Gestión de incidentes para equipos de alta velocidad
MTBF, MTTR, MTTA y MTTF
Comprensión de algunas de las métricas sobre incidentes más habituales
En el mundo actual, siempre activo, las interrupciones y los incidentes técnicos son más importantes que nunca. Los fallos y el tiempo de inactividad tienen consecuencias reales. Incumplimiento de plazos. Demoras en los pagos. Retrasos en los proyectos.
Por eso es importante que las empresas cuantifiquen y hagan un seguimiento de las métricas en torno al tiempo de actividad, el tiempo de inactividad y la rapidez y eficacia con la que los equipos resuelven las incidencias.
Algunas de las métricas de seguimiento más habituales del sector son el MTBF (tiempo medio entre fallos), el MTTR (tiempo medio de recuperación, reparación, respuesta o resolución), el MTTF (tiempo medio sin averías) y el MTTA (tiempo medio de confirmación de recepción); una serie de métricas diseñadas para ayudar a los equipos técnicos a comprender la frecuencia con la que ocurren los incidentes y la rapidez con la que el equipo se recupera de esos incidentes.
Muchos expertos sostienen que estas métricas no son realmente útiles por sí solas porque no plantean las preguntas más complicadas sobre cómo se resuelven los incidentes, qué funciona y qué no, y cómo, cuándo y por qué se escalan o desescalan las incidencias.
Por otro lado, el MTTR, el MTBF y el MTTF pueden ser una buena línea o punto de referencia para iniciar conversaciones que conducen a esas preguntas más profundas e importantes.

Cómo responden los profesionales a los incidentes graves
Obtén nuestro manual gratuito de gestión de incidentes. Conoce todas las herramientas y técnicas que Atlassian utiliza para gestionar incidentes importantes.
Aviso sobre MTTR
Cuando hablamos del MTTR, es fácil asumir que es una métrica única con un solo significado. Pero la verdad es que representa potencialmente cuatro mediciones diferentes. La R puede significar reparación, recuperación, respuesta o resolución, y aunque las cuatro métricas se superponen, cada una tiene su propio significado y matiz.
Por lo tanto, si tu equipo habla de hacer un seguimiento del MTTR, es una buena idea aclarar a qué MTTR se hace referencia y cómo se está definiendo. Antes de empezar a hacer un seguimiento de los éxitos y los fracasos, tu equipo tiene que estar de acuerdo con lo que estáis siguiendo exactamente y asegurarse de que todo el mundo sabe que están hablando de lo mismo.
MTBF: tiempo medio entre fallos
¿Qué es el tiempo medio entre fallos?
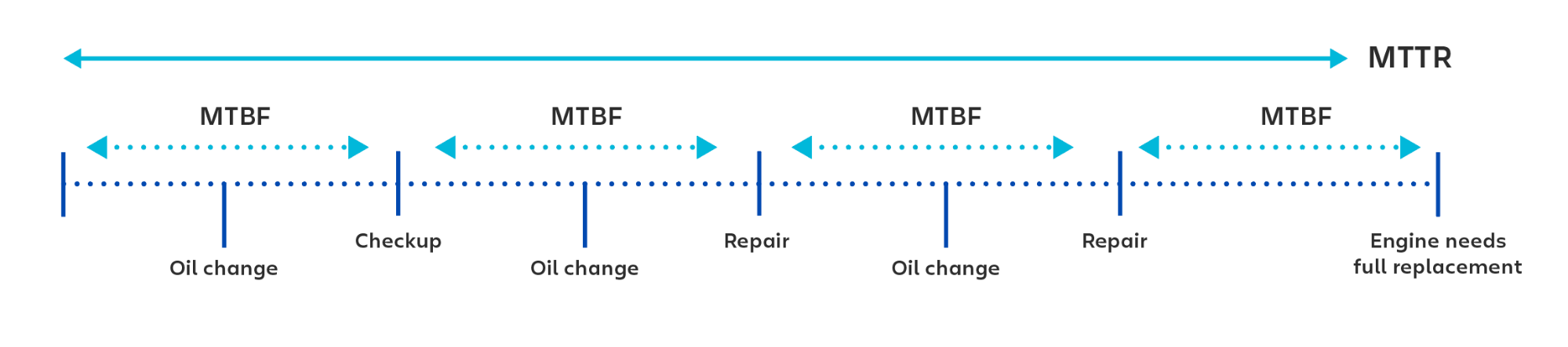
El MTBF (tiempo medio entre fallos) es la media de tiempo entre fallos reparables de un producto tecnológico. La métrica se utiliza para controlar tanto la disponibilidad como la fiabilidad de un producto. Cuanto mayor sea el tiempo entre fallos, más fiable será el sistema.
