Agile methodologieën worden steeds vaker gebruikt buiten het traditionele domein van softwareontwikkeling in alle verschillende bedrijfsgebieden zelfs marketing! Dus we begonnen na te denken: hoe ziet agile eruit in de wereld van incidentmanagement? Bij Atlassian definiëren we agile als een gestructureerde en iteratieve benadering van projectmanagement en productontwikkeling. Het geeft je de mogelijkheid om op veranderingen te reageren zonder te ontsporen.
Aangezien bugs in productie, incidenten en downtime zeker geclassificeerd kunnen worden als momenten waarop dingen 'ontsporen', dachten we dat een methodologie als agile - gebouwd om teams te helpen op de rails te blijven - een natuurlijke plaats zou innemen in incidentmanagement, met name bij incidentcommunicatie.
Agile waarden toepassen op incidentrespons
Hoewel er geen tekort is aan tools om je team te helpen incidenten te detecteren, te waarschuwen, op te sporen en op te lossen, kunnen tools alleen geen duidelijke vervanging zijn voor communicatie naar belanghebbenden. En laten we reëel zijn: de belangen kunnen groot zijn. Reputatie, klantenverlies, tijd besteed aan schadebeheersing, om er maar een paar te noemen. Agile-methodologieën kunnen helpen deze belangen zo laag mogelijk te houden.
Velen van jullie zijn waarschijnlijk al bekend met de vier kernwaarden van het agile-manifest: 1) Individuen en interacties over processen en tools, 2) werkende software via uitgebreide documentatie, 3) samenwerking met klanten over contractonderhandeling, en 4) reageren op verandering volgens een plan. Laten we er wat meer op ingaan en kijken hoe ze kunnen worden gebruikt voor agile incidentcommunicatie.
Principe van incidentcommunicatie: mensgerichte incidentcommunicatie
Dit principe is gebaseerd op de agile waarde, mensen en hun onderlinge interactie boven processen en tools. Processen en tools zijn belangrijk voor alle processen voor incidentmanagement, maar ze betekenen niets als ze worden gezien als los van de mensen die ze proberen te gebruiken en de cultuur die om hen heen is gevormd. Wat is de lijm die de gaten tussen mensen, processen en tools opvult? Communicatie natuurlijk!
Communicatie is cruciaal wanneer er zich een issue voordoet, of het nu gaat om een kleine bug in de productie of een volledige systeemstoring. Zelfs het meest complete incidentplan vereist frequente communicatie om tot een oplossing te komen en het vertrouwen te behouden.
Tijdens een incident ervaren de getroffen gebruikers hoogstwaarschijnlijk frustrerende – zo niet ronduit slopende – fouten en moeten ze zo snel mogelijk weten wat er aan de hand is. Velen zullen al mailen, tweeten en/of tickets indienen over de issue, dus het is in ieders belang om snel de situatie te begrijpen met een bericht waaruit blijkt dat je weet dat er iets mis is en een oplossing zoekt. Bij Atlassian gebruiken we Statuspage om te communiceren met interne en externe belanghebbenden tijdens downtime en denken we dat jij ook snel de waarde zult vinden wanneer je op een snelle, schaalbare manier informatie over incidenten naar je gebruikers wilt verzenden. In feite heeft Statuspage gebruikers geholpen de snelheid van hun incidentcommunicatie met maar liefst 50% te verhogen.
