響して、ビジネスの収益に直接影響します。
運用コストの増加
インフラストラクチャ コストは減少しましたが、運用コストは増加しました。システム全体を制御しない場合は、課題のデバッグが複雑になることがその原因の 1 つとなっています。
間違った成功指標の測定
サービス デスク運用の成功は多くの場合は、コール スループットや平均コール時間などの指標を使用して測定されています。これらの指標は、インシデント管理の有効性に寄与するものでもなければ直接測定するものでもありません。
MTTR や MTBF のような有用な指標ですら、インシデント管理パフォーマンスの向上には不十分です。課題の特定に役立つものですが、インシデントの発生理由と解決方法、それらの指標を改善する方法について、より明確で定性的な疑問に答えられません。
旧態依然としたインシデント対応チームの構造
10 年前までは、IT インシデントへの対応は運用チームの主な仕事でした。組織は通常、顧客や監視ツールによって報告された課題に対応するために、階層化されたチーム構造 (レベル 1、レベル 2、レベル 3) を実装していました。
当時のインシデント管理の目標は、現在と同様、サービス レベルを維持しながら運用コストを最小化することでした。そのため、レベル 1 の対応者は、通常、低コストのエントリ レベルの従業員でした。このレベルでインシデントを解決できなかった場合は、レベル 2 (通常はより経験豊富な中級プロフェッショナル) にエスカレーションされていました。このエスカレーション プロセスは、課題が解決するまで続きます。
このプロセスでは、コスト削減を優先してアジリティを犠牲にしています。エントリ レベルの従業員がインシデントを開始して、複数のレベルのエスカレーションを必要とするチームでは、対応時間が長くなることで、インシデント解決のタイムラインに即座に影響が出る可能性があります。これによって顧客のフラストレーションがソーシャル メディア チャンネル全体で広がるため、企業の評判に直接影響します。
さらに、企業は従業員の生産性に対してインシデント管理費用の 78% を失うため、エスカレーション モデルによって実際には企業のコストを節約できないことは明らかです。ソフトウェアを構築した人が 15 分でバグを修正できるにもかかわらず、エントリ レベルの人が 2 時間を費やしてエスカレーションする必要があるなら、それは効率的なシステムではありません。
常時稼働サービスの世界では、アジリティがかつてないほど重要になっています。平均対応時間や平均解決時間などの指標の重要性が高まっているのは、企業がコストを最小化するにはアジリティを最大化する必要があるためです。
IT インシデント管理プロセスを最適化する方法
現在の新しいビジネスの現実を反映したプロセス、チーム構造、プラクティスによって、インシデント管理の取り組みを見直すべきであることは明らかです。しかし、その見直しプロセスはどのようなものでしょうか?
アラートの優先順位付けと統合
アラート疲労の主な原因であり、そして生産性の低下に繋がる主な要因は、無意味で実行不可能な大量のアラートです。最も簡単な解決方法は何でしょうか? 重要なシステムを特定して冗長な通知の重複をなくし、アラートの明確な優先順位付け階層を作成することです。
チームに適したオンコール スケジュールの作成
アラートによる疲弊、燃え尽き症候群、非効率性の回避は、チームにとって有用なオンコール スケジュールの作成も意味します。このことは、1 人またはチームへの過剰な負担の回避、必要に応じたバックアップ サポートの提供、スケジュールの有効性の定期的な再評価を意味します。
できる場所を自動化
重要なレポートを特定してエスカレーションするために数十件のレポートを手動で分類すると、確実に集中力を失います。良い点は、これはもはやチーム メンバーが手動で行う必要はないということです。自動化によってタスク リストから削除することで、生産性の低下やアラートによる疲弊を回避できます。
アラート ルーティング、通知、重複除外、メッセージ ワークフロー、会議ブリッジの作成、ステータス ページの更新、オンコール スケジューリング、エスカレーション プロセス、KPI 追跡も全体的または部分的に自動化できるため、チームの時間を節約して反復的なタスクにおける人的ミスを削減できます。自動化によって長期的に会社の費用を節約できるのは言うまでもありません。
チャンネルや関係者の間で効果的にコミュニケーションを取る
多くの場合、インシデントは社内外のさまざまな関係者に影響を与えるため、それらの関係者に通知する必要があります。研究によって、ビジネス関係者の 87% が、インシデントに関する更新情報の提供を求めていること (また、56% がインシデント自体よりもコミュニケーション不足にフラストレーションを感じていること) がわかっています。そして、顧客は間違いなく同じように感じています。
常時稼働が期待される場合、しっかりとしたインシデント コミュニケーション計画を立てることは、最適化のパズルの重要なピースです。
適切な使用を簡単に追跡できるようにする
成功指標を追跡して確認することが簡単になるほど、チームはそれを達成できる可能性が高くなります。可能な場合はレポートを自動化して、チームにとって重要な指標とその理由を前もって明確にします。
非難なき事後分析を実施する
アプリまたはデータベースがオンラインに戻っただけでは、インシデントは終わりません。インシデントを防止して将来のインシデントに費やす時間を短縮し、プロセス、チーム、ポリシーがインシデント管理にどのような影響を与えているかをより深く理解するには、事後分析を行う必要があります。
Atlassian では、事後分析において誰も責めることはありません。つまり、パフォーマンスを改善して前進することに焦点を当てています。
プロセスとニーズをサポートするテクノロジーを選択する
自動化。アラートの優先順位付け。オンコール スケジューリング。KPI トラッキング。効果的にするには、これらの必須プロセスにはそれぞれをサポートするテクノロジーが必要です。テクノロジーを選択する前に、目標、プロセス、チームのニーズを理解しておく必要があります。アラートを自動で整理、重複除外、優先順位付けするには、それらの機能を備えたソリューションが必要です。つまり、Jira Service Management などのソリューションです。
Statuspage でインシデント コミュニケーションを学ぶ
このチュートリアルでは、システム停止時にインシデント テンプレートを使用して効果的にコミュニケーションを取る方法について説明します。さまざまなサービス中断に適応可能です。
このチュートリアルを読むインシデント コミュニケーション テンプレートと例
インシデントに対応する際は、コミュニケーション テンプレートが非常に有用です。Atlassian のチームが使用しているテンプレートと、一般的なインシデント用のさまざまなサンプルをご覧ください。
この記事を読む