针对高速团队的事件管理
SLA、SLO 与 SLI:有什么区别?
如果说每家技术公司都有一个共同点,那就是:用户。
无论您是谷歌的搜索引擎,为每月免费与您的服务互动的十亿活跃用户提供服务,还是拥有 375 万付费用户的 Salesforce,开发技术产品都意味着为人服务。
在当今永不停机的世界中,人们对免费和付费服务的期望都很高。速度、正常运行时间、有用的用户体验。当今的用户群期望一切都能达到高标准。
Looker 相信 Opsgenie 能够帮助他们每天向 200,000 名用户交付服务。
这就是为什么公司必须了解和维护 SLA、SLO 和 SLI 的原因,这三个词代表了我们对用户的承诺、帮助我们兑现这些承诺的内部目标以及告诉我们表现的可跟踪衡量标准。
这三个指标致力于让所有人(无论是供应商还是客户)在系统性能问题方面保持同步。您的系统多久可用一次?如果系统出现故障,您的团队会以多快的速度做出响应?您在速度和功能方面做了什么样的承诺?用户想知道,所以您需要 SLA、SLO 和 SLI。
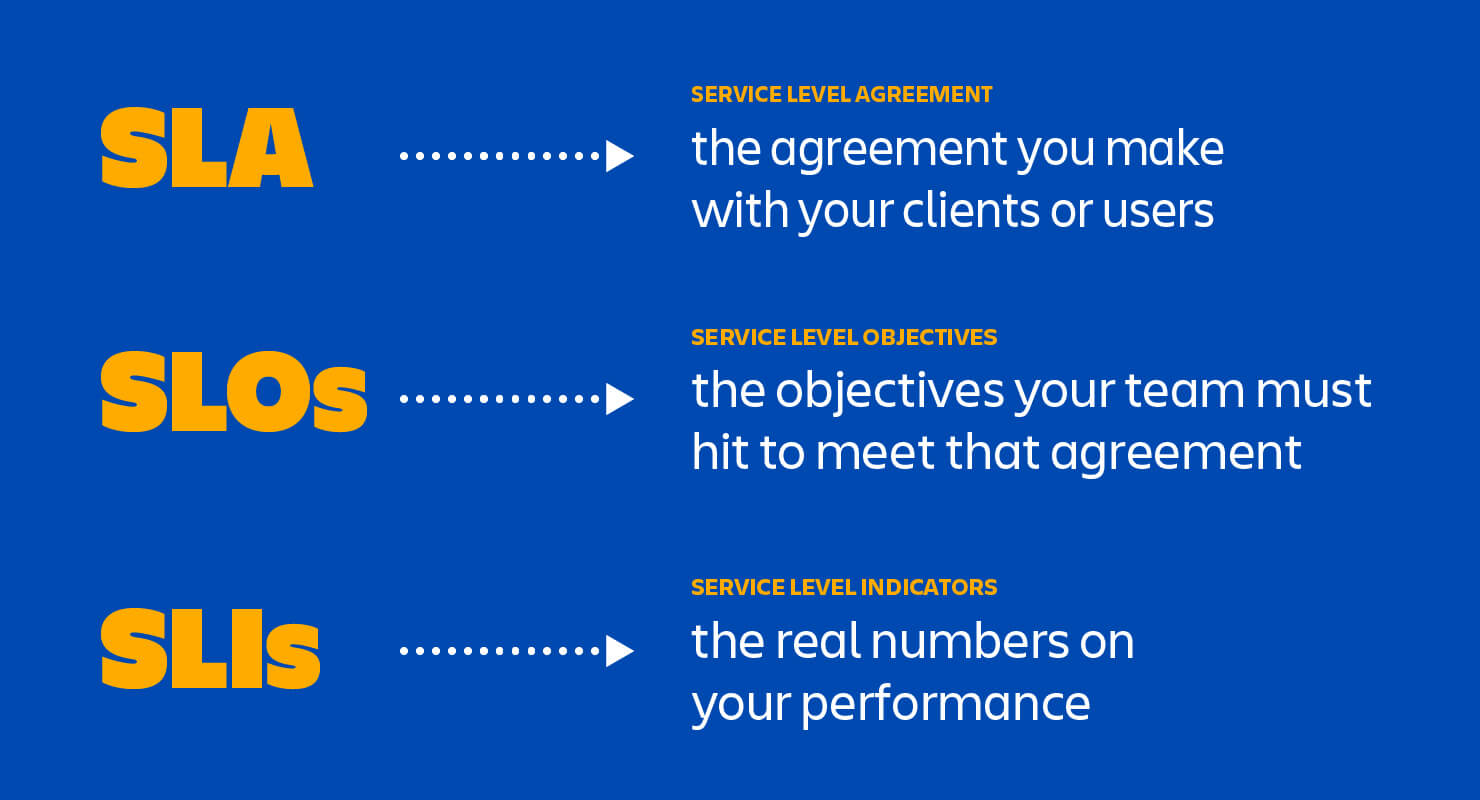
SLA:服务级别协议
什么是 SLA?
