Incidentmanagement voor razendsnelle teams
MTBF, MTTR, MTTA en MTTF
Inzicht in enkele van de meest voorkomende statistieken voor incidenten
Vandaag de dag hebben storingen en technische incidenten grotere gevolgen dan ooit tevoren. Storingen en downtime hebben reële consequenties: gemiste deadlines. Te late betalingen. Projectvertragingen.
Daarom is het belangrijk voor bedrijven om statistieken te kwantificeren en bij te houden over uptime, downtime en hoe snel en effectief teams problemen oplossen.
Enkele van de meest frequent bijgehouden statistieken in de branche zijn MTBF (gemiddelde tijd voor een storing), MTTR (gemiddelde tijd tot herstel, reparatie, reactie of oplossing), MTTF (gemiddelde tijd tussen storingen) en MTTA (gemiddelde tijd tot bevestiging). Deze statistieken werden ontwikkeld zodat technische teams begrijpen hoe vaak incidenten voorkomen en hoe snel het team die incidenten kan oplossen.
Veel experts stellen dat deze statistieken op zichzelf eigenlijk niet zo nuttig zijn, omdat ze niet de rommeligere vragen stellen over hoe incidenten worden opgelost, wat werkt en wat niet, en hoe, wanneer en waarom problemen escaleren of deëscaleren.
Aan de andere kant kunnen MTTR, MTBF en MTTF een goede basis of benchmark zijn die gesprekken op gang helpen die naar diepere, belangrijke vragen leiden.

Zo reageren de professionals op grote incidenten
Ontvang ons gratis handboek voor incidentmanagement. Leer alle tools en technieken die Atlassian gebruikt om grote incidenten te beheren.
Een disclaimer over MTTR
Als we het over MTTR hebben, is het eenvoudig om aan te nemen dat het één statistiek is met één betekenis. Maar in werkelijkheid vertegenwoordigt hij mogelijk vier verschillende metingen. De R kan staan voor repareren, herstellen, reageren, of oplossen – en hoewel de vier statistieken elkaar overlappen, hebben ze elk hun eigen betekenis en nuance.
Mocht je team het dus hebben over het bijhouden van MTTR, dan is het een goed idee om duidelijk te krijgen welke MTTR ze bedoelen en hoe ze die definiëren. Voordat je successen en mislukkingen meet, moet je team op één lijn zitten over wat je precies volgt en ervoor zorgen dat iedereen weet dat het over hetzelfde gaat.
Gemiddelde tijd tussen storingen
Wat is de gemiddelde tijd tussen storingen?
MTBF (gemiddelde tijd tussen storingen) is de gemiddelde tijd tussen herstelbare storingen van een technologieproduct. De statistiek wordt gebruikt om zowel de beschikbaarheid als de betrouwbaarheid van een product bij te houden. Hoe langer de tijd tussen storingen, hoe betrouwbaarder het systeem.
Het doel voor de meeste bedrijven om het MTBF zo hoog mogelijk te houden, met een tijd van honderdduizenden (of zelfs miljoenen) uren tussen verschillende storingen.
Hoe bereken je de gemiddelde tijd tussen fouten
MTBF wordt berekend op basis van een rekenkundig gemiddelde. Dit betekent in feite dat je de gegevens moet nemen van de periode die je wilt berekenen (misschien zes maanden, misschien een jaar, misschien vijf jaar) en de totale operationele tijd van die periode moet delen door het aantal storingen.
Stel dat we een periode van 24 uur beoordelen en dat er 2 uur downtime was bij twee afzonderlijke incidenten. Onze totale uptime is 22 uur. Gedeeld door twee, dat is 11 uur. Dus onze MTBF is 11 uur.
Omdat de statistiek wordt gebruikt om de betrouwbaarheid bij te houden, houdt MTBF geen rekening met de verwachte uitvaltijd tijdens gepland onderhoud. In plaats daarvan richt de waarde zich op onverwachte storingen en problemen.
De oorsprong van de gemiddelde tijd tussen storingen
MTBF is afkomstig uit de luchtvaartsector, waar systeemstoringen bijzonder grote gevolgen hebben – niet alleen qua kosten, maar ook qua mensenlevens. Het initialisme heeft sindsdien zijn weg gevonden in verschillende technische en mechanische industrieën en wordt vooral vaak gebruikt in de productie.
Hoe en wanneer je de gemiddelde tijd tussen storingen moet gebruiken
MTBF is nuttig voor kopers die zeker willen zijn van het meest betrouwbare product, die het meest betrouwbare vliegtuig willen besturen of die de veiligste productieapparatuur voor hun fabriek willen kiezen.