Meld je aan of log in op Statuspage >>
Als je ingelogd bent, lees je meer over best practices voor het abonneren van je eindgebruikers en het effectief communiceren tijdens een incident:
- Blader door onze introductiehandleiding om de basisprincipes van het instellen en beheren van je statuspagina te leren
- Lees meer over best practices voor incidentcommunicatie
- Meer informatie over het instellen van meldingen voor eindgebruikers
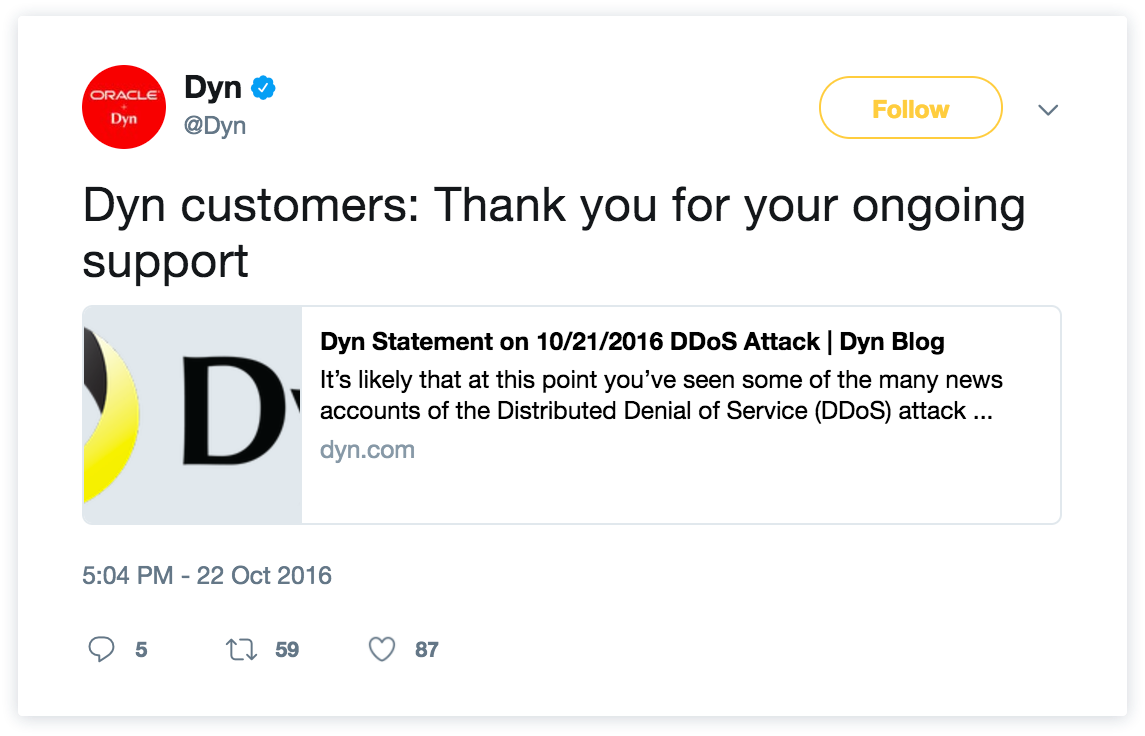
Maar welke tool je ook gebruikt om je klanten informatie te bieden, mensgerichte communicatie helpt enorm. Er zijn echte mensen aan de andere kant van het probleem die op jouw service vertrouwen en op jou vertrouwen om ze op de hoogte te houden als er iets niet klopt. Hoewel sjablonen geweldig zijn in een perfecte wereld, heb je mensen nodig die duidelijke, beknopte, empathische en relevante berichten kunnen maken om het vertrouwen van klanten op te bouwen, zelfs in de slechtste tijden. Neem bijvoorbeeld Dyn. Ze hadden een enorme uitval tijdens een van de grootste DDoS-aanvallen in de geschiedenis, maar gebruikers hadden hen nog steeds bedankt voor de openhartigheid die ze toonden tijdens die uren van onderbroken service:
Zoals Werner Vogels, de Chief Technology Officer van AWS, zei bij het bespreken van de grote AWS S3-storing in februari 2017:
"Klanten houden niet van advies met de tekst 'zit stil, doe niets'. Nee, dat is niet wat ze willen, en daarvoor moet je ze echt goede informatie geven, ze laten begrijpen wat er gebeurt, gezien de verwachting wanneer de service weer online komt als je dergelijke informatie hebt."
