针对高速团队的事件管理
如何选择事件管理 KPI 和指标
随着时间的推移跟踪和改善事件管理
在当今永不停机的世界中,技术事件会带来重大后果。
系统停机期间导致公司收入损失、员工生产力下降和维护费用,平均每小时达 30 万美元。重大中断可能远远超过这些成本(可以看看达美航空的例子,它在 2017 年 IT 中断后损失了大约 1.5 亿美元)。而且,无法支付账单、无法通过视频会议参加重要会议或购买机票的客户很快就会将业务转移到竞争对手那里。
由于危在旦夕,团队比以往任何时候都更需要跟踪事件管理 KPI,并利用他们的发现来检测、诊断、修复并最终预防事件。
好消息是,对于网络和软件事件(与机械和离线系统不同),团队通常能够捕获更多的数据来帮助他们理解和改进。
坏消息?有时候,过多的数据会掩盖问题,而不是揭示问题。
事件 KPI、指标和分析的价值
KPI(关键绩效指标)是帮助企业确定是否实现特定目标的指标。对于事件管理,这些指标可以是事件数、平均解决时间或平均事件间隔时间。
跟踪事件管理的 KPI 可以帮助识别和诊断流程和系统中的问题,为团队设定基准和切合实际的目标,并为更大的问题提供起点。
例如,假设企业的目标是在 30 分钟内解决所有事件,但您的团队目前平均需要 45 分钟。如果没有具体的指标,就很难知道出了什么问题。您的警报系统花费的时间太长了吗?您的流程中断了吗?您的诊断工具需要更新吗?是团队问题还是技术问题?
现在,添加一些指标:如果您确切知道警报系统需要多长时间,则可以确定其是否为问题所在。如果您发现诊断占用了超过 50% 的时间,则可以将故障排除重点放在那里。如果您发现 B 团队花费的时间比 A、C 和 D 团队多 25%,您可以研究一下原因。
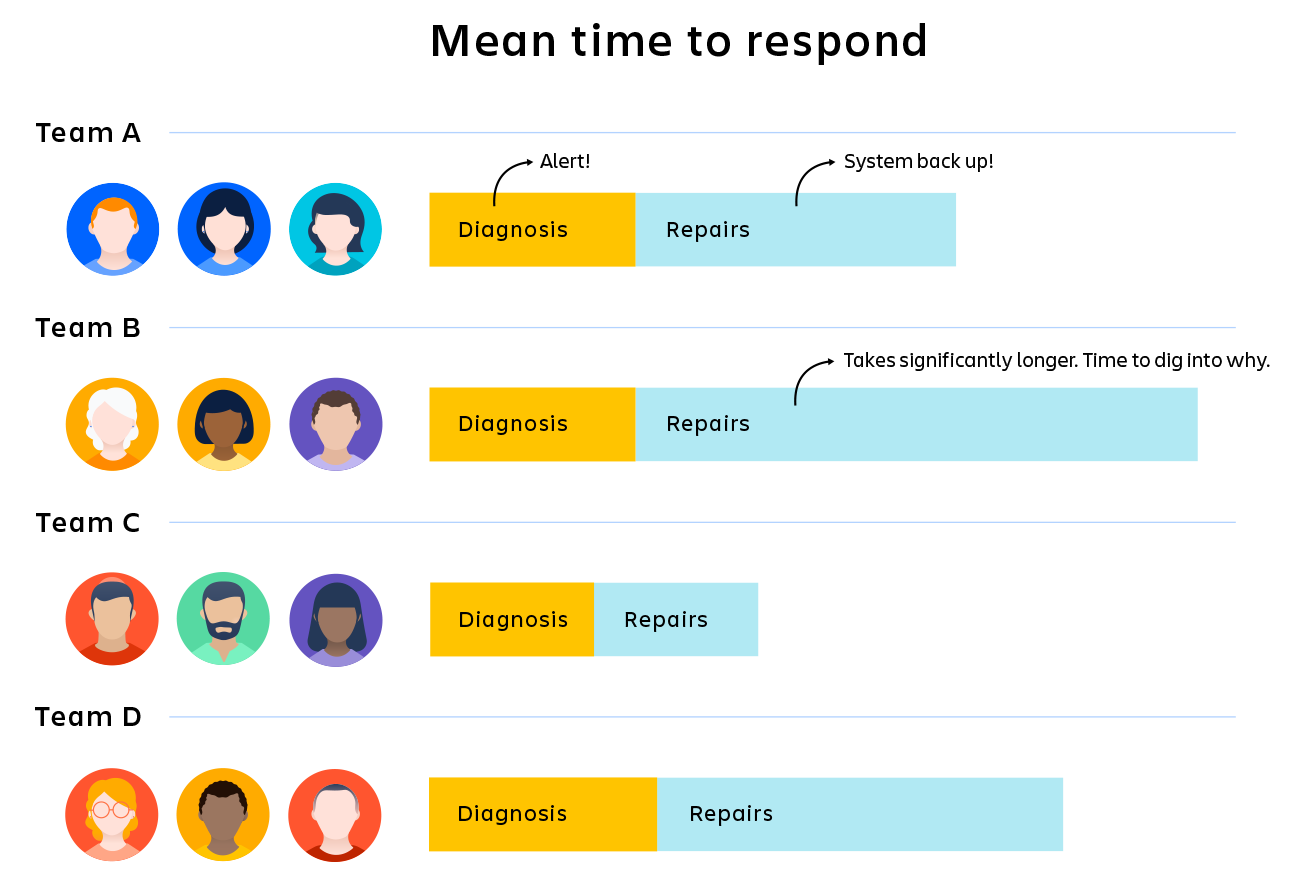
KPI 不会自动解决您的问题,但它们会帮助您了解问题出在哪里,集中精力在正确的地方进行更深入的挖掘。
热门事件 KPI 和指标
警报已创建
如果您使用的是警报工具,了解在给定时间段内生成多少警报会很有帮助。使用类似 Jira Service Management 的解决方案,您既可以发送警报,也可以启动报告和仪表板对其进行跟踪。
留意有显著、异常的增加或减少或数字呈上升趋势的时期,看到这些变化时,应该更深入地了解这些变化发生的原因以及您的团队是如何应对这些变化的。
事件持续时间
跟踪一段时间内的事件意味着查看一段时间内事件的平均数量。这可能意味着每周、每月、每季度、每年甚至每天。