SLA(服务级别协议)是提供商和客户之间关于正常运行时间、响应能力和责任等可衡量指标的协议。
这些协议通常由公司的新业务和法律团队起草,它们代表了您对客户的承诺,以及如果您未能兑现这些承诺所产生的后果。通常,后果包括经济处罚、服务抵免或许可证延期。
SLA 面临的挑战
众所周知,SLA 很难衡量、报告和满足相关条件。这些协议通常由非技术领域的人撰写,通常做出的承诺很难让团队衡量,并没有始终与当前和不断变化的业务优先级保持一致,也没有考虑到细微差别。
例如,SLA 可能承诺团队将在 24 小时内解决所报告的产品 X 问题。但是,同样的 SLA 并未说明如果客户花了 24 小时发送答案或屏幕截图来帮助您的团队诊断问题会发生什么。这是否意味着团队的 24 小时窗口因客户花费的时间而消耗殆尽,还是计时的开始和结束取决于客户的回复时间?SLA 需要回答这些问题,但他们往往做不到,这就导致 IT 管理者对他们产生了极大的敌意。
对于许多专家来说,这一挑战的答案首先是技术应该参与 SLA 的制定。IT 和 DevOps 与法律和业务发展部门合作制定可应对实际情景的 SLA 越多,SLA 就越能开始反映关键现实,例如客户推迟解决自己的问题。
谁需要 SLA?
SLA 是供应商和付费客户之间的协议。向用户免费提供服务的公司不太可能希望或需要为这些免费用户提供 SLA。
SLO:服务级别目标
什么是 SLO?
SLO(服务级别目标)是在 SLA 中就正常运行时间或回复时间等特定指标达成的协议。因此,如果 SLA 是您与客户之间的正式协议,SLO 就是您向该客户作出的个人承诺。SLO 可以设定客户期望,告诉 IT 和 DevOps 团队他们需要实现哪些目标并根据哪些目标来衡量自己。
SLO 面临的挑战
SLO 不如 SLA 那么麻烦,但是如果它们含糊不清、过于复杂或无法衡量,则可能会造成同样多的问题。SLO 不会让工程师抓狂的关键在于简单明了。只有最重要的指标才有资格获得 SLO 状态,目标应以通俗易懂的语言阐明,并且与 SLA 一样,应始终考虑客户端延迟等问题。
谁需要 SLO?
如果 SLA 仅与付费客户相关,则 SLO 对付费和未付费帐户以及内部和外部客户均有用。
内部系统,例如 CRM、客户数据存储库和内联网,可能与面向外部的系统一样重要。而且,为这些内部系统设定 SLO 不仅是实现业务目标的重要组成部分,也是使内部团队能够实现面向客户的目标的重要组成部分。
SLI:服务级别指标
什么是 SLI?