Principe van incidentcommunicatie: barrièrevrije pagina-creatie en incidentupdates
Voor dit principe kijken we naar de agile waarde, werkende software boven allesomvattende documentatie. Documentatie over je product moet duidelijk en gebruiksvriendelijk zijn en wij vinden dat updates van incident dat ook moeten zijn! Je gebruikers hoeven niet tussen de regels door te lezen (of lange alinea's te lezen) om te weten wat er mis gaat en wanneer ze een oplossing kunnen verwachten. Hoewel je wel moet nadenken over je incidentupdates en ervoor moet zorgen dat je empathisch en menselijk bent in je communicatie, moet je goedkeuringsgates of meerdere herzieningen frequente, eerlijke updates niet in de weg laten staan.
Als je het Dyn-incident opnieuw bekijkt, kun je zien dat hun team geen tijd verspilt aan het communiceren van updates aan hun gebruikers. In de loop van het meer dan 11 uur durende incident hebben ze hun statuspagina 11 keer bijgewerkt (gemiddeld 61 minuten tussen updates). Hun statuspagina stelde hen in staat om één plek te hebben om over het incident te communiceren, in plaats van tijd te besteden aan het vinden van de mailinglijsten om e-mails te sturen of uit te zoeken hoe ze updates in 140 tekens op Twitter konden plaatsen. Met andere woorden, ze brachten de boodschap naar buiten terwijl ze zich nog steeds voornamelijk concentreerden op het opnieuw activeren van hun service.