El objetivo de la mayoría de las empresas es mantener el MTBF lo más alto posible, es decir, que transcurran cientos de miles de horas (o incluso millones) entre las incidencias.
Cómo se calcula el tiempo medio entre fallos
El MTBF se calcula utilizando una media aritmética. Básicamente, esto significa tomar los datos del período que se quiere calcular (quizás seis meses, tal vez un año o puede que cinco años) y dividir el tiempo de funcionamiento total de ese período por el número de fallos.
Así que, digamos que estamos evaluando un período de 24 horas y que hubo 2 horas de tiempo de inactividad en 2 incidentes distintos. Nuestro tiempo de actividad total es de 22 horas. Dividido entre dos incidentes, son 11 horas. Así que nuestro MTBF es de 11 horas.
Dado que la métrica se utiliza para hacer un seguimiento de la fiabilidad, el MTBF no tiene en cuenta el tiempo de inactividad previsto durante el mantenimiento programado. En cambio, se centra en las interrupciones y los problemas inesperados.
Los orígenes de la métrica de tiempo medio entre fallos
La sigla MTBF procede del sector de la aviación, donde los fallos de los sistemas tienen consecuencias especialmente importantes no solo en términos de costes, sino también de vidas humanas. A partir de ahí, el uso de esta sigla se ha extendido a toda una serie de sectores técnicos y mecánicos y, especialmente, al ámbito de la fabricación.
Cómo y cuándo usar la métrica de tiempo medio entre fallos
El MTBF es útil para los compradores que quieren asegurarse de obtener el producto más infalible, pilotar el avión más fiable o elegir el equipo de fabricación más seguro para su instalación.
Para los equipos internos, es una métrica que ayuda a identificar las incidencias y a hacer un seguimiento de los éxitos y los fracasos. También puede ayudar a las empresas a elaborar recomendaciones informadas sobre cuándo deben los clientes sustituir una pieza, actualizar un sistema o llevar un producto para su mantenimiento.
El MTBF es una métrica sobre los fallos en los sistemas reparables. Para los fallos que requieren la sustitución del sistema, se suele utilizar el término MTTF (tiempo medio sin averías).
Por ejemplo, piensa en el motor de un coche. Para calcular el tiempo entre mantenimientos no programados del motor, se utiliza el MTBF (tiempo medio entre fallos). Cuando se calcula el tiempo transcurrido entre la sustitución del motor completo, se utiliza el MTTF (tiempo medio sin averías).
MTTR: tiempo medio de reparación
¿Qué es el tiempo medio de reparación?
El MTTR (tiempo medio de reparación) es la media de tiempo que se tarda en reparar un sistema (normalmente una cuestión técnica o mecánica). Incluye tanto el tiempo de reparación como el tiempo de prueba. El reloj no se detiene en esta métrica hasta que el sistema vuelve a funcionar por completo.
Cómo se calcula el tiempo medio de reparación
Se puede calcular el MTTR sumando el tiempo total dedicado a las reparaciones durante un período determinado y dividiendo ese tiempo por el número de reparaciones.
Supongamos que estamos viendo las reparaciones en el transcurso de una semana. En ese tiempo, hubo 10 interrupciones y los sistemas se repararon activamente durante 4 horas. Cuatro horas son 240 minutos. Si dividimos 240 entre 10, el resultado es 24. Lo que significa que el tiempo medio de reparación en este caso sería de 24 minutos.
Las limitaciones del tiempo medio de reparación
El tiempo medio de reparación no siempre es el mismo que el de la propia interrupción del servicio del sistema. En algunos casos, las reparaciones se inician a los pocos minutos del fallo del producto o de la interrupción del servicio del sistema. En otros casos, hay un intervalo de tiempo entre la incidencia, el momento en que esta se detecta y el momento en que comienzan las reparaciones.
