Zarządzanie incydentami dla dynamicznych zespołów
Optymalizacja zarządzania incydentami na potrzeby eksploatacji IT
Awarie wpływają na wyniki finansowe.
Przestoje często oznaczają nie tylko utratę przychodów, ale także uszczerbek na reputacji, kary ustawowe i związane z nieprzestrzeganiem przepisów, utratę klientów oraz wzrost kosztów operacyjnych i opóźnień, ponieważ specjaliści IT są odrywani od innych projektów w celu rozwiązania incydentów.
Według jednego z raportów opublikowanych przez IHS szacowane koszty przestojów w organizacjach z Ameryki Północnej przekraczają 700 mld USD rocznie — a 78% tej kwoty przypisuje się spadkowi wydajności pracowników.
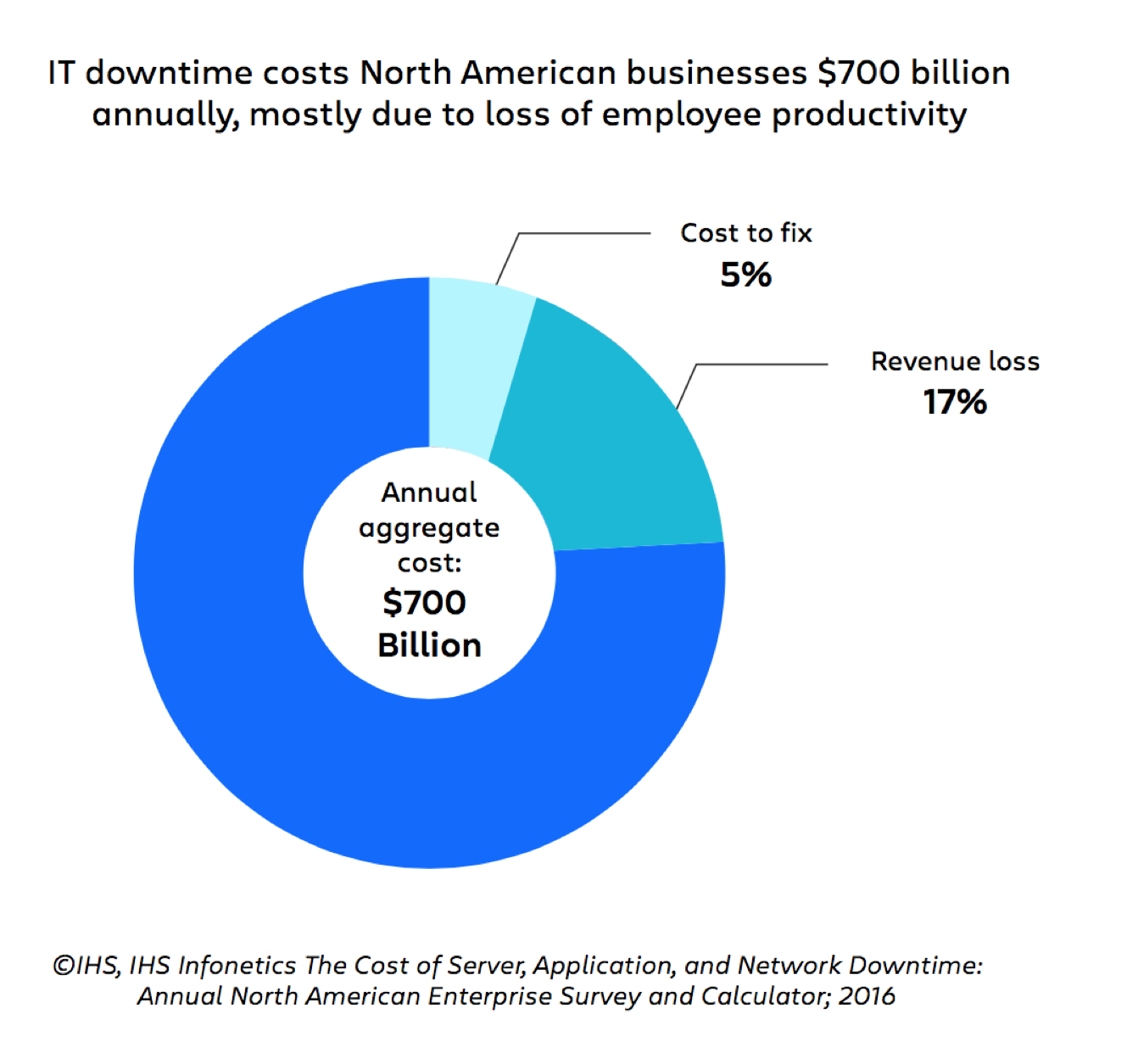
Przedstawione liczby jasno pokazują, że utracone dochody nie są jedynym — ani nawet najważniejszym — priorytetem zarządzania incydentami. Zoptymalizowany proces zarządzania incydentami musi również sprostać bardzo realnym, bardzo kosztownym wyzwaniom związanym z ludźmi, procesami i technologią stojącymi za zarządzaniem incydentami.
