Zarządzanie incydentami dla dynamicznych zespołów
MTBF, MTTR, MTTA i MTTF
Omówienie kilku najczęściej spotykanych wskaźników dotyczących incydentów
Awarie i incydenty techniczne nigdy dotąd nie odgrywały tak wielkiej roli, jak we współczesnym świecie ciągłej dostępności. Usterki i przestoje pociągają za sobą realne konsekwencje. Niedotrzymane terminy. Zaległości w płatnościach. Opóźnienia projektów.
Dlatego ważne jest, aby firmy mierzyły i śledziły wskaźniki dotyczące czasu działania, przestojów oraz szybkości i skuteczności rozwiązywania problemów przez zespoły.
Do najczęściej monitorowanych wskaźników w branży należą: MTBF (średni czas bezawaryjnej pracy), MTTR (średni czas odzyskiwania, naprawy, reakcji lub rozwiązywania), MTTF (średni czas do wystąpienia awarii) oraz MTTA średni czas potwierdzenia). Ten zbiór wskaźników został zaprojektowany, aby pomóc zespołom technicznym ustalić częstotliwość występowania incydentów i szybkość przywracania funkcjonalności po tych incydentach.
Wielu ekspertów twierdzi, że te wskaźniki same w sobie nie są zbyt przydatne, ponieważ nie uwzględniają bardziej złożonych kwestii, takich jak sposoby rozwiązywania incydentów, działające i niedziałające rozwiązania oraz sposób, czas i powód eskalowania lub deeskalowania zgłoszeń.
Z drugiej strony wskaźniki MTTR, MTBF i MTTF mogą być dobrym punktem wyjścia lub poziomem odniesienia w dyskusjach prowadzających do tych dalszych, ważnych pytań.

Jak profesjonaliści reagują na poważne incydenty?
Pobierz nasz bezpłatny podręcznik zarządzania incydentami. Poznaj wszystkie narzędzia i techniki używane przez Atlassian do zarządzania poważnymi incydentami.
Zastrzeżenie dotyczące wskaźnika MTTR
Mówiąc o MTTR, łatwo założyć, że chodzi o pojedynczy wskaźnik, który ma jedno znaczenie. Prawda jest jednak taka, że wskaźnik ten reprezentuje cztery różne pomiary. R w skrócie MTTR może odnosić się do angielskich słów repair (naprawa), recovery (odzyskiwanie), respond (reakcja) i resolve (rozwiązanie). Choć te cztery wskaźniki mają pewne obszary wspólne, każdy z nich ma inne znaczenie i wyróżniające go niuanse.
Jeśli więc Twój zespół mówi o śledzeniu wskaźnika MTTR, warto doprecyzować, który konkretnie wskaźnik ma na myśli i jak go definiuje. Zanim przystąpisz do monitorowania sukcesów i porażek, Twój zespół musi wiedzieć, co dokładnie będziecie śledzić, aby mieć pewność, że wszyscy mówicie o tym samym.
MTBF: średni czas bezawaryjnej pracy
Czym jest średni czas bezawaryjnej pracy?