Esta métrica es más útil cuando se hace un seguimiento de la rapidez con la que el personal de mantenimiento es capaz de reparar una incidencia. No está pensada para identificar problemas con las alertas de tu sistema o los retrasos previos a la reparación; ambos son factores importantes a la hora de evaluar los éxitos y fracasos de tus programas de gestión de incidentes.
Cómo y cuándo usar la métrica de tiempo medio de reparación
El MTTR es una métrica que los equipos de soporte y mantenimiento utilizan para hacer un seguimiento de las reparaciones. El objetivo es conseguir que esta cifra sea lo más baja posible aumentando la eficiencia de los equipos y procesos de reparación.
MTTR: tiempo medio de recuperación
¿Qué es el tiempo medio de recuperación?
El MTTR (tiempo medio de recuperación o tiempo medio de restauración) es la media de tiempo que se tarda en recuperarse de un fallo de un producto o sistema. Esto incluye todo el tiempo de la interrupción, desde el momento en que el sistema o el producto falla hasta que vuelve a funcionar por completo.
Es una métrica clave de DevOps que puede usarse para medir la estabilidad de un equipo de DevOps, como señala el programa DORA (DevOps Research and Assessment).
Cómo se calcula el tiempo medio de recuperación
El tiempo medio de recuperación se calcula sumando todo el tiempo de inactividad en un período concreto y dividiéndolo por el número de incidentes. Así pues, supongamos que nuestros sistemas estuvieron fuera de servicio durante 30 minutos en 2 incidentes distintos, en un período de 24 horas. Si dividimos 30 entre 2, el resultado es 15, es decir, que nuestro MTTR es de 15 minutos.
Las limitaciones del tiempo medio de recuperación
Este MTTR es una medición de la velocidad de tu proceso de recuperación total. ¿Es tan rápido como quieres que sea? ¿Cómo se compara con los procesos de tus competidores?
Esta es una métrica de alto nivel que te ayuda a identificar si tienes algún problema. Sin embargo, si quieres diagnosticar dónde está el problema dentro de tu proceso (¿se trata de un problema con tu sistema de alertas?, ¿el equipo tarda demasiado en hacer las correcciones?, ¿se tarda demasiado en responder a una solicitud de corrección?), necesitarás más datos. Esto se debe a que hay más de una cosa que ocurre entre el fallo y la recuperación.
El problema podría estar en tu sistema de alertas. ¿Hay algún retraso entre un fallo y una alerta? ¿Tardan las alertas más de lo debido en llegar a la persona adecuada?
El problema podría estar en los diagnósticos. ¿Eres capaz de averiguar rápidamente cuál es el problema? ¿Hay procesos que puedan mejorarse?
O bien el problema podría estar en las reparaciones. ¿Son tus equipos de mantenimiento tan eficaces como podrían ser? Si están ocupando la mayor parte del tiempo, ¿qué es lo que les hace entretenerse?
Para responder a estas preguntas, tendrás que mirar más allá del MTTR; sin embargo, el tiempo medio de recuperación puede proporcionar un punto de partida para diagnosticar si hay algún problema con el proceso de recuperación que requiera que se profundice en él.
Cómo y cuándo usar la métrica de tiempo medio de recuperación
El MTTR es una buena métrica para evaluar la velocidad del proceso general de recuperación.
MTTR: tiempo medio de resolución
¿Qué es el tiempo medio de resolución?
El MTTR (tiempo medio de resolución) es la media de tiempo que se tarda en resolver completamente un fallo. Esto incluye no solo el tiempo dedicado a detectar el fallo, diagnosticar el problema y reparar la incidencia, sino también el tiempo dedicado a garantizar que el fallo no vuelva a producirse.
Esta métrica amplía la responsabilidad del equipo que gestiona la corrección para mejorar el rendimiento a largo plazo. Es la diferencia entre apagar un fuego y apagar un fuego y, luego, cubrir tu casa con material ignífugo.
Existe una fuerte correlación entre este MTTR y la satisfacción del cliente, por lo que es algo a lo que hay que prestar atención.
Cómo se calcula el tiempo medio de resolución
Para calcular este MTTR, suma el tiempo de resolución total durante el período en el que quieres hacer el seguimiento y divídelo por el número de incidentes.