Wyzwania stojące przed nowoczesnym zarządzaniem incydentami IT
Rozłączne procesy i technologie
Skutkiem ubocznym 40 lat innowacji w dziedzinie technologii komputerowych jest fakt, że wiele firm korzysta obecnie z eklektycznej mieszaniny aplikacji i systemów. Niektóre aplikacje funkcjonują we własnych centrach danych, gdzie można je ściśle kontrolować, podczas gdy inne są dostarczane w chmurze i zarządzane przez dostawców zewnętrznych.
Ten zbiór aplikacji, usług i systemów często skutkuje mozaiką luźno powiązanych rozwiązań i procesów do rejestrowania, monitorowania i obsługi alertów. Nierzadko zdarza się, że firmy używają dziesiątek narzędzi monitorujących do śledzenia tysięcy zdarzeń w aplikacjach lub alertów dziennie.
Takie mieszane podejście może prowadzić do przytłaczającej liczby alertów, załamania komunikacji, braku przejrzystości priorytetów alertów napływających do pracowników pełniących dyżur domowy oraz sytuacji, w której awaria na jednym etapie tego patchworkowego procesu może doprowadzić do jego całkowitego zatrzymania.
Przytłaczająca liczba alertów/incydentów
Wiele działów ds. eksploatacji IT kieruje alerty do skrzynek pocztowych, aby przeciwdziałać problemowi ich znacznej liczby. To jednak tylko pogarsza sprawę, ponieważ prowadzi do sytuacji, w której personel wyższego szczebla odpowiedzialny za ustalanie priorytetów incydentów i eskalowanie wiadomości krytycznych musi monitorować pocztę w trybie 24/7.
Taki niekończący się strumień alertów może być przytłaczający i prowadzić do niewrażliwości na alerty, wypalenia, braku zadowolenia z pracy, niepokojów i wydłużenia czasów reakcji. Wpływa to zarówno na samopoczucie pracowników w miejscu pracy, jak i na ich produktywność, co z kolei bezpośrednio przekłada się na wyniki firmy.
Rosnące koszty operacyjne
Choć koszty infrastruktury spadły, koszty operacyjne wzrosły — częściowo wynika to ze złożoności problemów z debugowaniem, które występują, gdy nie ma się kontroli nad całym systemem.
Pomiar niewłaściwych wskaźników sukcesu
Skuteczność operacyjną centrum obsługi często mierzono w oparciu o wskaźniki, jak takie przepustowość połączeń czy średni czas połączenia — przy czym żaden z nich nie przyczynia się ani nie mierzy w sposób bezpośredni efektywności zarządzania incydentami.