Voor interne teams is dit een statistiek die helpt om problemen in kaart te brengen en successen en mislukkingen bij te houden. De waarde kan bedrijven ook helpen om weloverwogen aanbevelingen te ontwikkelen over wanneer klanten een onderdeel moeten vervangen, een systeem moeten upgraden of een product moeten retourneren voor onderhoud.
MTBF is een statistiek voor storingen in herstelbare systemen. Voor storingen die een vervanging van het systeem vereisen, gebruiken mensen doorgaans de term MTTF (gemiddelde tijd tot storing).
Denk bijvoorbeeld aan een automotor. Om de tijd tussen ongepland motoronderhoud te berekenen, zou je MTBF — de gemiddelde tijd tussen storingen – kunnen gebruiken. Om de tijd tussen het vervangen van de volledige motor te berekenen, gebruik je dan MTTF (gemiddelde tijd tot storing).
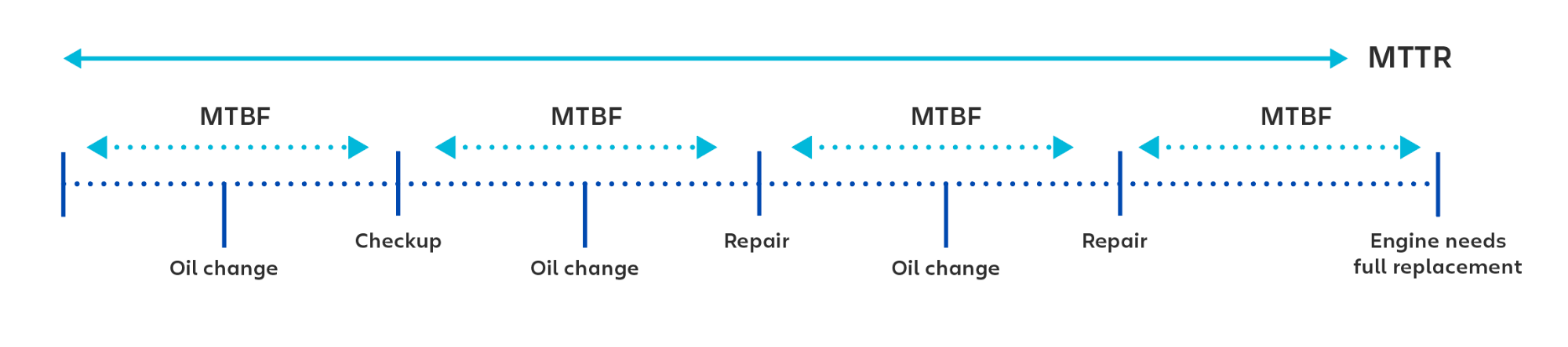
MTTR: Gemiddelde tijd tot reparatie
Wat is een gemiddelde tijd tot reparatie?
MTTR (gemiddelde tijd tot reparatie) is de gemiddelde tijd die nodig is om een systeem te repareren (meestal technisch of mechanisch). De meetwaarde omvat zowel de reparatietijd als de eventuele testtijd. Bij deze statistiek stopt de klok niet totdat het systeem weer volledig functioneert.
Hoe bereken je de gemiddelde reparatietijd?
Je kunt MTTR berekenen door de totale tijd die gedurende een bepaalde periode aan reparaties is besteed bij elkaar op te tellen en die tijd vervolgens te delen door het aantal reparaties.
Stel dat we kijken naar reparaties gedurende een week. In die tijd waren er 10 storingen en werden de systemen gedurende 4 uur actief gerepareerd. Vier uur is 240 minuten. 240 gedeeld door 10 is 24. Wat betekent dat de reparatietijd in dit geval 24 minuten is.
De beperkingen van de gemiddelde tijd tot reparatie
De gemiddelde tijd voor reparatie is niet altijd even lang als de systeemstoring zelf. In sommige gevallen beginnen de reparaties binnen enkele minuten na een defect aan het product of een systeemstoring. In andere gevallen is er een vertraging tussen het issue, het moment waarop het issue wordt ontdekt en het moment waarop de reparatie begint.
Deze statistiek is vooral handig om bij te houden hoe snel het onderhoudspersoneel een issue kan verhelpen. De statistiek is niet bedoeld om problemen met je systeemwaarschuwingen of vertragingen voorafgaand aan reparaties te identificeren – beide ook belangrijke factoren bij het beoordelen van de successen en mislukkingen van je incidentmanagementprogramma's.
