ベロシティの高いチームのためのインシデント管理
MTBF、MTTR、MTTA、MTTF
いくつかの最も一般的なインシデント指標の理解
現在の常時稼働の世界では、停止や技術的なインシデントの影響はかつてないほど大きくなっています。納品の遅れ、支払いの遅れ、プロジェクトの遅延など、不具合とダウンタイムは重大な結果をもたらします。
そのため企業では、アップタイム、ダウンタイム、およびチームが課題を解決する時間の短縮と効果に関する指標を定量化して追跡することが重要になります。
業界で最も一般的に追跡される指標には、MTBF (平均故障間隔)、MTTR (復旧、修復、対応、解決までの平均時間)、MTTF (平均故障時間)、MTTA (平均確認時間) があります。これらは、技術チームがインシデントの発生頻度とチームによるそれらのインシデントへの対応の速さに関する理解を促すように設計された一連の指標です。
多くの専門家は、これらの指標はインシデントはどのように解決されるか、何が上手く行って何が上手く行かないのか、課題がどのように、いつ、なぜ悪化または緩和するのか、といった厄介な質問に答えないため、実際にはそれほど有用ではないと主張しています。
一方、MTTR、MTBF、MTTF は、より深く重要な質問に繋がる会話を開始する良い出発点またはベンチマークになり得ます。

重大インシデントにプロが対応する方法
無料のインシデント管理ハンドブックをご覧ください、Atlassian が重大インシデントを管理するために使用するすべてのツールと技術について説明しています。
MTTR に関する免責
MTTR について話すとき、それが単一の意味を持つ単一の指標であると仮定するのは簡単です。しかし実際には、潜在的に 4 つの異なる測定値を表しています。R は、修復、復旧、対応、解決を示します。また 4 つの指標は重複していますが、それぞれに独自の意味とニュアンスがあります。
そのためチームが MTTR の追跡について話している場合は、どの MTTR を意味してどのように定義しているのかを明確にすることをお勧めします。成功と失敗の追跡を開始する前に、チームは何を追跡しているかを厳密に共有して、全員が確実に同じことについて話せるようにします。
MTBF: 平均故障間隔
平均故障間隔はどれくらいですか?
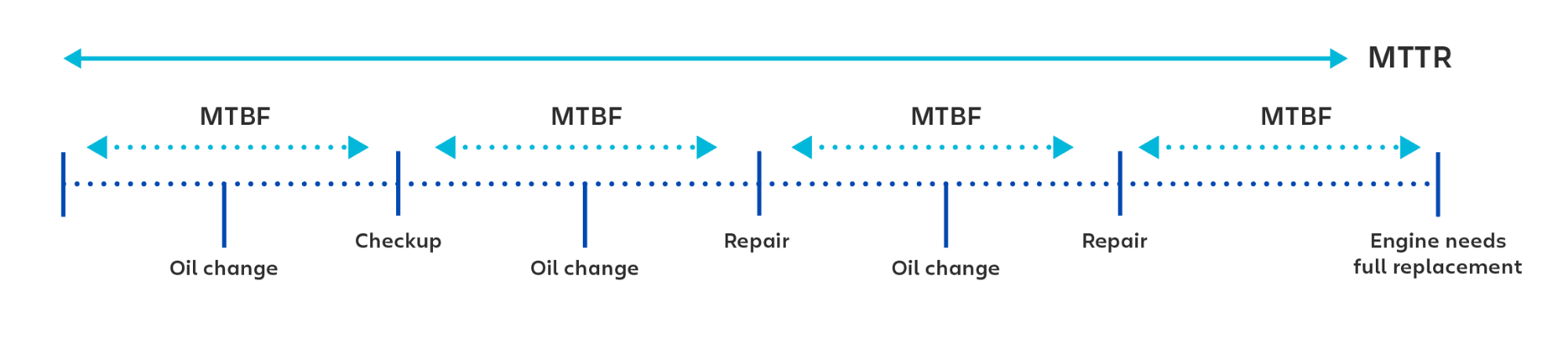
MTBF (平均故障間隔) は技術製品の修理可能な故障間の平均時間であり、製品の可用性と信頼性の両方を追跡する際に使用されます。故障の間隔が長いほど、システムの信頼性が高くなります。
ほとんどの企業は、MTBF を可能な限り高く維持することを目標としています。つまり、課題間の間隔を数十万時間 (あるいは数百万) 時間にしようとしています。
平均故障間隔の計算方法
MTBF は算術平均を使用して計算されます。基本的にこれは、計算したい期間 (6 か月かもしれないし、1 年や 5 年に及ぶかもしれません) からデータを取得して、その期間の総運用時間を故障数で割ることを意味します。
では、24 時間の期間を評価した結果、2 つの別々のインシデントで 2 時間のダウンタイムがあったとします。総アップタイムは 22 時間です。2 で割ると 11 時間なので、MTBF は 11 時間です。
指標は信頼性の追跡に使用されるため、MTBF はスケジュールされた保守中に想定されるダウンタイムを考慮しません。代わりに、想定していない停止と課題に焦点を当てています。
平均故障間隔の開始
MTBF は、システム障害がコストだけでなく、人命にも重大な影響を与える航空業界で誕生しました。この頭字語は誕生以来、さまざまな技術および機械産業に浸透して、特に製造において頻繁に使用されています。
