Incidentmanagement voor razendsnelle teams
Je KPI's en statistieken kiezen voor incidentmanagement
Incidentmanagement in de loop der tijd volgen en verbeteren
In de wereld van nu waarin alle service altijd beschikbaar moeten zijn, hebben technische incidenten grote gevolgen.
Systeemuitval kost bedrijven gemiddeld $ 300.000 per uur aan verloren inkomsten, productiviteit van werknemers en onderhoudskosten. Grote storingen kunnen die kosten zelfs nog meer overtreffen (vraag het maar aan Delta Airlines, die in 2017 ongeveer $ 150 miljoen verloor na een IT-storing). En klanten die hun rekeningen niet kunnen betalen, een belangrijke videovergadering niet kunnen bijwonen of een ticket niet kunnen kopen, stappen al snel over naar de concurrent.
Nu er zoveel op het spel staat, is het voor teams belangrijker dan ooit om de KPI's voor incidentmanagement bij te houden en hun bevindingen te gebruiken om incidenten op te sporen, te diagnosticeren, op te lossen en, uiteindelijk, te voorkomen.
Het goede nieuws is dat bij incidenten met internet en software (in tegenstelling tot mechanische en offline systemen) teams doorgaans veel meer gegevens kunnen vastleggen om ze de incidenten te helpen begrijpen en zelf te verbeteren.
Het slechte nieuws? Soms kunnen problemen ondergesneeuwd raken door de hoeveelheid gegevens in plaats van dat ze helpen te verklaren.
De waarde van KPI's, statistieken en analyses voor incidenten
KPI's (Key Performance Indicators) zijn statistieken die bedrijven helpen te bepalen of ze specifieke doelen bereiken. Voor incidentmanagement kunnen deze statistieken het aantal incidenten, de gemiddelde tijd tot oplossing op te lossen of de gemiddelde tijd tussen incidenten zijn.
Door KPI's bij te houden voor incidentmanagement kun je problemen helpen identificeren en diagnosticeren met behulp van processen en systemen, vastgestelde benchmarks en realistische doelen voor het team om naartoe te werken, en een startpunt leveren voor grotere vragen.
Stel bijvoorbeeld dat het bedrijf ernaar streeft om alle incidenten binnen 30 minuten op te lossen, maar je team heeft momenteel gemiddeld 45 minuten. Zonder specifieke statistieken is het moeilijk om erachter te komen waar het mis gaat. Is je waarschuwingssysteem te traag? Werkt je proces niet goed? Moeten je diagnostische tools worden bijgewerkt? Is dat een teamprobleem of een technisch probleem?
