ベロシティの高いチームのためのインシデント管理
インシデント管理 KPI と指標の選択方法
継続的なインシデント管理の追跡と改善
現在の常時稼働の世界では、技術インシデントには重大な結果が伴います。
システム ダウンタイムによって企業が被るコストは、収益の損失、従業員の生産性の損失、保守費用などで、平均で 1 時間当たり 30 万ドルに上ります。大規模なシステム停止のコストは、それらをはるかに上回る可能性があります (デルタ航空の場合は、2017 年の IT システム停止後に約 1 億 5 千万ドルの損失が発生しました)。また、決済を実行できない、重要なビデオ会議に参加できない、航空券を購入できないとなれば、顧客はすぐに競合他社に奪われます。
このような多くの危険性に対応するために、チームがインシデント管理 KPI を追跡し、その結果を使用してインシデントを検出、診断、修正して、最終的には防止することが、非常に重要になっています。
幸い、(機械システムやオフライン システムとは異なり) Web やソフトウェアのインシデントでは、チームは通常、理解と改善に役立つ多くのデータを取得できます。
ただし、問題もあります。データが多すぎると、課題が逆にわかりにくくなる可能性があります。
インシデント KPI、指標、分析の価値
KPI (主要業績指標) は、企業が特定の目標を達成しているかどうかを判断するのに役立つ指標です。インシデント管理の場合、これらの指標にはインシデント数、平均解決時間、インシデント間の平均時間などがあります。
インシデント管理のための KPI を追跡することで、プロセスとシステムに関する問題を特定して診断し、チームが取り組むためのベンチマークと現実的な目標を設定して、より大きい問いに取り組む手がかりを得られます。
たとえば、ビジネスの目標はすべてのインシデントを 30 分以内に解決することですが、チームの現在の平均解決時間は 45 分だとします。具体的な指標がなければ、何が問題かを把握することは困難です。アラート システムに時間がかかりすぎていますか? プロセスに問題がありますか? 診断ツールを更新する必要がありますか? それはチームの問題ですか、それとも技術の問題ですか?
次に、指標をいくつか追加します。アラート システムにかかる時間が正確にわかっている場合は、これを問題として識別したり除外したりできます。診断の時間が 50% を超えることがわかった場合は、そのトラブルシューティングに集中できます。チーム B がチーム A、C、D よりも 25% を超える時間がかかっていることがわかった場合は、その理由の掘り下げを開始できます。
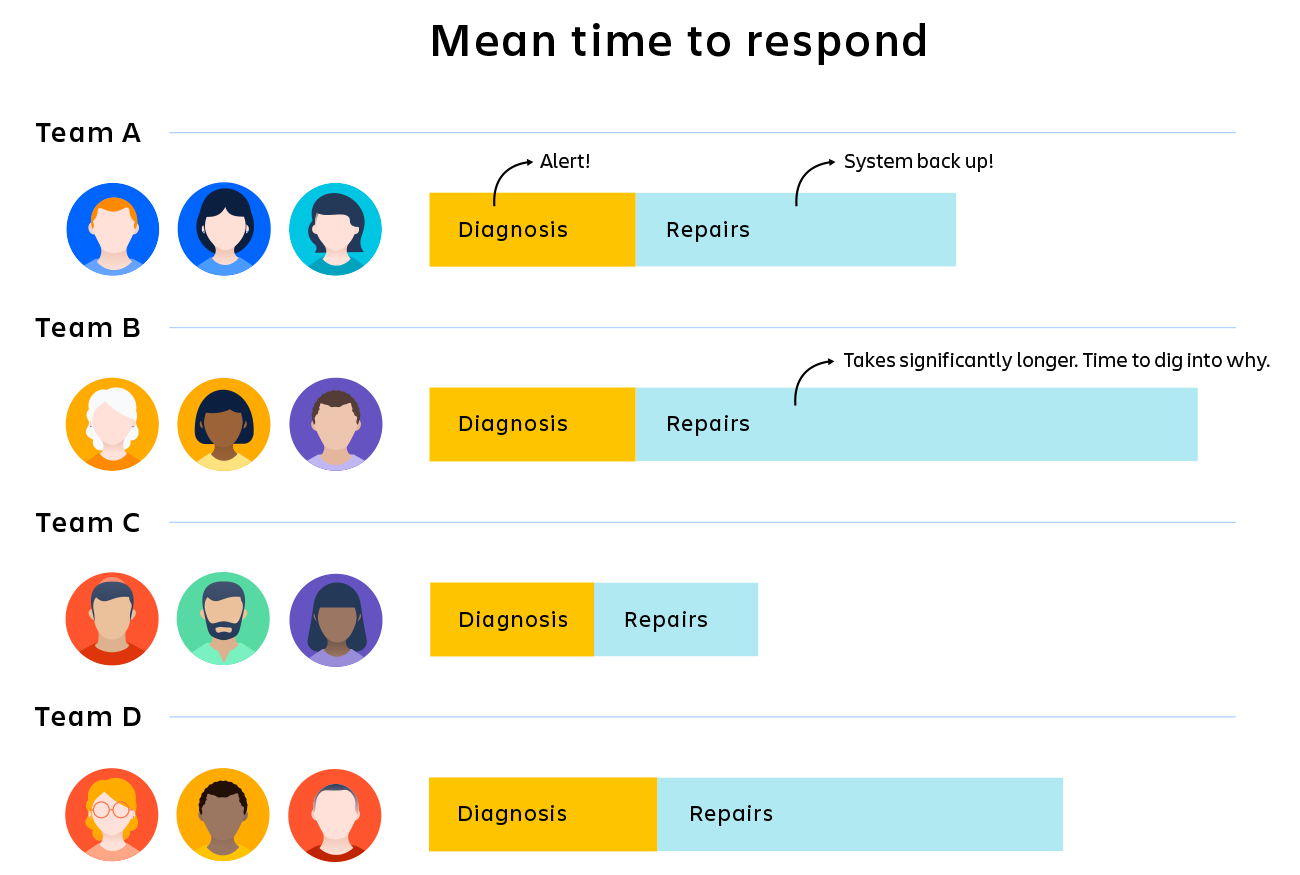
KPI は自動的に問題を解決しませんが、問題がどこにあるかを理解して適切な箇所の掘り下げに集中する上で役立ちます。
一般的なインシデント KPI および指標
アラートの作成
アラート ツールを使用している場合は、特定の期間に生成されるアラートの数を把握することが有効です。Jira Service Management のようなツールを使用すると、アラートを送信したり、レポートやダッシュボードを起動してアラートを追跡したりできます。
顕著だが特徴のない増減、または数値の上昇傾向が見られる期間を観察して、それらの変化が起こっている理由と、チームがそれらに対処する方法について深く掘り下げます。
継続的なインシデントの追跡
インシデントの継続的な追跡は、時間の経過に伴うインシデントの平均数を調べることを意味します。これは、週、月、四半期、年、または日を意味します。