Hoe en wanneer je de gemiddelde tijd tot reparatie moet gebruiken
MTTR is een statistiek die support- en onderhoudsteams gebruiken om te zorgen dat reparaties op schema blijven. Het doel is om dit aantal zo laag mogelijk te houden door de efficiëntie van reparatieprocessen en -teams te verhogen.
MTTR: Gemiddelde tijd tot herstel
Wat is een gemiddelde tijd tot herstel?
MTTR (gemiddelde tijd tot herstel of gemiddelde tijd om te herstellen) is de gemiddelde tijd die nodig is om te herstellen na een product- of systeemstoring. Dit omvat de volledige duur van de storing, vanaf het moment dat het systeem of product uitvalt tot het moment dat het weer volledig operationeel is.
Het is, zoals opgemerkt door DevOps Research and Assessment (DORA), een belangrijke DevOps-statistiek die kan worden gebruikt om de stabiliteit van een DevOps-team te meten.
Hoe bereken je de gemiddelde tijd tot herstel?
De gemiddelde tijd tot herstel wordt berekend door alle downtime in een bepaalde periode bij elkaar op te tellen en te delen door het aantal incidenten. Stel dat onze systemen 30 minuten niet beschikbaar waren tijdens twee afzonderlijke incidenten in een periode van 24 uur. 30 gedeeld door twee is 15, dus onze MTTR is 15 minuten.
De beperkingen van de gemiddelde tijd tot herstel
Deze MTTR is een maatstaf voor de snelheid van je volledige herstelproces. Gaat het zo snel als jij wilt? Hoe verhoudt de waarde zich tot die van je concurrenten?
Dit is een statistiek op hoog niveau die je helpt vast te stellen of je een probleem hebt. Maar als je wilt vaststellen waar het probleem in je proces zit (is dat een probleem met je waarschuwingssysteem? Doet het team er te lang over om oplossingen te vinden? Duurt het te lang voordat iemand reageert op een verzoek om een oplossing?) , je hebt meer gegevens nodig. Er gebeurt immers meer dan één ding tussen een storing en een herstel.
Het probleem kan te maken hebben met je waarschuwingssysteem. Is er een vertraging tussen een storing en een waarschuwing? Duurt het langer dan nodig is om meldingen bij de juiste persoon te krijgen?
Het probleem kan te maken hebben met de diagnose. Kun je er snel achter komen wat het probleem is? Zijn er processen die verbeterd kunnen worden?
Het probleem kan ook te maken hebben met reparaties. Zijn je onderhoudsteams zo effectief als ze zouden kunnen zijn? Stel dat zij de meeste tijd nodig hebben, waar komt dat door?
Je zult dieper moeten kijken dan MTTR om die vragen te beantwoorden, maar de tijd tot herstel kan een startpunt zijn om te diagnosticeren of er een probleem is met je herstelproces waarvoor je dieper moet graven.
Hoe en wanneer je de gemiddelde tijd tot herstel moet gebruiken
MTTR is een goede statistiek om de snelheid van je totale herstelproces te beoordelen.
MTTR: Gemiddelde tijd tot oplossing
Wat is een gemiddelde tijd tot oplossing?
MTTR (gemiddelde tijd om het probleem op te lossen) is de gemiddelde tijd die nodig is om een storing volledig op te lossen. Dit omvat niet alleen de tijd die is besteed aan het opsporen van de storing en aan het diagnosticeren en verhelpen van het probleem, maar ook de tijd die nodig is om ervoor te zorgen dat de storing zich niet opnieuw voordoet.
Deze statistiek vergroot de verantwoordelijkheid van het team dat de oplossing afhandelt om de prestaties op lange termijn te verbeteren. Het is het verschil tussen een brand blussen en een brand blussen en vervolgens je huis brandveilig maken.
Er is een sterk verband tussen deze MTTR en klanttevredenheid, dus het is wel een factor om aandacht aan te besteden.
Hoe bereken je de gemiddelde tijd tot oplossing?
Om deze MTTR te berekenen, tel je de volledige tijd tot het vinden van een oplossing in de periode die je wilt bijhouden bij elkaar op. Daarna deel je die tijd door het aantal incidenten.
Dus als je systemen in totaal 2 uur waren uitgevallen binnen een periode van 24 uur als gevolg van 1 incident en teams nog eens 2 uur besteedden aan het bedenken van oplossingen om te voorkomen dat het systeem opnieuw uitvalt, dan is er in totaal 4 uur besteed aan het oplossen van het probleem. Dat betekent dat je MTTR 4 uur is.