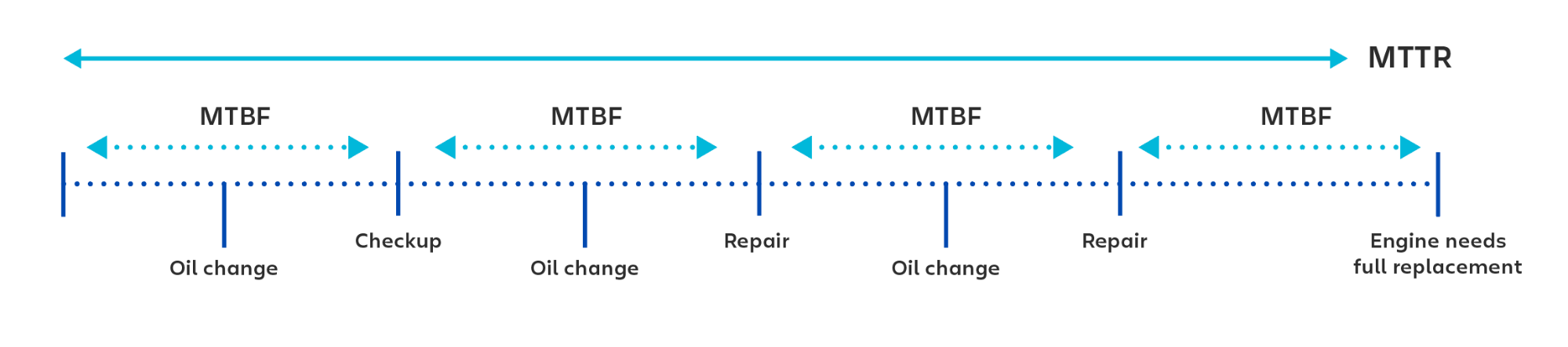
MTBF (średni czas bezawaryjnej pracy) to średni czas między awariami produktu technologicznego, które można naprawić. Ten wskaźnik umożliwia monitorowanie zarówno dostępności, jak i niezawodności produktu. Im dłuższy czas bezawaryjnej pracy, tym bardziej niezawodny jest system.
Celem większości firm jest utrzymanie wskaźnika MTBF na jak najwyższym poziomie, co oznacza setki tysięcy (lub nawet miliony) godzin pomiędzy kolejnymi problemami.
Jak obliczyć średni czas bezawaryjnej pracy?
MTBF oblicza się jako średnią arytmetyczną. Zasadniczo oznacza to zsumowanie danych z odcinka czasu, dla którego chcemy wykonać obliczenie (np. sześciu miesięcy, roku lub pięciu lat) i podzielenie łącznego czasu bezawaryjnej pracy przez liczbę awarii.
Załóżmy, że poddajemy ocenie okres 24-godzinny, w trakcie którego doszło do dwóch odrębnych incydentów, które łącznie spowodowały dwugodzinny przestój. Nasz całkowity czas dostępności wynosi 22 godziny. Po podzieleniu przez dwa uzyskamy wynik 11 godzin. Zatem nasz wskaźnik MTBF wynosi 11 godzin.
Wskaźnik MTBF służy do monitorowania niezawodności, dlatego nie uwzględnia zaplanowanych przerw technicznych. Dotyczy on wyłącznie nieoczekiwanych awarii i problemów.
Pochodzenie wskaźnika średniego czasu bezawaryjnej pracy
Wskaźnik MTBF przywędrował do nas z branży lotniczej, gdzie awarie systemu mają szczególnie poważne konsekwencje nie tylko pod względem kosztów, ale także życia ludzkiego. Od tego czasu ten skrótowiec znalazł swoje miejsce w różnych branżach technicznych i mechanicznych, a szczególnie często stosuje się go w produkcji.
Jak i kiedy korzystać ze wskaźnika średniego czasu bezawaryjnej pracy?
MTBF jest przydatnym wskaźnikiem dla kupujących, którzy chcą mieć pewność, że otrzymają najbardziej niezawodny produkt, latają najbardziej niezawodnym samolotem lub wybierają najbezpieczniejszy sprzęt produkcyjny dla swojego zakładu.
Dla zespołów wewnętrznych jest to wskaźnik, która pomaga zidentyfikować problemy i monitorować sukcesy oraz porażki. Może również pomóc firmom w opracowaniu przemyślanych zaleceń dotyczących tego, kiedy klienci powinni wymienić część, uaktualnić system lub zlecić przeprowadzenie konserwacji produktu.
MTBF jest wskaźnikiem awaryjności w systemach podlegających naprawie. W przypadku awarii wymagających wymiany systemu zazwyczaj stosuje się wskaźnik nazywany średnim czasem do wystąpienia awarii (MTTF).
Dobrym przykładem jest silnik samochodowy. Przy obliczaniu czasu między niezaplanowanymi naprawami silnika można posłużyć się średnim czasem bezawaryjnej pracy (MTBF). Z kolei przy obliczaniu czasu między wymianami całego silnika należy zastosować średni czas do wystąpienia awarii (MTTF).