インシデントの発生頻度は時間とともに変化していますか? インシデント数は許容範囲内ですか? それとも許容範囲よりも少ない可能性がありますか? インシデント数の問題を特定したら、その数が上昇傾向または高止まり傾向にある理由と、課題を解決するためにチームは何ができるかについての検討に着手できます。
MTBF
MTBF (平均故障間隔) は技術製品の修理可能な故障間の平均時間です。製品全体の可用性と信頼性を追跡するのに役立ちます。
他の指標と同様に、より大きい問いに取り組む手がかりとなります。MTBF が要求を下回る場合は、システムの障害が頻繁に発生している理由と、将来の障害を軽減または防止する方法を検討します。
MTTA
MTTA (平均確認時間) は、システム アラートからチーム メンバーがインシデントを認識して解決を開始するまでの平均時間です。ここでの価値は、チームの課題に対する対応の速さを把握することにあります。
対応の速さに問題があるとわかれば、再び深く掘り下げられます。なぜ MTTA が高いのですか? チームの負担は過大ですか? 注意が逸れていましたか? アラートの担当者が不明ですか? MTTA は問題を特定して、このような質問は問題の核心にたどり着くのに役立ちます。
MTTD
MTTD (平均検出時間) は、チームが課題を検出するまでにかかる平均時間です。この用語は、サイバーセキュリティにおいて、チームが攻撃や侵害の検出に着目するときによく使用されます。
この指標が大幅に変化した場合や目標を大きく下回る場合は、その理由を考えます。
MTTR
MTTR は、修復、解決、対応、または復旧に要する平均時間です。おそらく、これらの指標の中で最も有用なのは平均解決時間であり、足下の問題の診断と修正に費やされた時間だけでなく、課題の再発の防止に費やされた時間も追跡します。復旧は DevOps Research and Assessment (DORA) が示している主要な DevOps 指標であり、DevOps チームの安定性を測定する鍵となります。
ここでも、この指標は診断的に使用される場合に最適です。解決時間の迅速さと効率は目標に達していますか? 達していない場合は、その解決時間がどの程度目標を下回り、その理由が何かを掘り下げます。
DevOps Research and Assessment (DORA) が示すように、復旧は DevOps チームの安定性を測定する主要な DevOps 指標であり、問題の検出、軽減、解決に要する合計時間です。
オンコール時間
オンコール ローテーションがある場合は、従業員や請負業者が電話に費やす時間を追跡するのが有効です。この指標は、従業員やチームの負担が過剰になっていないかを確認するのに役立ちます。
Jira Service Management を使用すると、これらの数値を一目で確認できる包括的なレポートを作成することができます。
SLA
SLA (サービス レベル アグリーメント) とは、アップタイム、対応の速さ、責任などの測定可能な指標に関する、プロバイダーとクライアント間の契約です。
SLA (アップタイム、平均復旧時間などに関するもの) で行われる約束は、インシデント管理チームがこれらの指標を追跡する必要がある理由の 1 つです。平均対応時間または平均故障間隔などが変化した場合は、迅速な契約の更新や修正の実施が必要です。
SLO
SLO (サービス レベル目標) とは、アップタイムなどの特定の指標に関する SLA 内の合意です。SLO は SLA 自体と同様に、カスタマー サービスに関して企業が契約の遂行を確認するために追跡する重要な指標です。
タイムスタンプ (またはタイムライン)
タイムスタンプは、インシデント発生前中後の特定の時刻に何が起こったかについてのエンコードされた情報です。通常はこの情報は指標とは考えられませんが、インシデント管理の健全性を評価して改善するための戦略を作成する上で重要なデータです。