いつどのように平均故障間隔を使用するか
MTBF は、最も信頼性の高い製品を手に入れたり、信頼できる飛行機を飛ばしたり、工場にとって最も安全な製造設備を選択したりしたい購入者にとって便利な指標です。
内部チームの場合は、課題を特定して成功と失敗を追跡する際に役立つ指標です。また、顧客が部品を交換したり、システムをアップグレードしたり、保守のために製品を持ち込んだりする必要があるタイミングについて、情報に基づいて推奨事項を示せます。
MTBF は修復可能なシステムの故障に関する指標です。システムの交換が必要な故障の場合は、通常、MTTF (平均故障時間) という用語を使用します。
たとえば、車のエンジンについて考えてください。予定外のエンジン保守の間隔を計算するときは、MTBF (平均故障間隔) を使用します。フル エンジンの交換間隔を計算するときは、MTTF (平均故障時間) を使用します。
MTTR: 平均修復時間
平均修復時間とは何ですか?
MTTR (平均修復時間) は、(通常は技術的または機械的) システムの修復にかかる平均時間です。これには、修復時間とテスト時間の両方が含まれます。システムが再び完全に機能するまで、この指標の時間のカウントは止まりません。
平均修復時間の計算方法
MTTR を計算するには、任意の期間の修理にかかった時間を合計して、その時間を修復回数で割ります。
では、1 週間にわたる修復を見ているとします。10 回の停止があり、4 時間に及ぶシステムの修復が積極的に行われていました。4 時間は 240 分です。240 を 10 で割ると 24 です。つまり、この場合の平均修復時間は 24 分になります。
平均修復時間の制限
平均修復時間は、システム停止自体と同じ時間であるとは限りません。場合によっては、製品の故障またはシステム停止から数分以内に修復が開始されることもあります。その他の場合は、課題、問題の検出、修復の開始の間にタイム ラグがあります。
この指標は、保守スタッフが課題を修復できる時間を追跡する際に最も役に立ちます。この指標は、システム アラートまたは修復前の遅延に関する問題 (いずれも、インシデント管理プログラムの成功と失敗を評価する際にも重要な要素) を特定するためのものではありません。
いつどのように平均修復時間を使用するか
MTTR は、サポートおよび保守チームが修理を軌道に乗せるために使用する指標です。その目標は修理プロセスとチームの効率を向上させることで、この数をできるだけ低くすることです。
MTTR: 平均復旧時間
平均復旧時間とは何ですか?
MTTR (平均復旧時間または平均修復時間)は、製品の故障またはシステムの故障からの復旧にかかる平均時間です。これには、システムまたは製品に故障が発生した時点から再び完全に動作可能になるまでの、停止の全時間が含まれます。
これは DevOps Research and Assessment (DORA) 調査プログラムが示すように、DevOps チームの安定性を測定するために使用できる主要な DevOps 指標です。
平均復旧時間の計算方法
平均復旧時間は、特定の期間内のすべてのダウンタイムを合計してインシデント数で割ることによって計算されます。そのため、24 時間の間に 2 つの別々のインシデントによってシステムが 30 分間ダウンしたとします。30 を 2 で割ると 15 なので、MTTR は 15 分です。
平均復旧時間の制限
この MTTR は、完全な復旧プロセスの速度の測定値です。目標に達していますか? 競合他社と比較してどうですか?