MTTR: średni czas naprawy
Czym jest średni czas naprawy?
MTTR (średni czas naprawy) to średni czas potrzebny na naprawę systemu (zwykle technicznego lub mechanicznego). Obejmuje to zarówno czas naprawy, jak i czas testowania. Czas liczony jest do momentu przywrócenia pełnej funkcjonalności systemu.
Jak obliczyć średni czas naprawy?
Aby obliczyć wskaźnik MTTR, należy zsumować całkowity czas spędzony na naprawach w danym okresie, a następnie podzielić ten czas przez liczbę napraw.
Załóżmy, że przyglądamy się naprawom dokonanym w ciągu tygodnia. W tym czasie doszło do 10 awarii, a systemy były naprawiane przez łącznie cztery godziny. Cztery godziny to 240 minut. 240 podzielone na 10 to 24. Oznacza to, że średni czas naprawy w tym przypadku wyniósłby 24 minuty.
Ograniczenia wskaźnika średniego czasu naprawy
Średni czas naprawy nie zawsze pokrywa się z czasem samej awarii. W niektórych przypadkach naprawy rozpoczynają się w ciągu kilku minut od wystąpienia awarii produktu lub systemu. W innych przypadkach występuje opóźnienie między wykryciem problemu, a przystąpieniem do naprawy.
Ten wskaźnik przydaje się najbardziej do śledzenia, jak szybko personel serwisowy jest w stanie naprawić problem. Jego celem nie jest wykrycie problemów z alertami systemowymi czy opóźnieniami poprzedzającymi rozpoczęcie naprawy — choć to również są ważne czynniki przy ocenie skuteczności programów zarządzania incydentami.
Jak i kiedy korzystać ze wskaźnika średniego czasu naprawy?
MTTR jest wskaźnikiem, który pozwala zespołom wsparcia i konserwacyjnym dbać o właściwy przebieg napraw. Celem jest utrzymanie wartości tego wskaźnika na jak najniższym poziomie poprzez zwiększenie wydajności procesów naprawczych i zespołów.
MTTR: średni czas odzyskiwania
Czym jest średni czas odzyskiwania?
MTTR (średni czas odzyskiwania lub przywracania) to średni czas potrzebny na przywrócenie działania produktu lub systemu po awarii. Obejmuje on całkowity czas trwania awarii — od momentu wystąpienia awarii systemu lub produktu do momentu, w którym odzyska on pełną sprawność.
Jak wskazuje program badań DevOps Research and Assessment (DORA), jest to kluczowy wskaźnik DevOps pozwalający mierzyć stabilność zespołu DevOps.
Jak obliczyć średni czas odzyskiwania?
Średni czas odzyskiwania oblicza się przez zsumowanie wszystkich przestojów w określonym okresie i podzielenie otrzymanej wartości przez liczbę incydentów. Załóżmy, że w trakcie dwóch odrębnych incydentów, które miały miejsce w ciągu 24 godzin, nasze systemy były niedostępne łącznie przez 30 minut. 30 podzielone przez dwa to 15, zatem nasz wskaźnik MTTR wynosi 15 minut.
Ograniczenia wskaźnika średniego czasu odzyskiwania
Ten wskaźnik MTTR jest miarą szybkości całego procesu odzyskiwania. Czy przebiega on tak szybko, jak chcesz? Jak wypada na tle konkurencji?
Jest to wskaźnik ogólny, który pomaga ustalić, czy występuje problem. Jeśli jednak chcesz zdiagnozować, w czym tkwi problem (czy dotyczy systemu obsługi alertów, poświęcania zbyt dużej ilości czasu na poprawki lub zbyt długiego czasu odpowiedzi na wnioski o poprawkę), musisz zdobyć więcej danych. Między awarią a odzyskaniem sprawności dzieje się bardzo wiele.
Problem może dotyczyć systemu obsługi alertów. Czy występuje opóźnienie między awarią a wygenerowaniem alertu? Czy przekazanie alertu właściwej osobie trwa dłużej niż powinno?