タイムスタンプは、チームがインシデントのタイムラインを構築して下準備と対応に取り組む上で役立ちます。明確なタイムラインの共有は、インシデント事後分析における最も有用な成果の 1 つです。
稼働時間
アップタイムは、システムが使用可能で機能している時間 (パーセンテージで表されます) です。
オンライン サービスの接続性の向上とシステム自体の複雑さの増加は、通常はアップタイムの 100% 保証などというものは存在しないことを示しています。ほとんどの製品の目標は、長期間中断することなくシステムまたは製品を稼働させることである高可用性です。業界標準では 99.9% のアップタイムは非常に良好、99.99% ならきわめて良好とされます。
この指標に対する成果の追跡は、顧客と約束してそれを履行するために行います。そして他の指標の場合と同様、これは単なる出発点です。アップタイムが 99.99% でなければ、なぜより多くの調査、チームとの会話、プロセス、構造、アクセス、テクノロジーに関する調査が必要になるのかを問うべきです。
インシデント分析に関する注意事項
KPI の短所は、浅いデータに過度に依存しがちであることです。チームがインシデントを解決する速さが十分でないと知っていること自体は修正につながりません。これは、どのように、なぜチームが課題を解決するか、または解決しないかを知る必要があるためです。また、比較している課題が実際に比較可能かを知る必要があります。
KPI からは、チームが困難な課題にどのようにアプローチしているかはわかりません。インシデント間の間隔が長くなるのではなく、短くなっている理由を説明できません。なぜインシデント A にインシデント B の 3 倍の時間がかかったのかはわかりません。
そのためにはインサイトが必要です。そして、データはこれらのインサイトへの出発点になりますが、障害にもなり得ます。指標が改善していなくても、十分適切に機能しているという印象を与える可能性があります。個別のアプローチが求められるまったく異なるインシデントを一括りにしてしまう可能性があります。チームの経験とインシデント自体に内在する複雑性が失われる可能性があります。
「各インシデントは、従来考えられていたよりもはるかに独自性を持っています。同じ長さの 2 つのインシデント間には、事態の把握における驚きと不確定性の水準に大きな差がある場合があります。また、状況の緩和と改善を意図した行動の実行に伴うリスクも大きく異なる場合があります。インシデントは、物理的な寸法が品質の重要な指標となる製造中のウィジェットではありません」
- John Allspaw、Moving Past Shallow Incident Data
KPI をダメ出ししている訳ではありません、不要なものと一緒に大切なものも捨ててはいけないことを伝えたいのです。要は、KPI では不十分だということです。出発点であり診断ツールである KPI は、真の改善へのより複雑な道筋への第一歩です。
Jira Service Management は、レポート機能を備えているため、チームは KPI を追跡し、インシデント管理プラクティスを監視および最適化できます。
Opsgenie を使用したオンコール スケジュールの設定
このチュートリアルでは、オンコール スケジュールの設定、オーバーライド ルールの適用、オンコール通知の設定などの方法を学習します。すべて Opsgenie 内で行います。
このチュートリアルを読むインシデント コミュニケーション テンプレートと例
インシデントに対応する際は、コミュニケーション テンプレートが非常に有用です。Atlassian のチームが使用しているテンプレートと、一般的なインシデント用のさまざまなサンプルをご覧ください。
この記事を読む