随着时间的推移,事件发生的频率是增加还是降低?事件数量是可以接受还是可以更低一些?一旦您发现了事件数量方面的问题,您就可以开始了解为什么这个数字呈上升趋势或保持较高水平,以及团队可以做些什么来解决这个问题。
MTBF
MTBF(平均故障间隔时间)是技术产品两次可修复故障之间的平均时间。它可以帮助您跟踪产品的可用性和可靠性。
与其他指标一样,对于较大的问题,这是一个很好的起点。如果您的 MTBF 低于您想要的水平,是时候了解一下为什么系统经常出现故障,以及如何减少或防止将来的故障了。
MTTA
MTTA(平均确认时间)是系统警报到团队成员确认事件并开始解决事件之间的平均时间。该指标的价值在于了解您的团队对问题的响应程度。
一旦您知道存在响应问题,您就可以再次开始更深入地挖掘原因了。为什么您的 MTTA 很高?团队负担过重吗?分心?不清楚警报是谁的责任?MTTA 可以帮助您确定问题,而像这样的问题可以帮助您找到问题的核心。
MTTD
MTTD(平均检测时间)是您的团队发现问题所花费的平均时间。该术语通常用于网络安全,团队专注于检测攻击和漏洞时。
如果这个指标发生了巨大变化或者没有完全达到目标,那么现在是时候了解一下原因了。
MTTR
MTTR 可以代表平均修复、解决、响应或恢复时间。可以说,这些指标中最有用的是平均解决时间,它不仅跟踪诊断和修复眼前问题所花费的时间,还跟踪确保问题不再发生所花费的时间。恢复是主要的 DevOps 指标,DevOps 研究与评估 (DORA) 指出,这是衡量 DevOps 团队稳定性的关键。
同样,此指标在诊断时使用最佳。您的解决方案是否如您想要的那样快速、高效?如果不是,是时候问更深层次的问题了,了解上述解决时间是如何以及为什么没有达到目标的。
正如 DevOps 研究与评估 (DORA) 指出的那样,恢复是一项关键的 DevOps 指标,衡量了 DevOps 团队的稳定性。它是检测、缓解和解决问题所花费的总时间。
待命时间
如果您有待命轮换,跟踪员工和承包商在待命上花费的时间可能会有所帮助。该指标可以帮助您确保没有一个员工或团队负担过重。
使用 Jira Service Management,您可以生成综合性报告,使这些数据一目了然。
SLA
SLA(服务级别协议)是提供商和客户之间关于正常运行时间、响应能力和责任等可衡量指标的协议。
在 SLA 中做出的承诺(关于正常运行时间、平均恢复时间等)是事件管理团队需要跟踪这些指标的原因之一。如果平均响应时间或平均故障间隔时间等因素发生变化,则需要快速更新合约和/或进行修复。
SLO
SLO(服务级别目标)是在 SLA 中就正常运行时间等特定指标达成的协议。与 SLA 一样,SLO 是需要跟踪的重要指标,以确保公司在客户服务方面坚守承诺。