Het mooie van een kant-en-klare statuscommunicatietool is dat je niet veel tijd hoeft te besteden aan het opzetten van een solide pagina. Het duurt minder dan 30 minuten om een statuspagina te maken, en net als agile kan en moet je statuspagina iteratief zijn. Denk erover om een werkende pagina online te krijgen voor je klanten en deze vervolgens gaandeweg te verbeteren. Nadat je een aantal incidenten hebt verwerkt met de statuspagina als onderdeel van je proces, kun je aanpassingen aanbrengen om te blijven verbeteren.
Klaar om je eigen statuspagina te maken? Meld je aan of log in op Statuspage >>
Wacht niet tot je volgende incident om een statuspagina te maken. Besteed er nu een paar minuten aan, zodat je je in de best mogelijke positie bevindt wanneer de downtime toeslaat. Vergeet niet dat je niet veel tijd hoeft te besteden aan het opzetten van een pagina om het werk gedaan te krijgen:
- Meer informatie over hoe je je statuspagina kunt aanpassen
- Laat je inspireren door voorbeelden van uitstekend ontwerp en aanpassing van statuspagina
Principe van incidentcommunicatie: transparante communicatie tijdens incidenten en daarna
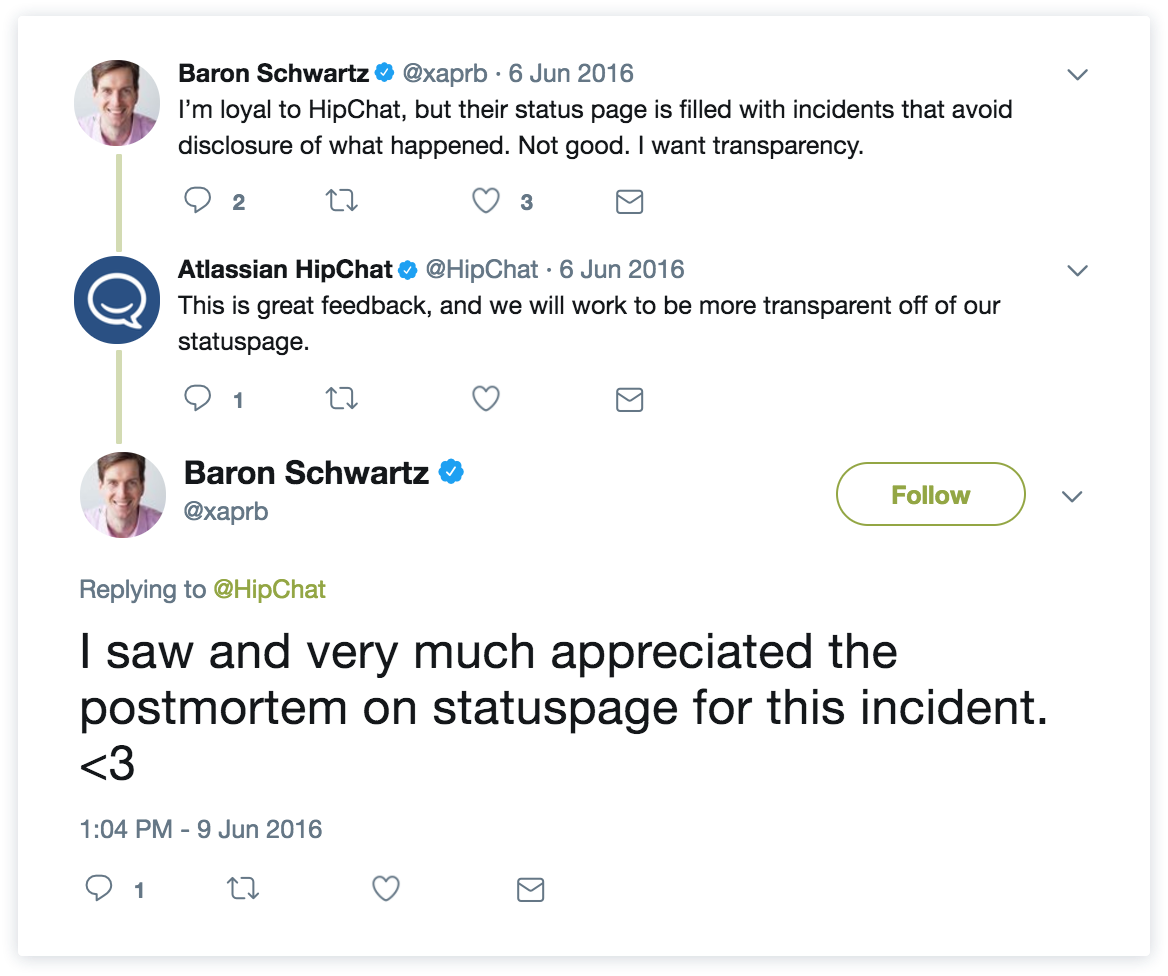
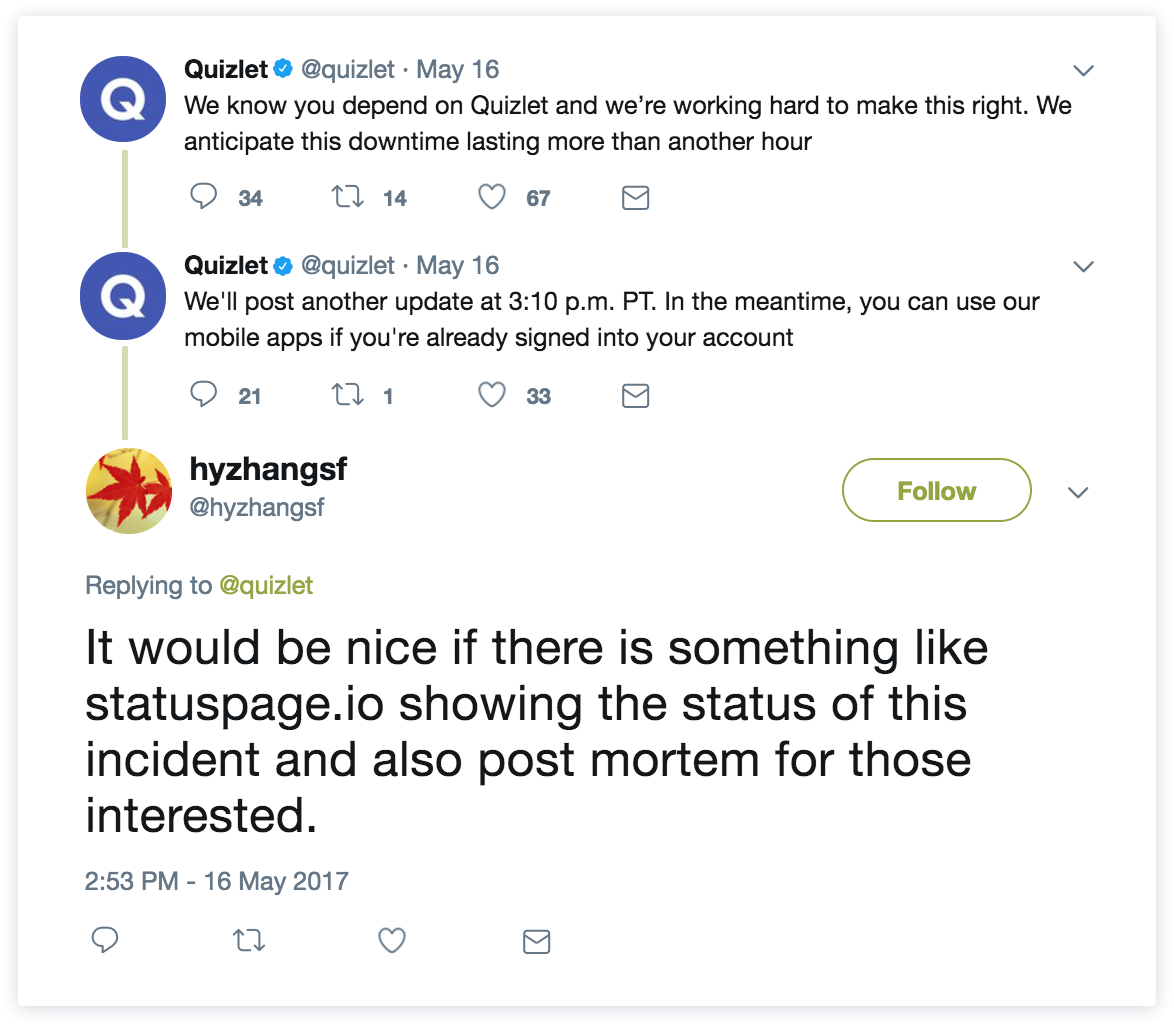
