Incidentmanagement voor razendsnelle teams
Incidentmanagement optimaliseren voor IT-activiteiten
Uitval heeft invloed op het bedrijfsresultaat.
Downtime betekent vaak niet alleen verlies van inkomsten, maar ook imagoschade, boetes op het gebied van naleving en regelgeving, verlies van klanten en een stijging van de operationele kosten en vertragingen naarmate IT-professionals andere projecten uitvoeren om incidenten op te lossen.
In een rapport van IHS wordt zelfs geschat dat downtime Noord-Amerikaanse organisaties meer dan 700 miljard dollar per jaar kost, en 78% van die kosten wordt toegeschreven aan productiviteitsverlies bij werknemers.
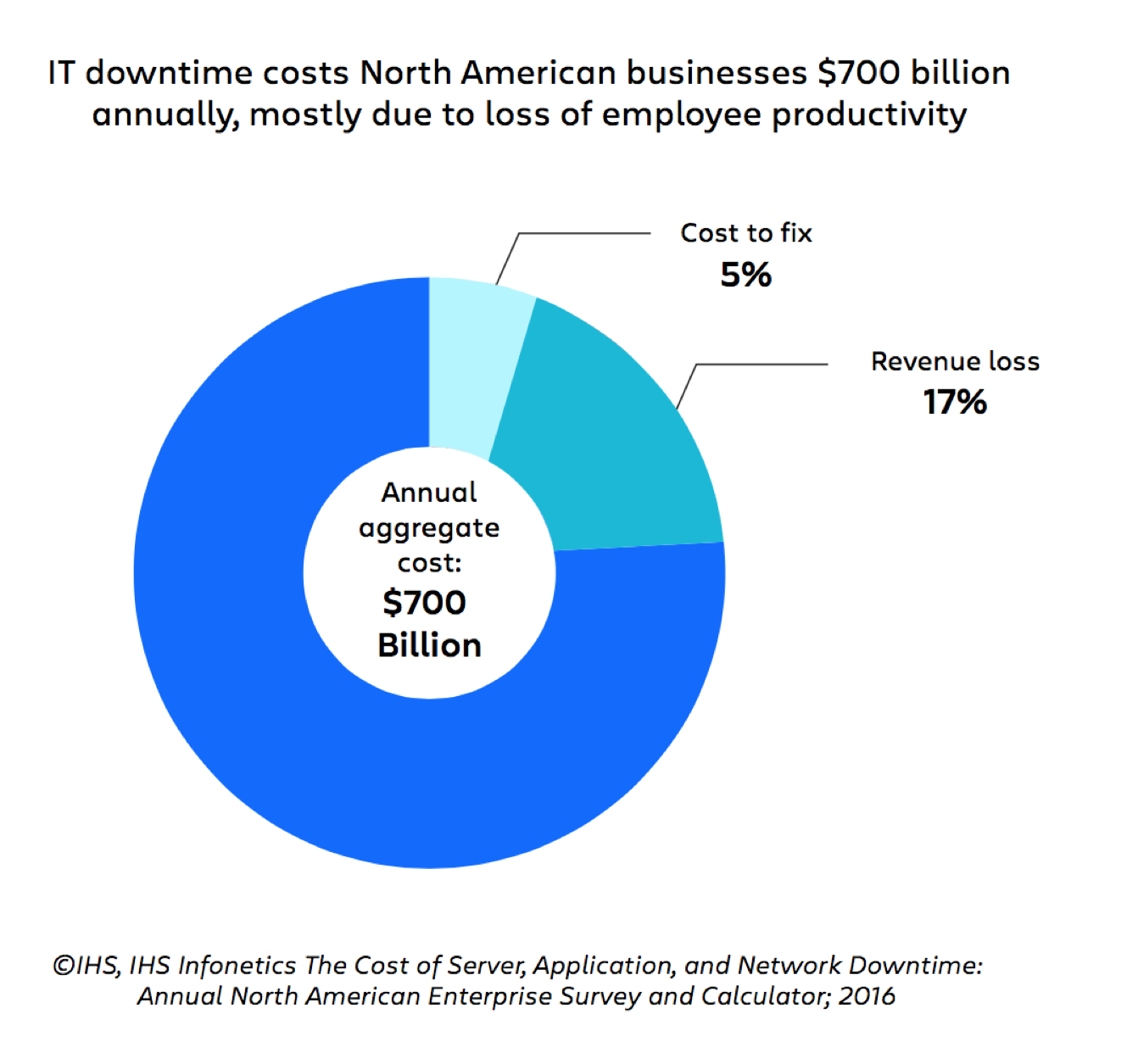
Uit cijfers zoals deze blijkt duidelijk dat gederfde inkomsten niet de enige — of zelfs de belangrijkste — prioriteit zijn voor incidentmanagement. Een geoptimaliseerd proces incidentmanagement moet ook een oplossing bieden voor de zeer reële, zeer dure uitdagingen van de mensen, processen en technologie achter incidentmanagement.