Problem może dotyczyć diagnostyki. Czy jesteś w stanie szybko ustalić, na czym polega problem? Czy istnieją procesy, które można poprawić?
Problem może tkwić również w naprawach. Czy zespoły serwisowe są maksymalnie skuteczne? Jeśli to ich działania pochłaniają większość czasu, co ich spowalnia?
Aby odpowiedzieć na te pytania, trzeba sięgnąć głębiej niż wskaźnik MTTR, jednak średni czas odzyskiwania może stanowić punkt wyjścia przy diagnozowaniu ewentualnych problemów w procesie odzyskiwania wymagających pogłębionej analizy.
Jak i kiedy korzystać ze wskaźnika średniego czasu odzyskiwania?
MTTR jest dobrym wskaźnikiem do oceny szybkości całego procesu odzyskiwania.
MTTR: średni czas rozwiązywania
Czym jest średni czas rozwiązywania?
MTTR (średni czas rozwiązywania) to średni czas potrzebny do całkowitego rozwiązania awarii. Obejmuje on nie tylko czas poświęcony na wykrycie awarii, zdiagnozowanie problemu i jego naprawę, ale także czas spędzony na upewnieniu się, że awaria się nie powtórzy.
Ten wskaźnik rozszerza zakres obowiązków zespołu zajmującego się rozwiązaniem o poprawę wydajności w dłuższej perspektywie. Posługując się analogią pożarową, mamy tu do czynienia nie tylko z ugaszeniem pożaru, ale też zabezpieczeniem przeciwpożarowym domu w jego następstwie.
Istnieje silna korelacja między tym wskaźnikiem MTTR a zadowoleniem klienta, dlatego warto poświęcić mu uwagę.
Jak obliczyć średni czas rozwiązywania?
Aby obliczyć ten wskaźnik MTTR, należy zsumować czas rozwiązywania w wymaganym okresie i podzielić go przez liczbę incydentów.
Jeśli więc Twoje systemy nie działały przez łącznie dwie godziny w ciągu 24-godzinnego okresu z powodu jednego incydentu, a zespoły spędziły dodatkowe dwie godziny na wprowadzanie poprawek w celu zagwarantowania, że nie dojdzie do ponownej awarii, łączny czas poświęcony na rozwiązanie problemu to cztery godziny. Zatem Twój wskaźnik MTTR wynosi cztery godziny.
Uwaga na temat śledzenia średniego czasu rozwiązywania
Należy pamiętać, że wskaźnik MTTR najczęściej oblicza się na podstawie godzin pracy (jeśli więc uda Ci się przywrócić system po awarii pod koniec pracy jednego dnia, a następnego dnia od samego rana zaczniesz pracować nad usunięciem głównej przyczyny problemu, Twój wskaźnik MTTR nie będzie obejmował 16 godzin spędzonych poza biurem). Jeśli masz zespoły rozmieszczone w wielu lokalizacjach i pracujecie przez całą dobę albo Twoi pracownicy pełnią dyżury domowe po godzinach pracy, musisz zdefiniować sposób rejestrowania czasu na potrzeby tego wskaźnika.
Jak i kiedy korzystać ze wskaźnika średniego czasu rozwiązywania?
Wskaźnika MTTR zazwyczaj używamy, mówiąc o nieplanowanych incydentach, a nie wnioskach o usługi (które są zazwyczaj planowane).
MTTR: średni czas reakcji
Czym jest średni czas reakcji?
MTTR (średni czas reakcji) to średni czas potrzebny na przywrócenie działania produktu lub systemu po awarii, liczony od momentu otrzymania pierwszego powiadomienia o awarii. Nie obejmuje on żadnych opóźnień w systemie obsługi alertów.
Jak obliczyć średni czas reakcji?
Aby obliczyć ten wskaźnik MTTR, należy zsumować całkowity czas reakcji, od momentu wystąpienia alertu do momentu przywrócenia pełnej funkcjonalności produktu lub usługi, a następnie podzielić otrzymaną wartość przez liczbę incydentów.