これは、問題があるかどうかを特定するのに役立つ大まかな指標です。しかし、問題がプロセスのどこにあるかを診断したい場合は (アラート システムの課題ですか? チームによる修正に時間がかかりすぎていますか? 誰かが修正リクエストに対応するまでに時間がかかりすぎていますか?)、さらなるデータが必要です。故障と復旧の間に複数の問題が発生しているためです。
問題はアラート システムにある可能性があります。故障とアラートの間に遅延はありますか? アラートが適切な担当者に届くまでに想定を超える時間がかかっていますか?
診断に問題がある可能性があります。何が問題なのかを迅速に把握できますか? 改善できるプロセスはありますか?
または、修復に問題がある可能性があります。保守チームは可能な限り効果的に動いていますか? 保守チームが時間をかけすぎている場合は、どこでつまずいていますか?
これらの質問に答えるには MTTR よりも深く調べる必要がありますが、平均復旧時間は掘り下げる必要がある復旧プロセスの問題があるかどうかを診断するための出発点になり得ます。
いつどのように平均復旧時間を使用するか
MTTR は、復旧プロセス全体の速度を評価するための優れた指標です。
MTTR: 平均解決時間
平均解決時間とは何ですか?
MTTR (平均解決時間) は、故障を完全に解決するのにかかる平均時間です。これには、故障の検出、問題の診断、課題の修復にかかる時間だけではなく、故障の再発を防止するための時間も含まれます。
この指標は、修正を対応するチームの責任を、長期的なパフォーマンスの改善にまで拡張します。これは、応急処置だけ行う場合とその後の予防も行う場合の違いです。
この MTTR と顧客満足度の間には強い相関関係があるため、しっかり注意を払う必要があります。
平均解決時間の計算方法
この MTTR を計算するには、追跡する期間のすべての解決時間を合計してインシデント数で割ります。
1 回のインシデントで 24 時間にわたってシステムが計 2 時間停止して、チームがシステム停止の再発を防止するための修正を 2 時間かけて実施した場合は、課題の解決に合計で 4 時間を費やしたことになります。つまり、MTTR は 4 時間です。
平均解決時間の追跡に関するメモ
MTTR はほとんどの場合、営業時間を使用して計算されることに注意してください (そのため、1 日の終業時刻に課題から復旧して翌朝の初めに根本的な課題の修正に時間を費やした場合は、オフィスから離れて費やした 16 時間は含まれません)。24 時間勤務しているチームが複数の場所にある、またはオンコールの従業員が時間外で勤務している場合は、この指標の時間の追跡方法を定義することが重要です。
いつどのように平均解決時間を使用するか
MTTR は通常、サービス リクエスト (通常は計画されている) ではなく、計画外インシデントについて話すときに使用します。
MTTR: 平均対応時間
平均対応時間とは何ですか?
MTTR (平均対応時間) は、最初に故障のアラートを受けてから製品またはシステムの故障からの復旧までの平均時間です。これには、アラート システムのタイム ラグは含まれません。
平均対応時間の計算方法
この MTTR を計算するには、アラートから製品またはサービスが再び完全に機能する時点までの対応時間を合計します。次に、インシデント数で割ります。
たとえば、40 営業時間に 4 つのインシデントがあってそのインシデントに合計 1 時間 (アラートから修正まで) を費やした場合、その週の MTTR は 15 分になります。
いつどのように平均対応時間を使用するか
この MTTR は、サイバー セキュリティでシステム攻撃を無化するチームの成功を測定するときによく使用されます。
MTTA: 平均確認時間
平均確認時間とは何ですか?
MTTA (平均確認時間) は、アラートがトリガーされてから課題の解決に取り組むまでの平均時間です。この指標は、チームの対応の速さとアラート システムの有効性を追跡するのに役立ちます。
平均確認時間の計算方法
MTTA を計算するには、アラートから確認までの時間を合計して、インシデント数で割ります。
たとえば、10 件のインシデントがあって 10 件すべてのアラートと確認の間に合計 40 分の時間があった場合は、40 を 10 で割ると平均 4 分になります。
いつどのように平均確認時間を使用するか
MTTA は応答性の追跡に役立ちます。チームがアラート疲労に苦しんでおり、応答に時間がかかりすぎていますか? この指標は課題を指摘する上で役立ちます。
MTTF: 平均故障時間
平均故障時間とは何ですか?