Así, si en un período de 24 horas tus sistemas estuvieron fuera de servicio durante un total de 2 horas con un solo incidente y los equipos dedicaron otras 2 horas a realizar correcciones para garantizar que la interrupción en el sistema no vuelva a repetirse, son un total de 4 horas las que se dedicaron a resolver la incidencia. Lo que significa que tu MTTR es de 4 horas.
Nota sobre el seguimiento del tiempo medio de resolución
Ten en cuenta que el MTTR se calcula con mayor frecuencia utilizando las horas de trabajo (así pues, si un día te recuperas de una incidencia a la hora de cierre y dedicas tiempo a solucionar la incidencia a primera hora de la mañana siguiente, el MTTR no incluiría las 16 horas que pasaste fuera de la oficina). Si tienes equipos en varias ubicaciones que trabajan las 24 horas del día o si tienes empleados de guardia que trabajan fuera de horario, es importante que definas cómo harás el seguimiento del tiempo para esta métrica.
Cómo y cuándo usar la métrica de tiempo medio de resolución
Normalmente, el MTTR se utiliza cuando se habla de incidentes no planificados, no de solicitudes de servicio (que sí se suelen planificar).
MTTR: tiempo medio de respuesta
¿Qué es el tiempo medio de respuesta?
El MTTR (tiempo medio de respuesta) es la media de tiempo que se tarda en recuperarse de un fallo de un producto o sistema desde el momento en que se avisa por primera vez de dicho fallo. Esto no incluye ningún tiempo de retraso en tu sistema de alertas.
Cómo se calcula el tiempo medio de respuesta
Para calcular este MTTR, suma el tiempo de respuesta total desde la alerta hasta el momento en que el producto o servicio vuelva a funcionar por completo. Luego, divídelo por el número de incidentes.
Por ejemplo: si tuviste cuatro incidentes en una semana laboral de 40 horas y les dedicaste una hora en total (desde la alerta hasta la corrección), el MTTR para esa semana sería de 15 minutos.
Cómo y cuándo utilizar la métrica de tiempo medio de respuesta
Este MTTR suele emplearse en ciberseguridad para medir el éxito de un equipo en la neutralización de ataques a un sistema.
MTTA: tiempo medio de confirmación de recepción
¿Qué es el tiempo medio de confirmación de recepción?
El MTTA (tiempo medio de confirmación de recepción) es la media de tiempo que transcurre desde que se activa una alerta hasta que se empieza a trabajar en la incidencia. Esta métrica es útil para hacer un seguimiento de la capacidad de respuesta del equipo y de la eficacia de tu sistema de alertas.
Cómo se calcula el tiempo medio de confirmación de recepción
Para calcular el MTTA, suma el tiempo transcurrido entre la alerta y la confirmación de recepción y, después, divídelo por el número de incidentes.
Por ejemplo: si se produjeron 10 incidentes y transcurrió un total de 40 minutos entre la alerta y la confirmación de recepción de los 10, divide 40 entre 10 y obtendrás una media de 4 minutos.
Cómo y cuándo usar la métrica de tiempo medio de confirmación de recepción
El MTTA es útil para hacer un seguimiento de la capacidad de respuesta. ¿Está tu equipo fatigado por las alertas y tarda demasiado en responder? Esta métrica te ayudará a detectar el problema.
MTTF: tiempo medio sin averías
¿Qué es el tiempo medio sin averías?
El MTTF (tiempo medio sin averías) es la media de tiempo que transcurre sin averías no reparables de un producto tecnológico. Por ejemplo, si los motores de automóviles de la marca X tienen una media de 500 000 horas antes de que se averíen por completo y se tengan que sustituir, el MTTF de los motores sería de 500 000.
El cálculo se utiliza para conocer la duración típica de un sistema, determinar si una nueva versión de un sistema supera a la anterior y ofrecer a los clientes información sobre la vida útil prevista y cuándo deben programar las revisiones de sus sistemas.
Cómo se calcula el tiempo medio sin averías
El tiempo medio sin averías es una media aritmética, por lo que se calcula sumando el tiempo de funcionamiento total de los productos que se están evaluando y dividiendo esa cifra por el número de dispositivos.
Por ejemplo: supongamos que quieres calcular el MTTF de las bombillas. ¿Cuánto tiempo duran las bombillas de la marca Y en fundirse? Digamos, además, que tienes una muestra de cuatro bombillas para probar (si quieres datos estadísticamente significativos, necesitarás mucho más que eso, pero para un cálculo simple, no nos vamos a complicar).