SLI(服务级别指标)衡量对 SLO(服务级别目标)的合规性。因此,例如,如果您的 SLA 规定您的系统在 99.95% 的时间内可用,则您的 SLO 正常运行时间可能为 99.95%,而您的 SLI 是衡量正常运行时间的实际标准。也许是 99.96%,也可能是 99.99%。为了遵守您的 SLA,SLI 需要达到或超过该文件中所承诺的条件。
SLI 面临的挑战
与 SLO 一样,SLI 面临的挑战是保持简单,选择正确的指标进行跟踪,而不是因为跟踪太多对客户实际上并不重要的指标而使 IT 工作变得过于复杂。
制定详细的灾难恢复计划
停机期间时您会怎么做?如果您不知道该怎么做,默认答案将是“浪费宝贵的时间来弄清楚该怎么做”。
您的事件响应计划越好,团队处理事件的速度就越快、越有效。这就是为什么新的事件管理计划第一步都应该是流程和规划。
谁需要 SLI?
任何根据 SLO 衡量其绩效的公司都需要 SLI 才能进行这些测量。没有 SLI,就不可能真正有 SLO。
SLA、SLO 和 SLI 最佳实践
根据客户期望制定 SLA
客户协议的每个部分都应围绕对客户至关重要的内容来制定。在终端,事件可能意味着处理 10 个不同的组件。但在客户看来,重要的是系统能否按预期运行。
您的 SLA 和 SLO 应反映这一现实。不要通过深入到精细级别并针对这 10 个组件中的每一个做出单独的承诺,这会导致事情变得过于复杂。承诺仅限于高级、面向用户的功能。这将使客户更满意,困惑更少,并减轻负责兑现您的 SLA 承诺的 IT 专业人员的工作。
在 SLA 中使用通俗易懂的语言
客户不会总是要求澄清,因此,如果您的 SLA 语言很复杂,您可能会遇到一些不好的误解。您的语言越简单,将来发生客户冲突的可能性就越小。
有了 SLO,少即是多
并非每个指标都对客户的成功至关重要,这意味着并非每个指标都应该是 SLO。承诺尽可能少 SLO,将重点放在对客户最重要的 SLO 上。
并非每个可跟踪的指标都应该是 SLI
同样,针对 10 个 SLO 中的每一个跟踪 10 个组件的性能很快就会变得非常困难。相反,应战略性地选择哪些指标对您的核心 SLO 真正重要,然后投入精力来有效地跟踪这些指标。
包括 IT 团队无法控制的因素
当客户拖慢了解决问题的速度时,会发生什么?如果您在 SLA 中对此没有明确规定,您的团队可能无法在没有客户参与的情况下解决客户问题。
建立错误预算
为故障留出余地不仅可以保护企业免受违反 SLA 的行为和严重后果的影响,还可以为敏捷性留出空间,让团队能够快速做出改变,并有空间尝试可能失败的创新型新解决方案。
实际上,谷歌建议将剩余的错误预算用于计划内停机期间,这可以帮助您识别不可预见的问题(例如服务不当使用服务器),并保持客户的合理预期。
不要设定太高的目标
Just because your team can probably maintain 99.99% uptime doesn’t mean that 99.99% should be your SLO number. It’s always better to under-promise and overdeliver. This is especially true for agile teams who want to launch early and often and need an error budget to keep up that quick pace.
这对 SRE 有何影响?
对于那些遵循谷歌模式并使用站点可靠性工程 (SRE) 团队弥合开发与运维之间差距的人来说,SLA、SLO 和 SLI 是成功的基础。SLA 帮助团队设定界限和错误预算,SLO 有助于确定工作的优先级,而 SLI 会告诉 SRE 何时需要冻结所有发布以节省所剩无几的错误预算,以及他们何时可以放松控制。
通过 Jira Service Management,始终掌握服务级别协议 (SLA) 情况,根据优先级解决请求,并使用自动上报规则通知正确的团队成员并防止违反 SLA。