MTTF (平均故障時間) は、技術製品の修復不能な故障間の平均時間です。たとえば、ブランド X の自動車エンジンが完全に故障して交換が必要になるまでの時間が平均 50 万時間であれば、50 万がエンジンの MTTF になります。
この計算は、システムが通常どれくらい持続するかを理解し、システムの新しいバージョンの性能が古いバージョンを上回っているかどうかを判断し、想定されるライフタイムとシステムのチェックアップをスケジュールする時期に関する情報を顧客に提供するために使用されます。
平均故障時間の計算方法
平均故障時間は算術平均なので、評価する製品の総アップタイムを合計してデバイス数で割って計算します。
例として、電球の MTTF を計算します。ブランド Y の電球は切れるまでに平均してどれくらいかかりますか? さらに、テストする 4 つの電球のサンプルがあるとします (統計的に有意なデータが必要な場合は 4 つどころではないサンプルが必要ですが、計算を単純にするためにサンプル数は少なくしてあります)。
電球 A は 20 時間、電球 B は 18 時間、電球 C は 21 時間、電球 D は 21 時間もちます。合計 80 時間です。4 で割ると、MTTF は 20 時間です。

平均故障時間の問題
電球のような例では、MTTF はとても意味のある指標になります。最後の電球が故障するまで電球を使用して、その情報を使用して電球の耐久性に関する結論を導けます。
しかし、それほど早く故障しないものを測定する場合はどうなるでしょうか? 何年も使用されることを想定しているのでしょうか? このような場合、MTTF は頻繁に使用されますが、最適な指標ではありません。ほとんどの場合、故障するまで製品を使用するのではなく、設定された期間使用して故障の回数を測定するためです。
たとえば、ブランド Z のタブレットで MTTF 統計を取得しようとしているとします。タブレットは、問題がなければ何年も使用できると想定されています。しかしブランド Z は、データの収集に 6 か月しかかけられないかもしれません。そのため、6 か月で 100 台のタブレットをテストします。1 台のタブレットがちょうど 6 か月で故障するとします。
総稼働時間 (6 か月に 100 台を掛ける) は 600 か月となります。1 台のタブレットだけが故障したので総稼働時間を 1 で割り、MTTR は 600 か月になります。つまり、50 年です。
ブランド Z のタブレットは、平均 50 年使用できるのでしょうか? その可能性はかなり低いです。そのため、このようなケースでは、この指標は有効ではありません。
いつどのように平均故障時間を使用するか
MTTF は、寿命が短い製品やシステム (電球など) の平均寿命を評価する場合に有効です。また、製品全体の故障を評価する場合のみを対象としています。修理が必要なインシデント間の時間を計算する場合は、MTBF (平均故障間隔) が選択されるようになります。
MTBF、MTTR、MTTF、MTTA の比較
では、インシデント管理の追跡と改善に関しては、どの測定が優れているのでしょうか?
答えはすべてです。
それらは同じ意味で使用されることがありますが、各指標は異なるインサイトを提供します。これらを組み合わせて使用すると、インシデント管理でチームがどれくらい成功しているか、チームがどこを改善できるかについて、より完全なストーリーを伝えられます。
平均復旧時間は、システムが元の状態に戻って稼働できるまでの時間を示します。
平均対応時間も参照すると、復旧時間のうちどれくらいがチームに属しているか、アラート システムはどれくらいかを把握できます。
さらに平均修復時間も参照すると、チームが修復と診断に費やす時間が見え始めます。
平均解決時間を組み合わせに追加すると、実際のダウンタイムを超えて課題の修正と解決の全体像が掴めてきます。
平均故障間隔も参照すると、さらに広く把握できて、チームによる将来の課題の防止または削減の成功度が見えてきます。
そして平均故障時間も参照して、製品またはシステムのライフサイクル全体を理解できます。
Jira Service Management はレポート機能を提供しているため、チームは KPI を追跡し、インシデント管理業務を監視して最適化できます。
関連する製品
アラートを統合し、適切な人に適切なタイミングで通知します。
Statuspage でインシデント コミュニケーションを学ぶ
このチュートリアルでは、システム停止時にインシデント テンプレートを使用して効果的にコミュニケーションを取る方法について説明します。さまざまなサービス中断に適応可能です。
このチュートリアルを読むインシデント コミュニケーション テンプレートと例
インシデントに対応する際は、コミュニケーション テンプレートが非常に有用です。Atlassian のチームが使用しているテンプレートと、一般的なインシデント用のさまざまなサンプルをご覧ください。
この記事を読む