De uitdagingen van modern IT-incidentmanagement
Niet-gekoppelde processen en technologieën
Een neveneffect van 40 jaar computerinnovatie is dat veel bedrijven nu een eclectische mix van toepassingen en systemen gebruiken. Sommige toepassingen bevinden zich in hun eigen datacenters waar ze nauwkeurig kunnen worden beheerd, terwijl andere in de cloud worden geleverd en beheerd worden door externe providers.
Deze verzameling toepassingen, services en systemen resulteert vaak in een niet gekoppelde verzameling aan oplossingen en processen voor registratie, bewaking en alarmering. Het is niet ongebruikelijk dat bedrijven tientallen controletools gebruiken om elke dag duizenden gebeurtenissen of meldingen van hun toepassingen bij te houden.
Deze wirwar-benadering kan leiden tot een overweldigende hoeveelheid waarschuwingen, een storing in de communicatie, een gebrek aan duidelijke prioriteiten voor opafroepmedewerkers, en een situatie waarin een storing in een fase van deze verzameling alles plat kan leggen.
Een overweldigend aantal waarschuwingen/incidenten
Veel afdelingen voor IT-activiteiten sturen meldingen door naar e-mailboxen om het volumeprobleem tegen te gaan. Maar dat maakt de zaken alleen maar erger, waardoor een situatie ontstaat waarin e-mail 24 uur per dag moet worden gecontroleerd door gekwalificeerd personeel dat verantwoordelijk is voor het prioriteren van incidenten en het escaleren van kritieke berichten.
Deze eindeloze instroom van waarschuwingen kan overweldigend zijn en leiden tot waarschuwingsmoeheid, burn-outs, ontevredenheid onder werknemers, angst en langere responstijden. Het heeft invloed op zowel het welzijn van werknemers op de werkplek als op de productiviteit, wat weer rechtstreeks van invloed is op de bedrijfsresultaten.
Stijgende bedrijfskosten
Hoewel de infrastructuurkosten zijn gedaald, zijn de bedrijfskosten gestegen, deels als gevolg van de complexiteit van het opsporen van problemen waarbij je niet het hele systeem onder controle hebt.
De verkeerde successtatistieken meten
Het succes van de servicedesk werd vaak aan de hand van statistieken gemeten zoals gespreksdoorvoer en gemiddelde gesprekstijd, die geen van beide bijdragen aan de effectiviteit van incidentmanagement of deze meten.
Zelfs nuttige statistieken zoals MTTR en MTBF zijn op zichzelf niet voldoende om de prestaties van incidentmanagement te verbeteren. Ze zijn er om ons te helpen een probleem te identificeren, maar ze kunnen geen antwoord geven op de meer hardnekkige, kwalitatieve vragen over waarom en hoe incidenten plaatsvinden, hoe ze worden afgesloten en hoe we die statistieken kunnen verbeteren.
Verouderde teamstructuren voor incidentrespons
Nog geen tien jaar geleden was het reageren op IT-incidenten de primaire taak van operationele teams. Organisaties implementeerden doorgaans een trapsgewijze teamstructuur (niveau 1, niveau 2, niveau 3) om te reageren op door klanten of bewakingstools gemelde problemen.
De doelen van incidentmanagement waren toen hetzelfde: de operationele kosten minimaliseren met behoud van serviceniveaus. Daarom waren respondenten op niveau 1 doorgaans goedkope werknemers die nieuw waren op de arbeidsmarkt. Als ze een incident niet konden oplossen, escaleerden ze naar niveau 2 (doorgaans meer ervaren professionals uit het middensegment). Dit escalatieproces werd doorgezet totdat de issue was afgesloten.
Hoewel dit proces prioriteit geeft aan kostenbesparingen, gaat dit ten koste van flexibiliteit. De tragere responstijd van een team dat incidenten aanpakt met beginnende werknemers en meerdere escalatieniveaus vereist, kan een onmiddellijke invloed hebben op de tijdlijnen voor incidentoplossing, wat op z'n beurt weer een directe invloed heeft op de reputatie van het bedrijf, aangezien de frustratie van klanten zich over sociale media verspreidt.
Daarnaast verliezen bedrijven 78% van hun budget voor incidentmanagement aan de productiviteit van hun werknemers, waardoor het vrij duidelijk is dat een escalatiemodel niet echt winstgevend is voor een bedrijf. Als degene die de software heeft ontwikkeld de bug in 15 minuten kan verhelpen en je kersverse medewerker er twee uur over doet en het toch moet escaleren, dan is dat geen efficiënt systeem.
In een wereld van services die altijd beschikbaar moeten zijn, is flexibiliteit belangrijker dan ooit. Statistieken zoals de gemiddelde tijd tot respons en de gemiddelde tijd tot een oplossing, hebben terrein gewonnen, juist omdat bedrijven maximale flexibiliteit nodig hebben om de kosten tot een minimum te beperken.