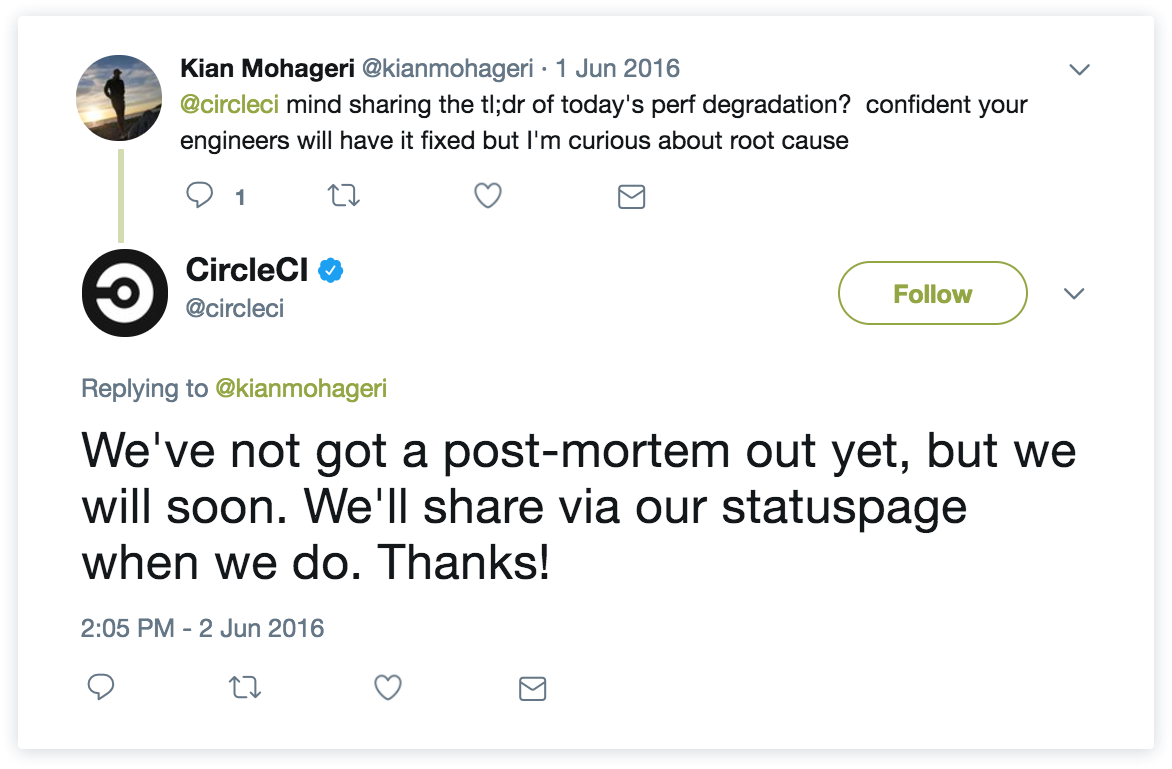
Bij deze agile waarde Samenwerking met de klant boven contractonderhandelingen draait alles om het samenwerken met je klanten om het best mogelijke product en de best mogelijke ervaring te bieden. Voor ons betekent dit dat er goede feedbackkanalen zijn ingesteld, zodat klanten hun zorgen kunnen uiten en je kunnen waarschuwen als ze problemen hebben (met behulp van tools zoals Jira Service Management, Twitter, enz.). Bedrijven van wereldklasse begrijpen dat klanten een reactie op hun feedback verwachten en betrokken willen worden bij het aanbrengen van verbeteringen aan je product en je incidentresponsproces. Enige empathie en uitleg gaan ver en klanten zijn niet bang om erom te vragen, zoals je kunt lezen in deze tweets:
Dit betekent ook dat je transparant moet blijven over je uptime, zodat gebruikers precies waar ze mee te maken hebben als ze zich aanmelden. Wanneer je je aanmeldt voor een cloudservice, vertrouw je erop dat die service betrouwbaar is. Het is niet altijd een fysiek contract, maar eerder een inherent contract dat wordt onderhandeld tussen een klant en een serviceprovider dat wanneer er iets misgaat, de twee partijen zullen samenwerken om ervoor te zorgen dat dingen snel worden opgelost en iedereen op de hoogte wordt gehouden van onderzoek tot oplossing. Dat brengt ons bij onze uiteindelijke waarde met betrekking tot reageren op verandering ...
Principe van incidentcommunicatie: agile retrospectieven
Zelfs de beste plannen ... enzovoorts. Vergelijkbaar met de agile waarde, Reageren op veranderingen in plaats van het volgen van een plan, weten we dat zelfs de best doordachte plannen onvermijdelijk moeten veranderen, zowel tijdens als na een incident. Agile heeft alles te maken met het kunnen schakelen in een mum van tijd en het krijgen van snelle en constante feedback die je product en cultuur verbetert.
Wistia, een hostingbedrijf voor internetvideo's en analyses, leerde hoe belangrijk het was om wendbaar te blijven tijdens een onverwacht incident in 2013 waardoor hun statistiekinfrastructuur tot stilstand kwam. Ze waren niet voorbereid, waardoor ze overspoeld werden met supporttickets van ontevreden klanten. Hun eerste omschakeling was het maken van hun eigen statuspagina om hun leven in dit soort situaties gemakkelijker te maken. Maar door hun eigen statuscommunicatietool te creëren, ondersteunden ze nu naast hun kernproduct nog een nieuw product. Het werd duidelijk dat dit een project was dat het team van 20 personen op dat moment niet kon betalen. De tweede omschakeling was om hun oplossing van eigen bodem te stoppen en naar Statuspage te gaan.