Een opmerking over het bijhouden van de gemiddelde tijd tot oplossing
Houd er rekening mee dat MTTR meestal wordt berekend op basis van kantooruren (dus als je op een dag herstelt van een issue bij sluitingstijd en de volgende ochtend tijd aan het oplossen van het onderliggende issue besteedt, dan bedraagt je MTTR niet de 16 uur die je niet op kantoor hebt doorgebracht). Als je teams op meerdere locaties hebt die dag en nacht werken of als je oproepmedewerkers hebt die buiten kantooruren werken, is het belangrijk om te bepalen hoe je de tijd bijhoudt voor deze meetwaarde.
Hoe en wanneer je de gemiddelde tijd tot oplossing moet gebruiken
MTTR wordt doorgaans gebruikt voor ongeplande incidenten, niet voor serviceverzoeken (die doorgaans gepland zijn).
MTTR: Gemiddelde tijd tot reactie
Wat is een gemiddelde tijd tot reactie?
MTTR (de gemiddelde tijd om te reageren) is de gemiddelde tijd die nodig is om te herstellen na een product- of systeemstoring, vanaf het moment dat de fout voor het eerst gemeld wordt. Hierbij wordt de eventuele vertraging in je waarschuwingssysteem niet meegerekend.
Hoe bereken je de gemiddelde tijd tot reactie?
Om deze MTTR te berekenen, moet je de volledige reactietijd vanaf de waarschuwing tot het moment waarop het product of de service weer volledig functioneel is, bij elkaar optellen. Deel de uitkomst daarna door het aantal incidenten.
Voorbeeld: Stel dat je 4 incidenten had in een werkweek van 40 uur en daar in totaal 1 uur aan zou besteden (van waarschuwing tot oplossing), dan zou je MTTR voor die week 15 minuten bedragen.
Hoe en wanneer je de gemiddelde tijd tot reactie moet gebruiken
Deze MTTR wordt vaak gebruikt bij cyberbeveiliging om te meten in hoeverre een team erin slaagt systeemaanvallen te neutraliseren.
MTTA: Gemiddelde tijd tot bevestiging
Wat is de gemiddelde tijd tot bevestiging?
MTTA (gemiddelde tijd tot bevestiging) is de gemiddelde tijd die nodig is vanaf het moment dat een waarschuwing wordt geactiveerd tot het moment waarop wordt begonnen met het werken aan de oplossing. Deze statistiek is handig om bij te houden hoe snel je team reageert en hoe effectief je waarschuwingssysteem is.
Hoe bereken je de gemiddelde tijd tot bevestiging?
Om je MTTA te berekenen, tel je de tijd tussen waarschuwingen en de bevestiging ervan bij elkaar op. De uitkomst deel je door het aantal incidenten.
Voorbeeld: Stel dat er 10 incidenten waren en er zat in totaal 40 minuten tussen de waarschuwing en bevestiging voor alle 10, dan deel je 40 door 10 en kom je uit op gemiddeld 4 minuten.
Hoe en wanneer je de gemiddelde tijd tot bevestiging moet gebruiken
MTTA is nuttig om het reactievermogen bij te houden. Lijdt je team aan waarschuwingsmoeheid en duurt het te lang om te reageren? Deze statistiek helpt je om het issue aan de kaak te stellen.
MTTF: Gemiddelde tijd tussen storingen
Wat is de gemiddelde tijd tussen storingen?
MTTF (gemiddelde tijd tot storingen) is de gemiddelde tijd tussen onherstelbare storingen van een technologieproduct. Als de automotoren van merk X bijvoorbeeld gemiddeld 500.000 uur meegaan voordat ze volledig uitvallen en moeten worden vervangen, dan bedraagt de MTTF van de motoren 500.000.
De berekening wordt gebruikt om te begrijpen hoe lang een systeem doorgaans meegaat, om te bepalen of een nieuwe versie van een systeem beter presteert dan het oude, en om klanten informatie te geven over de verwachte levensduur en wanneer ze systeemcontroles moeten plannen.
Hoe bereken je de gemiddelde tijd tussen storingen
De gemiddelde tijd tot een storing is een rekenkundig gemiddelde. Je berekent die dan ook door de totale gebruiksduur van de producten die je beoordeelt bij elkaar op te tellen en dat totaal te delen door het aantal apparaten.
Bijvoorbeeld: Stel dat je de MTTF van lampen aan het uitzoeken bent. Hoe lang gaan lampen van merk Y gemiddeld mee voordat ze doorbranden? Laten we verder zeggen dat je 4 lampen hebt om te testen (als je statistisch significante gegevens wilt, heb je veel meer nodig dan dat, maar met het oog op eenvoudige berekeningen houden we dit klein).