Je IT-incidentmanagementproces optimaliseren
Het is duidelijk dat het tijd is om onze inspanningen op het gebied van incidentmanagement opnieuw te oriënteren op processen, teamstructuren en werkwijzen die de nieuwe zakelijke realiteit van nu weerspiegelen. Maar hoe ziet dat proces van opnieuw oriënteren er eigenlijk uit?
Waarschuwingen prioriteren en consolideren
De voornaamste boosdoener bij waarschuwingsmoeheid en een belangrijke oorzaak van productiviteitsverlies is een overvloed aan zinloze waarschuwingen waarbij geen actie kan worden ondernomen. De eenvoudigste oplossing? Identificeer kritieke systemen, dedupliceer redundante meldingen en creëer een duidelijke prioriteitshiërarchie voor waarschuwingen.
Een opafroeprooster maken dat werkt voor jouw teams
Om waarschuwingsmoeheid, burn-outs en inefficiënties te vermijden, moet je ook een opafroeprooster opstellen dat past bij je teams. Dit betekent dat je niet één persoon of team moet overbelasten, maar dat je waar nodig support moet bieden en dat je regelmatig de effectiviteit van je schema opnieuw moet bekijken.
Automatiseer waar je kunt
Je kunt eenvoudig je focus verliezen als je handmatig tientallen rapporten moet doornemen om te identificeren welke er geëscaleerd moeten worden. Maar gelukkig hoeft dit niet meer handmatig door iemand in het team gedaan te worden en kan met behulp van automatisering verloren productiviteit weer worden ingehaald en waarschuwingsmoeheid worden voorkomen.
Waarschuwingen routeren, meldingen, deduplicatie, workflows voor berichten, aanmaken van conferentiekoppelingen, statuspagina-updates, opafroeproosters, escalatieprocessen en KPI-tracking kunnen ook geheel of gedeeltelijk worden geautomatiseerd om het team tijd te besparen en menselijke fouten bij vaste, herhalende taken te verminderen. Om nog maar te zwijgen over het feit dat automatisering het bedrijf op termijn geld bespaart.
Effectief communiceren tussen kanalen en belanghebbenden
Incidenten hebben gevolgen voor verschillende belanghebbenden, vaak zowel intern als extern, en deze belanghebbenden moeten worden geïnformeerd. Uit onderzoek blijkt dat 87% van de belanghebbenden uit het bedrijfsleven op de hoogte wil blijven van incidenten (en 56% is meer gefrustreerd door een gebrek aan communicatie dan door het incident zelf). En klanten denken daar precies hetzelfde over.
In een tijd waarin verwacht wordt dat alles altijd maar beschikbaar is, is een robuust incidentcommunicatieplan een essentieel onderdeel van de optimalisatiepuzzel.
Eenvoudig de juiste statistieken bijhouden
Hoe makkelijker het is om successtatistieken bij te houden en te beoordelen, hoe groter de kans dat je team ze bijhoudt. Automatiseer de rapportage waar mogelijk en zorg ervoor dat je van tevoren duidelijk in beeld hebt welke statistieken belangrijk zijn voor je team en waarom.
Postmortems zonder schuldvraag uitvoeren
Een incident is nog niet voorbij omdat de app of database weer online is. Om incidenten te voorkomen, minder tijd te besteden aan toekomstige incidenten en om beter te begrijpen hoe je processen, teams en beleid van invloed zijn op je incidentmanagement, moet je postmortem uitvoeren.
Bij Atlassian zijn onze postmortems zonder schuldvraag, wat betekent dat ze zich richten op het verbeteren van de prestaties en vooruitgang, zonder iemand als schuldige aan te wijzen.
Technologie kiezen die je aansluit op je processen en behoeften
Automatisering. Prioritering van waarschuwingen. Opafroeproosters. KPI-tracking. Al deze processen moeten ondersteund worden door technologie om effectief te kunnen zijn. Voordat je een technologie kiest, moet je je doelen, processen en behoeften van je team begrijpen. Als je meldingen automatisch wilt organiseren, dedupliceren en prioriteren, heb je een oplossing nodig die deze functies bevat: bijvoorbeeld Jira Service Management.
Ontdek incidentcommunicatie met Statuspage
In deze tutorial laten we je zien hoe je incidentsjablonen kunt gebruiken om effectief te communiceren tijdens storingen. Aanpasbaar voor de vele soorten serviceonderbrekingen.
Lees deze tutorialSjablonen en voorbeelden voor incidentcommunicatie
Bij het reageren op een incident zijn communicatiesjablonen van onschatbare waarde. Download de sjablonen die onze teams gebruiken, plus meer voorbeelden voor veelvoorkomende incidenten.
Lees dit artikel