时间戳(或时间线)
时间戳是关于在事件发生期间、之前或之后的特定时间所发生的事情的编码信息。这些信息通常不被视为衡量标准,但在评估事件管理运行状况和提出改进策略时,该数据非常重要。
时间戳可帮助团队制定事件的时间线,以及准备和应对工作。清晰、共享的时间线是事件事后分析中最有用的工件之一。
运行时间
正常运行时间是系统可用和正常运行的时间(以百分比表示)。
在线服务的连接性不断提高,系统本身的复杂性越来越高,这意味着通常无法保证 100% 的正常运行时间。大多数产品的目标是高可用性,即系统或产品可以长时间不间断地运行。行业标准规定,99.9% 的正常运行时间非常好,99.99% 的正常运行时间超级好。
根据这个指标来跟踪您的成功与否,就是向客户做出并兑现承诺。而且,与其他指标一样,这只是一个起点。如果您的正常运行时间未达到 99.99%,那么需要进行更多研究来了解原因,与团队谈话,并调查流程、结构、访问权限或技术。
关于事件分析的注意事项
KPI 的缺点是很容易过于依赖浅层数据。知道团队解决事件的速度不够快,这本身并不能解决问题。因为您仍然需要知道团队解决或无法解决问题的方式和原因。而且您还需要知道您正在比较的问题是否真的具有可比性。
通过 KPI,您无法了解团队是如何处理棘手问题的。KPI 无法解释为什么您的事件间隔时间会越来越短而不是越来越长。他们无法判断为什么事件 A 花费的时间是事件 B 的三倍。
为此,您需要洞察信息。尽管数据可以成为获得这些洞察信息的起点,但它也可能是一个绊脚石。即使我们的指标没有改善,它也会让我们觉得自己做得足够了。它可以将实际上截然不同、应该以不同的方式处理的事件汇总在一起。它可能会降低您的团队的体验和事件本身的潜在复杂性。
“事件比您想象的传统认知要独特得多。两起时间相同的事件在人们如何理解正在发生的事情方面可能会产生截然不同的意外程度和不确定性。在采取旨在缓解或改善情况的行动方面,它们还可能包含截然不同的风险。事件不是正在制造的小工具,而在这种小工具中,物理尺寸的有限变化被视为质量的关键标志。”
- John Allspaw,Moving Past Shallow Incident Data(超越浅层事件数据<)
这里的重点不在于 KPI 不好,我们不应该因噎废食,关键在于 KPI 还不够。它们是起点,是一种诊断工具,是迈向更复杂的真正改进的第一步。
Jira Service Management 提供报告功能,因此您的团队可以跟踪 KPI 并监控和优化您的事件管理实践。