Voeg nu wat statistieken toe: als je precies weet hoe lang het waarschuwingssysteem erover doet, kun je dat als een probleem identificeren of uitsluiten. Als je ziet dat diagnostiek meer dan 50% van de tijd in beslag neemt, kun je je concentreren op deze problemen. Als je ziet dat Team B 25% meer tijd in beslag neemt dan teams A, C en D, dan kun je daar beginnen met uitzoeken wat er mis is.
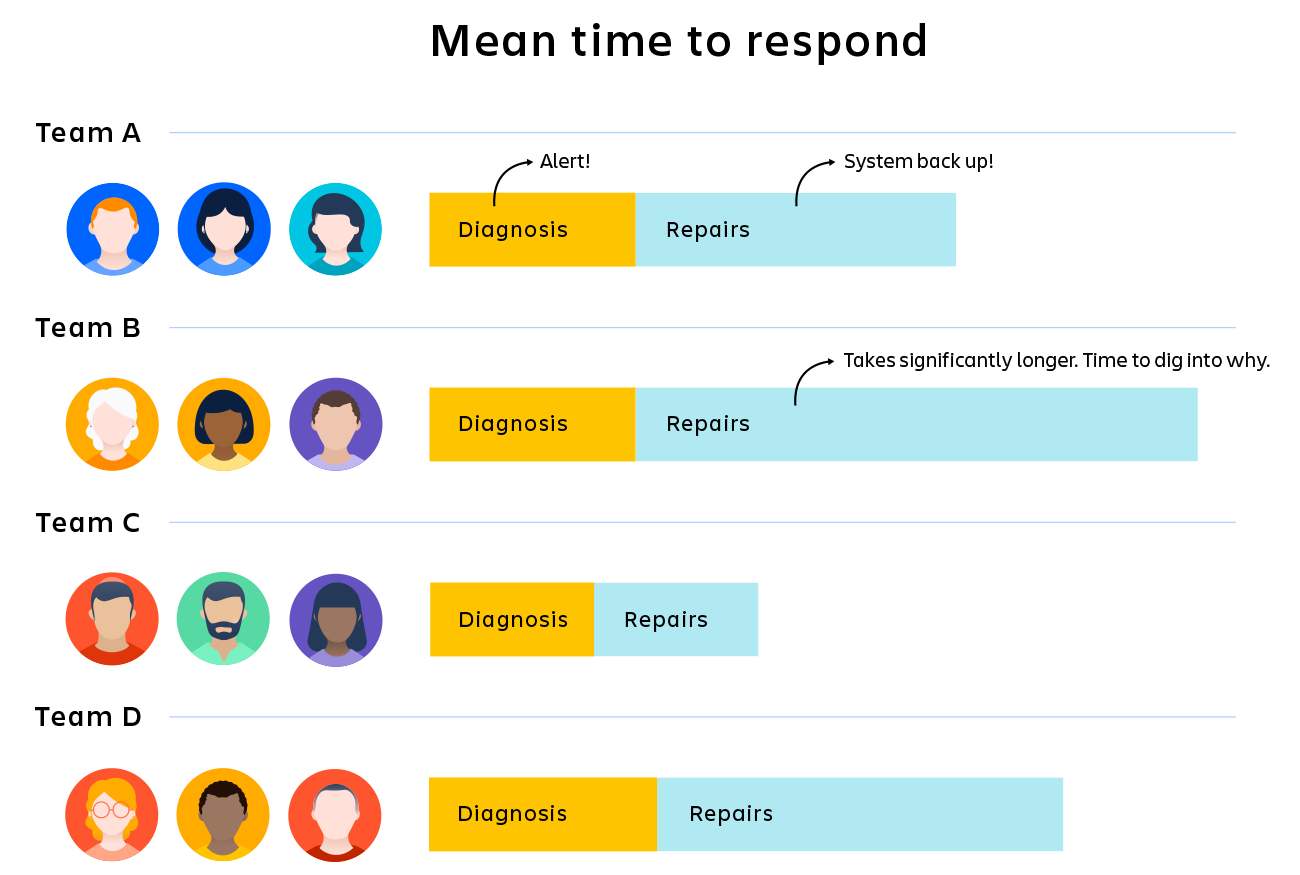
KPI's lossen je problemen niet automatisch op, maar ze helpen je te begrijpen waar het probleem ligt en je energie te richten op het verder uitzoeken van de juiste probleempunten.
Populaire KPI's en statistiek voor incidenten
Aangemaakte waarschuwingen
Als je een waarschuwingstool gebruikt, is het handig om te weten hoeveel meldingen er in een bepaalde periode worden gegenereerd. Met een oplossing zoals Jira Service Management kun je zowel waarschuwingen versturen als rapporten en dashboards activeren om ze te volgen.
Let op periodes met aanzienlijke, ongebruikelijke stijgingen of dalingen of cijfers met een stijgende trend, en als je ze hebt gespot, verdiep je dan eens in waarom die veranderingen plaatsvinden en hoe je teams deze aanpakken.
Incidenten na verloop van tijd
Incidenten in de loop der tijd volgen betekent kijken naar het gemiddelde aantal incidenten over een periode. Dit kan wekelijks, maandelijks, elk kwartaal, jaarlijks en zelfs dagelijks zijn.
Komen incidenten in de loop der tijd meer of minder vaak voor? Is het aantal incidenten acceptabel of kunnen het er wel wat minder zijn? Zodra je een issue hebt geïdentificeerd met behulp van het aantal incidenten, kun je beginnen met vragen stellen over waarom dat aantal stijgt of hoog blijft en wat het team kan doen om dit probleem op te lossen.
MTBF
MTBF (Mean Time between Failures, gemiddelde tijd tussen storingen) is de gemiddelde tijd tussen herstelbare storingen van een technologieproduct. Het kan je helpen de beschikbaarheid en betrouwbaarheid van alle producten bij te houden.
Net als bij andere statistieken is het een goed startpunt voor bredere vragen. Als je MTBF korter is dan je zou willen, is het tijd om je af te vragen waarom de systemen zo vaak uitvallen en hoe je toekomstige storingen kunt verminderen of voorkomen.
MTTA
MTTA (Mean Time to Acknowledge, gemiddelde tijd tot erkenning) is de gemiddelde tijd die nodig is vanaf het moment dat er een systeemwaarschuwing wordt uitgegeven tot wanneer een teamlid het incident erkent en aan de oplossing begint te werken. Het is belangrijk om te begrijpen hoe goed je team reageert op problemen.