Jeśli na przykład w trakcie 40-godzinnego tygodnia pracy doszło do czterech incydentów, na które (od momentu wygenerowania alertu do naprawy) poświęcono łącznie godzinę, wskaźnik MTTR dla tego tygodnia wyniesie 15 minut.
Jak i kiedy korzystać ze wskaźnika średniego czasu reakcji?
Wskaźnik MTTR często stosuje się w cyberbezpieczeństwie jako miarę skuteczności zespołu w neutralizacji ataków na system.
MTTA: średni czas potwierdzenia
Czym jest średni czas potwierdzenia?
MTTA (średni czas potwierdzenia) to średni czas, który upływa od wygenerowania alertu do rozpoczęcia prac nad zgłoszeniem. Ten wskaźnik jest przydatny do śledzenia szybkości reakcji zespołu i skuteczności systemu obsługi alertów.
Jak obliczyć średni czas potwierdzenia?
Aby obliczyć wskaźnik MTTA, należy zsumować czas między wygenerowaniem alertu a potwierdzeniem, a następnie podzielić go przez liczbę incydentów.
Jeśli na przykład doszło do 10 incydentów, w przypadku których w sumie upłynęło od wygenerowania alertu do potwierdzenia 40 minut, wówczas należy podzielić 40 przez 10, co daje średnią wynoszącą cztery minuty.
Jak i kiedy korzystać ze wskaźnika średniego czasu potwierdzenia?
Wskaźnik MTTA jest przydatny w monitorowaniu szybkości reakcji. Czy Twój zespół doświadcza niewrażliwości na alerty i reakcja zajmuje zbyt wiele czasu? Ten wskaźnik pomoże Ci wykryć ewentualny problem.
MTTF: średni czas do wystąpienia awarii
Czym jest średni czas do wystąpienia awarii?
MTTF (średni czas do wystąpienia awarii) oznacza średni czas między awariami produktu technologicznego, których nie da się naprawić. Jeśli na przykład silniki samochodowe marki X pracują średnio 500 000 godzin, zanim ulegną całkowitej awarii i trzeba będzie je wymienić, wskaźnik MTTF w ich przypadku będzie wynosił 500 000.
To wyliczenie pozwala ustalić trwałość systemu, stwierdzić, czy nowa wersja systemu jest lepsza od starej, a także podać klientom informacje o spodziewanej żywotności i terminach przeprowadzania przeglądów ich systemu.
Jak obliczyć średni czas do wystąpienia awarii?
Średni czas bezawaryjnej pracy jest średnią arytmetyczną, dlatego oblicza się go przez zsumowanie całkowitego czasu działania ocenianych produktów, a następnie podzielenie wyniku przez łączną liczbę urządzeń.
Załóżmy na przykład, że chcemy ustalić wskaźnik MTTF żarówek. Jak długo świecą się średnio żarówki marki Y, zanim się spalą? Załóżmy, że mamy do przetestowania cztery żarówki (aby uzyskać dane istotne statystycznie, potrzeba więcej sztuk, jednak dla uproszczenia obliczeń będziemy trzymać się małych liczb).
Żarówka A świeci 20 godzin. Żarówka B świeci 18 godzin, a żarówka C — 21 godzin. Żarówka D świeci 21 godzin. To w sumie 80 godzin pracy żarówek. Po podzieleniu przez cztery uzyskuje się wskaźnik MTTF wynoszący 20 godzin.

Problem ze wskaźnikiem średniego czasu do wystąpienia awarii
W przypadku produktu, takiego jak żarówki, wyznaczenie wskaźnika MTTF ma sens. Możemy świecić żarówki, dopóki ostatnia z nich nie zgaśnie, i wykorzystać uzyskane informacje do wyciągnięcia wniosków dotyczących trwałości naszych żarówek.
Ale co zrobić, gdy pomiary dotyczą rzeczy, które nie ulegają awarii tak szybko? Rzeczy, które zachowują trwałość przez długie lata? W tych przypadkach wskaźnik MTTF, choć jest często stosowany, nie jest dobrym rozwiązaniem. Jest to spowodowane tym, że zamiast eksploatowania produktu do czasu jego awarii najczęściej eksploatujemy produkt przez określony czas, a następnie mierzymy, ile sztuk uległo awarii.