La bombilla A dura 20 horas, la bombilla B dura 18 horas, la bombilla C dura 21 horas y la bombilla D dura 21 horas. Eso suma un total de 80 horas de duración de las bombillas. Si dividimos esa cantidad entre 4, el MTTF es de 20 horas.

El problema del tiempo medio sin averías
Con un ejemplo como el de las bombillas, el MTTF es una métrica que tiene mucho sentido. Podemos hacer funcionar las bombillas hasta que falle la última y utilizar esa información para sacar conclusiones sobre su resistencia.
Pero ¿qué ocurre cuando medimos cosas que no fallan tan rápido? ¿Cosas que duran años y años? En esos casos, aunque se suele utilizar el MTTF, esta no es una métrica tan buena, porque en lugar de hacer funcionar un producto hasta que falla, la mayoría de las veces se hace funcionar un producto durante un tiempo definido y se mide cuántos fallan.
Por ejemplo: supongamos que queremos obtener estadísticas de MTTF de las tablets de la marca Z. Está previsto que, con suerte, estas tablets duren muchos años, pero cabe la posibilidad de que la marca Z solo tenga seis meses para recopilar datos. Así que decide probar 100 tablets durante seis meses. Pongamos que una tablet falla exactamente a los seis meses.
Así pues, si multiplicamos el tiempo de funcionamiento total (6 meses) por las 100 tablets probadas, obtenemos 600 meses. Como solo falló una tablet, dividimos la cifra obtenida por 1 y el MTTR sería de 600 meses, es decir, 50 años.
¿Va a durar cada tablet de la marca Z una media de 50 años? Es bastante improbable. Y por eso la métrica se rompe en casos como este.
Cómo y cuándo usar la métrica de tiempo medio sin averías
El MTTF funciona bien cuando hay que evaluar la duración media de productos y sistemas con una vida útil corta (por ejemplo, las bombillas). También está pensado solo para casos en los que se evalúa el fallo completo del producto. Si hay que calcular el tiempo que transcurre entre incidentes que requieren reparación, entonces la métrica ideal es MTBF, es decir, el tiempo medio entre fallos.
MTBF frente a MTTR, MTTF y MTTA
Entonces, ¿qué medición es mejor cuando se trata de hacer un seguimiento y mejorar la gestión de incidentes?
La respuesta es todas ellas.
Aunque a veces se utilizan indistintamente, cada métrica proporciona una visión diferente. Cuando se utilizan juntas, pueden contar una historia más completa sobre el éxito de tu equipo con la gestión de incidentes y sobre los aspectos en los que puede mejorar.
El tiempo medio de recuperación te indica la rapidez con la que puedes hacer que tus sistemas se recuperen y funcionen de nuevo.
Añade el tiempo medio de respuesta y tendrás una idea de qué parte del tiempo de recuperación corresponde al equipo y qué parte a tu sistema de alertas.
Añade también el tiempo medio de reparación y empezarás a ver cuánto tiempo dedica el equipo a las reparaciones y cuánto a los diagnósticos.
Añade al combinado el tiempo medio de resolución y podrás ir entendiendo el alcance total de la corrección y la resolución de incidencias más allá del tiempo de inactividad real que causan.
Si añades el tiempo medio entre fallos, la imagen se amplía aún más, mostrando el éxito de tu equipo en la prevención o la reducción de futuras incidencias.
Y, seguidamente, añade el tiempo medio sin averías para comprender el ciclo de vida completo de un producto o sistema.
Jira Service Management ofrece funciones de generación de informes para que tu equipo pueda realizar un seguimiento de los KPI y supervisar y optimizar tu práctica de gestión de incidentes.
Productos discutidos
Centraliza las alertas y notifica a las personas pertinentes en el momento adecuado.
Descubre la comunicación de incidentes con Statuspage
En este tutorial, te mostraremos cómo utilizar plantillas de incidentes para comunicarte eficazmente durante las interrupciones. Puedes aplicarlo a muchos tipos de interrupciones del servicio.
Leer el tutorialPlantillas y ejemplos de comunicación de incidentes
A la hora de responder ante un incidente, las plantillas de comunicación tienen un valor incalculable. Hazte con las plantillas que utilizan nuestros equipos, así como con otros ejemplos para los incidentes comunes.
Leer el artículo