Jordan Munson, Support Engineer bij Wistia beschreef de verhuizing als volgt: "Na een paar maanden van milde frustratie over onze bijna karakterloze, maar nuttige oplossing van eigen bodem, besloten we dat we iets meer nodig hadden, iets dat niet zoveel onderhoud nodig had. Maak kennis met Statuspage. Sinds de overstap naar Statuspage hebben we kunnen doen wat we wilden doen: klanten snel en gemakkelijk op de hoogte houden van de status van onze applicatie. Het kostte maar één enorme uitval en het bouwen van een nieuw product om daar te komen. Een paar jaar doorspoelen naar de moderne tijd en ons proces ziet er veel soepeler uit. Mensen krijgen rechtstreeks updates van ons wanneer er een uitval is, ze weten waar ze naar updates moeten zoeken, en updates op onze statuspagina gaan rechtstreeks naar een aantal plaatsen."
Munson's team profiteerde echt van het negatieve (de uitval van 2013) en veranderde dit in iets bruikbaars (een nieuw, verbeterd en schaalbaar communicatieproces voor incidenten). Dit is een geweldige agile respons op verandering.
Retrospectieven zijn ook een belangrijk onderdeel van deze agile waarde. Een retrospectief geeft je team de kans om een stap terug te doen en te bespreken wat goed werkte tijdens je incidentcommunicatie, wat niet zo goed werkte, en vooral: wat je gaat doen om te voorkomen dat dezelfde problemen zich opnieuw voordoen. Geef niet toe aan de verleiding om een retro over te slaan nadat een incident is 'opgelost' of als je denkt dat je team geweldig heeft gepresteerd. Er is altijd ruimte voor verbetering als het gaat om incidentcommunicatie en er is altijd een kans om een betere verstandhouding en vertrouwen op te bouwen met je gebruikers.
Probeer dit retrospectieve spel uit het Atlassian teamdraaiboek om je team een veilige plek te bieden om na te denken en te bespreken wat goed werkt (en wat niet!) zodat je kunt verbeteren.
Als we ons eerste agile-manifest opnieuw bekijken, hebben retro's absoluut mensgerichte communicatie nodig om succesvol te zijn en blijvende resultaten te produceren. Bekijk hieronder wat taalgebruik waarmee je rekening moet houden wanneer je bespreekt hoe je incidentoplossing is verlopen tijdens een retrovergadering. Een deel van dit taalgebriol moet ook worden meegenomen in de post-mortem- of beoordeling na incident (PIR) die je naar gebruikers stuurt nadat je service opnieuw is hersteld. Agile zijn betekent voortdurend verbeteren, niet alleen in de manier waarop je incidentgerelateerde taken uitvoert, maar ook in hoe je je verhoudt tot teamgenoten en je rol vervult tijdens een stressvolle situatie.
Taal mensen | Taal product |
|---|---|
| Aannames, verwachtingen en angsten | Taken, issues, en acties |
| Motivaties, misverstanden en gedrag | Sprints, epics, story's en releases |
| Voorkeuren, relaties en respect | Mijlpalen, afhankelijkheden en data |
| Rollen en verantwoordelijkheden | Vergaderingen, agenda's, e-mails en bestanden |
Vergeet het vertrouwen niet
We praten veel over vertrouwen in agile en dat is niet anders voor deze usecase. Effectieve incidentcommunicatie vereist vertrouwen en mogelijkheden. Teams in de hele organisatie moeten zich gesterkt voelen met de goedkeuring en de kennis die nodig is om met gebruikers te communiceren over incidenten. Individuen moeten er ook op kunnen vertrouwen dat iedereen zijn toegewezen taak vervult tijdens een incidentrespons, en dat deze personen niet zullen aarzelen om aan de slag te gaan en een pauze in het proces te omarmen wanneer het onverwachte zich voordoet. Als je erop vertrouwt dat je teams effectief communiceren rond incidenten, kunnen klanten sneller worden geïnformeerd, wat op zijn beurt het vertrouwen en de loyaliteit van gebruikers aan je service zal vergroten (67% van de Statuspage-klanten zegt dat Statuspage heeft bijgedragen aan het vergroten van het vertrouwen van hun gebruikers!) Een echte win-winsituatie.