Gloeilamp A gaat 20 uur mee. Gloeilamp B gaat 18 uur mee. Lamp C gaat 21 uur mee. En lamp D gaat 21 uur mee. Dat zijn in totaal 80 lampuren. Gedeeld door vier bedraagt de MTTF 20 uur.

Het probleem van de gemiddelde tijd tussen storingen
Wanneer je een voorbeeld gebruikt, zoals lampen, is MTTF een heel zinvolle statistiek. We kunnen de lampen laten branden tot de laatste uitvalt en die informatie gebruiken om conclusies te trekken over de veerkracht van onze lampen.
Maar wat gebeurt er als we dingen meten die niet zo snel falen? Dingen die jaren mee zouden moeten gaan? In die gevallen wordt MTTF weliswaar vaak gebruikt, maar de statistiek is dan een minder bruikbaar. Want in plaats van een product te laten draaien totdat het niet meer werkt, gebruiken we een product meestal gedurende een bepaalde tijd en meten we hoeveel fouten er optreden.
Voorbeeld: Stel dat we MTTF-statistieken proberen te krijgen voor de tablets van merk Z. Tablets zijn hopelijk bedoeld voor jarenlang gebruik. Maar merk Z heeft misschien maar zes maanden de tijd om gegevens te verzamelen. En dus test het bedrijf 100 tabletten gedurende zes maanden. Stel dat 1 tablet precies na 6 maanden niet meer werkt.
We vermenigvuldigen dan de totale gebruiksduur (6 maanden vermenigvuldigd met 100 tabletten) en komen uit op 600 maanden. Slechts één tablet werkte niet, dus als we dat door 1 zouden delen, zou onze MTTR 600 maanden zijn. Dat komt neer op 50 jaar.
Gaan de tablets van merk Z gemiddeld 50 jaar mee? Dat is vrij onwaarschijnlijk. En dus laat de meetwaarde het er in dergelijke gevallen bij zitten.
Hoe en wanneer je de gemiddelde tijd tussen storingen moet gebruiken
MTTF werkt goed als je probeert de gemiddelde levensduur te bepalen van producten en systemen met een korte levensduur (zoals lampen). De meetwaarde is ook alleen bedoeld voor gevallen waarin je beoordeelt of het product volledig defect is. Als je de tijd berekent tussen incidenten die moeten worden gerepareerd, is MTBF (gemiddelde tijd tussen storingen) het initialisme bij uitstek.
MTBF versus MTTR versus MTTF versus MTTA
Welke meting is dus beter als het gaat om het traceren en verbeteren van incidentmanagement?
Eigenlijk zijn ze allemaal goed.
Hoewel ze soms door elkaar worden gebruikt, geeft elke statistiek een ander inzicht. Wanneer ze samen worden gebruikt, kunnen ze een vollediger verhaal vertellen over hoe succesvol je team is op het gebied van incidentmanagement en waar verbeterkansen voor het team liggen.
Gemiddelde tijd tot herstel vertelt je hoe snel je je systemen weer aan de praat kunt krijgen.
Verwerk ook de gemiddelde tijd tot een reactie. Je krijgt dan een idee hoeveel van de hersteltijd is toe te schrijven aan het team en hoeveel aan je waarschuwingssysteem.
Kijk ook naar de gemiddelde tot reparatie en je begint te zien hoeveel tijd het team besteedt aan reparaties versus diagnostiek.
Tel daar nog de gemiddelde tijd tot de oplossing van problemen bij op en je begint de volledige omvang te begrijpen van het oplossen van problemen tot voorbij de daadwerkelijke downtime.
Met de gemiddelde tijd tussen storingen wordt het beeld nóg groter zie je hoe succesvol je team is in het voorkomen of verminderen van toekomstige problemen.
En voeg dan de gemiddelde tijd tot storingen nog toe om de volledige levenscyclus van een product of systeem te begrijpen.
Jira Service Management biedt rapportagefuncties zodat je team KPI's kan bijhouden en je methoden voor incidentmanagement kan monitoren en optimaliseren.
Producten besproken
Centraliseer waarschuwingen en stuur meldingen naar de juiste mensen op het juiste moment.
Ontdek incidentcommunicatie met Statuspage
In deze tutorial laten we je zien hoe je incidentsjablonen kunt gebruiken om effectief te communiceren tijdens storingen. Aanpasbaar voor de vele soorten serviceonderbrekingen.
Lees deze tutorialSjablonen en voorbeelden voor incidentcommunicatie
Bij het reageren op een incident zijn communicatiesjablonen van onschatbare waarde. Download de sjablonen die onze teams gebruiken, plus meer voorbeelden voor veelvoorkomende incidenten.
Lees dit artikel