Nawet przydatne wskaźniki, takie jak MTTR i MTBF, same w sobie nie wystarczą do poprawy wydajności zarządzania incydentami. Mają one ułatwić zidentyfikowanie problemu, jednak nie dają odpowiedzi na trudniejsze, bardziej jakościowe pytania o przyczyny występowania i sposób rozwiązywania incydentów ani nie wskazują, jak można poprawić te wskaźniki.
Przestarzałe struktury zespołów reagujących na incydenty
Jeszcze dziesięć lat temu reagowanie na incydenty IT było zadaniem przede wszystkich zespołów ds. eksploatacji. Organizacje zazwyczaj stosowały warstwową strukturę zespołów (poziomy 1, 2 i 3) w celu reagowania na problemy zgłaszane przez klientów lub narzędzia monitorujące.
Cele zarządzania incydentami były wówczas takie same: zminimalizować koszty operacyjne przy jednoczesnym zachowaniu poziomu usług. W związku z tym osobami reagującymi na poziomie 1 byli zazwyczaj tańsi pracownicy najniższego szczebla. Jeśli nie mogli rozwiązać incydentu, eskalowali go do poziomu 2 (zazwyczaj bardziej doświadczonych specjalistów średniego szczebla). Taki proces eskalacji kontynuowano, aż do rozwiązania problemu.
Choć w tym procesie priorytetem jest oszczędność, wypracowuje się ją kosztem zwinności. Wydłużony czas reakcji zespołu, który zaczyna obsługę incydentów od pracowników najniższego szczebla, a następnie eskaluje incydent przez wiele poziomów, może wpłynąć bezpośrednio na czasy rozwiązywania incydentów, a to z kolei przekłada się wprost na pogorszenie reputacji firmy, ponieważ klienci wylewają swoją frustrację na kanałach w mediach społecznościowych.
Ponadto fakt, że firmy tracą 78% środków związanych z zarządzaniem incydentami na spadku wydajności pracowników, wyraźnie wskazuje, że model eskalacji nie przynosi firmie oszczędności. Jeśli osoba, która opracowała oprogramowanie może naprawić błąd w ciągu 15 minut, a pracownik najniższego szczebla spędza nad problemem dwie godziny, po czym i tak go eskaluje, nie jest to wydajny system.
W świecie zawsze dostępnych usług zwinność staje się ważniejsza niż kiedykolwiek. Takie wskaźniki, jak średni czas reakcji i średni czas rozwiązywania, zyskały na popularności właśnie dlatego, że firmy muszą zapewnić sobie maksymalną zwinność, jeśli chcą ograniczyć koszty do minimum.
Jak zoptymalizować proces zarządzania incydentami IT?
Oczywiste jest, że nadszedł czas, aby zwrócić nasze wysiłki związane z zarządzaniem incydentami na procesy, struktury zespołowe i praktyki, które odzwierciedlają dzisiejszą nową rzeczywistość biznesową. Jednak w jaki sposób przebiega taki zwrot?
Ustalanie priorytetów i konsolidacja alertów
Główną przyczyną niewrażliwości na alerty i jednym z kluczowych czynników prowadzących do obniżenia produktywności jest nadmiar nieistotnych, nieużytecznych alertów. Jak najłatwiej to zmienić? Zidentyfikuj systemy krytyczne, wyeliminuj nadmiarowe powiadomienia i utwórz przejrzystą hierarchię priorytetów alertów.
Utworzenie harmonogramu dyżurów domowych dostosowanego do potrzeb zespołów
Aby uniknąć niewrażliwości na alerty, wypalenia i obniżenia wydajności, trzeba również opracować harmonogram dyżurów domowych, który sprawdzi się w przypadku konkretnych zespołów. Trzeba zadbać o to, aby żaden zespół ani członek zespołu nie był przeciążony, zapewniając w razie potrzeby zastępstwa, a także regularnie weryfikować skuteczność opracowanego harmonogramu.