Załóżmy na przykład, że chcemy wyznaczyć wskaźnik MTTF dla tabletów marki Z. Tablety są zaprojektowane do wieloletniej pracy (a przynajmniej mamy taką nadzieję). Jednak producent marki Z ma na zebranie danych jedynie sześć miesięcy. Zatem przez sześć miesięcy testuje 100 tabletów. Załóżmy, że dokładnie po sześciu miesiącach jeden tablet ulegnie awarii.
Mnożymy zatem łączny czas pracy (sześć miesięcy razy 100 tabletów), uzyskując wynik 600 miesięcy. Jeden tablet uległ awarii, zatem dzielimy tę wartość przez jeden, uzyskując wskaźnik MTTR wynoszący 600 miesięcy, czyli 50 lat.
Czy każdy z tabletów marki Z przetrwa 50 lat? Mało prawdopodobne. Dlatego ten wskaźnik w podobnych przypadkach się nie sprawdza.
Jak i kiedy korzystać ze wskaźnika średniego czasu do wystąpienia awarii?
Wskaźnik MTTF sprawdza się dobrze przy próbach oceny średniego czasu eksploatacji produktów i systemów o krótkiej żywotności (takich jak żarówki). Stosuje się go również tylko w przypadkach całkowitych awarii produktów. Jeśli ma być obliczany czas między incydentami wymagającymi naprawy, lepszym wyborem będzie wskaźnik MTBF (średni czas bezawaryjnej pracy).
MTBF, MTTR, MTTF i MTTA
Który z pomiarów lepiej sprawdzi się w śledzeniu i doskonaleniu procesu zarządzania incydentami?
Odpowiedź brzmi: wszystkie.
Choć czasami używa się ich zamiennie, każdy ze wskaźników daje wgląd w inne zagadnienia. Ich połączenie może dać pełny obraz skuteczności zespołu w zarządzaniu incydentami oraz potencjalnych obszarów poprawy.
Średni czas odzyskiwania informuje, jak szybko możesz przywrócić działanie systemu.
Wystarczy przyjrzeć się średniemu czasowi reakcji, aby zorientować się, ile czasu odzyskiwania przypada na działania zespołu, a ile na system obsługi alertów.
Sięgając dalej do średniego czasu naprawy, zaczynasz dostrzegać, ile czasu zespół poświęca na naprawy, a ile na diagnostykę.
Jeżeli dodasz do tego średni czas rozwiązywania, zaczniesz dostrzegać pełny zakres naprawiania i rozwiązywania problemów poza faktycznym czasem przestoju, który powodują.
Uwzględniając średni czas bezawaryjnej pracy, uzyskasz jeszcze szerszy obraz ilustrujący skuteczność zespołu w zapobieganiu przyszłym problemom lub ograniczaniu prawdopodobieństwa ich wystąpienia.
Dodanie na koniec średniego czasu do wystąpienia awarii pozwoli zrozumieć pełny cykl życia produktu lub systemu.
Jira Service Management oferuje funkcje raportowania, dając Twojemu zespołowi możliwość śledzenia wskaźników KPI oraz monitorowania i optymalizacji praktyki zarządzania incydentami.
Omawiane produkty
Scentralizowanie alerty i powiadamianie właściwych osób we właściwym czasie.
Poznaj proces informowania o incydentach za pomocą Statuspage
W tym samouczku pokażemy, jak wykorzystać szablony dotyczące incydentów do skutecznej komunikacji w trakcie awarii. Ich elastyczny charakter pozwala na dostosowanie ich do różnego rodzaju przerw w dostawie usług.
Przeczytaj ten samouczekSzablony i przykłady informowania o incydentach
Podczas reagowania na incydent szablony komunikatów są nieocenione. Pobierz szablony, z których korzysta nasz zespół, a także inne przykłady dotyczące częstych incydentów.
Przeczytaj ten artykuł