Automatyzacja w miarę możliwości
Łatwo o dekoncentrację, gdy trzeba ręcznie przeglądać dziesiątki raportów, aby wyszukać i eskalować te, które są istotne. Dobra wiadomość jest taka, że nie musi już tego robić ręcznie żaden członek zespołu i można uniknąć spadku wydajności i niewrażliwości na alerty, usuwając to zadanie z listy zadań dzięki automatyzacji.
Przekierowywanie alertów, powiadamianie, usuwanie duplikatów, obsługiwanie przepływów wiadomości, tworzenie mostków konferencyjnych, zamieszczanie aktualności na stronie stanu, tworzenie harmonogramu dyżurów domowych, obsługa procesów eskalacji czy śledzenie wskaźników KPI — to wszystko czynności, które można przynajmniej częściowo zautomatyzować, aby zaoszczędzić zespołowi czasu i ograniczyć ryzyko błędu ludzkiego przy wykonywaniu określonych, powtarzalnych zadań. Nie wspominając o tym, że z czasem automatyzacja przynosi firmie oszczędności finansowe.
Skuteczna komunikacja za pośrednictwem kanałów i z interesariuszami
Incydenty mają wpływ na różnych interesariuszy — często zarówno wewnętrznych, jak i zewnętrznych — dlatego trzeba zapewnić im dostęp do informacji. Badania wykazują, że 87% interesariuszy w firmach chce otrzymywać aktualne informacje o incydentach (a 56% z nich deklaruje, że bardziej frustruje ich brak komunikacji niż sam incydent). Klienci mają zdecydowanie podobne odczucia.
W czasach, gdy oczekuje się ciągłej dostępności, solidny plan komunikacji na wypadek incydentów jest niezbędnym elementem procesu optymalizacji.
Ułatwienie śledzenia właściwych wskaźników
Im łatwiej śledzić i przeglądać wskaźniki sukcesu, tym większe prawdopodobieństwo, że zespół będzie to robił. W miarę możliwości zautomatyzuj tworzenie raportów i z góry ustal, które wskaźniki są istotne dla Twojego zespołu i dlaczego.
Przeprowadzenie analiz post-mortem bez wskazywania winnych
Przywrócenie działania aplikacji lub bazy danych nie oznacza zakończenia incydentu. Aby zapobiegać incydentom, skracać czas poświęcany na ich rozwiązywanie w przyszłości oraz lepiej zrozumieć wpływ procesów, zespołów i zasad na zarządzanie incydentami, trzeba przeprowadzać analizy post-mortem.
W Atlassian przeprowadzamy analizy post-mortem bez wskazywania winnych, co oznacza, że koncentrują się one na poprawie wydajności i posuwaniu prac naprzód, a nie na szukaniu winnych.
Wybór technologii wspierającej Twoje procesy i potrzeby
Automatyzacja. Priorytetyzacja alertów. Harmonogram dyżurów domowych. Śledzenie wskaźników KPI. Aby każdy z tych podstawowych procesów przynosił efekty, potrzebna jest obsługująca go technologia. Zanim wybierzesz technologię, upewnij się, że rozumiesz swoje cele, procesy i potrzeby zespołu. Jeśli chcesz automatycznie porządkować alerty, eliminować duplikaty i nadawać alertom priorytety, potrzebujesz rozwiązania, które oferuje takie funkcje — takiego jak Jira Service Management.
Poznaj proces informowania o incydentach za pomocą Statuspage
W tym samouczku pokażemy, jak wykorzystać szablony dotyczące incydentów do skutecznej komunikacji w trakcie awarii. Ich elastyczny charakter pozwala na dostosowanie ich do różnego rodzaju przerw w dostawie usług.
Przeczytaj ten samouczekSzablony i przykłady informowania o incydentach
Podczas reagowania na incydent szablony komunikatów są nieocenione. Pobierz szablony, z których korzysta nasz zespół, a także inne przykłady dotyczące częstych incydentów.
Przeczytaj ten artykuł