Als je eenmaal weet dat er een probleem is met het reactievermogen, kun je weer verder gaan graven. Waarom is jouw MTTA lang? Zijn teams overbelast? Afgeleid? Is het onduidelijk wie verantwoordelijk is voor een waarschuwing? MTTA kan je helpen een probleem te identificeren, en vragen als deze kunnen je helpen om het probleem op te lossen.
MTTD
MTTD (Mean Time to Detect, gemiddelde tijd tot opsporing) is de gemiddelde tijd die je team nodig heeft om een probleem op te sporen. Deze term wordt vaak gebruikt in cyberbeveiliging wanneer teams zich richten op het opsporen van aanvallen en inbreuken.
Als deze statistiek drastisch verandert of niet helemaal klopt, is het weer tijd om te vragen waarom.
MTTR
MTTR kan de gemiddelde tijd tot reparatie, oplossing (resolve), respons of herstel (recovery) betekenen. De nuttigste statistiek is hierbij ongetwijfeld de gemiddelde tijd tot oplossing, waarmee niet alleen de tijd wordt bijgehouden die gespendeerd wordt aan diagnose en directe problemen oplossen, maar ook de tijd die gebruikt wordt op ervoor te zorgen dat een probleem zich niet weer voordoet. Herstel is een primaire DevOps-statistiek die volgens DevOps Research and Assessment (DORA) van groot belang is om de stabiliteit van een DevOps-team te meten.
Nogmaals, deze statistiek is het beste als deze diagnostisch wordt gebruikt. Is je tijd tot oplossing precies zo snel en efficiënt als je wilt? Zo niet, dan is het tijd om verder te vragen over hoe en waarom de tijd tot een oplossing zo lang duurt.
Deze is, volgens DevOps Research and Assessment (DORA), een belangrijke DevOps-statistiek die kan worden gebruikt om de stabiliteit van een DevOps-team te meten. Het is de totale tijd die nodig is om een probleem op te sporen, te verlichten en oplossen.
Opafroeptijd
Als je een opafroeprooster hebt, kan het handig zijn om bij te houden hoeveel tijd werknemers en contractanten op afroep zijn. Deze statistiek kan je helpen ervoor te zorgen dat geen enkele werknemer of team overbelast is.
Met Jira Service Management kun je uitgebreide rapporten genereren om deze cijfers in één oogopslag te zien.
SLA
Een SLA (Service Level Agreement) is een overeenkomst tussen de provider en de klant over meetbare statistieken zoals uptime, respons en verantwoordelijkheden.
De beloften die in SLA's worden gedaan (over uptime, gemiddelde tijd tot herstel enz.) zijn een van de redenen waarom incidentmanagementteams deze statistieken moeten bijhouden. Als en wanneer dingen als gemiddelde tijd tot respons of gemiddelde tijd tussen storingen veranderen, moeten contracten worden bijgewerkt en/of fixes (snel) uitgevoerd worden.
SLO
Een SLO (Service Level Objective) is een overeenkomst binnen een SLA over een specifieke statistiek, zoals uptime. Net als bij de SLA zelf zijn SLO's belangrijke statistieken om bij te houden om ervoor te zorgen dat het bedrijf zich aan de afspraak houdt met betrekking tot de service.
Tijdstempels (of tijdlijn)
Een tijdstempel is gecodeerde informatie over wat er op bepaalde momenten tijdens, voor of na het incident is gebeurd. Deze informatie wordt doorgaans niet als een statistiek gezien, maar het zijn belangrijke gegevens om te kunnen beoordelen hoe het met je incidentmanagement staat en om strategieën te bedenken om te verbeteren.
Tijdstempels helpen teams bij het opzetten van een tijdlijn voor het incident, samen met de inspanningen voor de aanloop en de respons. Een duidelijke, gedeelde tijdlijn is een van de nuttigste artefacten tijdens een incidentpostmortem.
Bedrijfstijd
Uptime is de hoeveelheid tijd (weergegeven als een percentage) dat je systemen beschikbaar en functioneel zijn.
De toenemende connectiviteit van online services en de toenemende complexiteit van de systemen zelf betekenen dat er doorgaans niet zoiets bestaat als een gegarandeerde uptime van 100%. Het doel van de meeste producten is een hoge beschikbaarheid: een systeem of product dat gedurende lange tijd zonder onderbreking operationeel is. Volgens de standaard in de sector is een uptime van 99,9% erg goed en 99,99% zelfs uitstekend.
Je mate van succes bijhouden met behulp van deze statistiek draait volledig om beloftes aan de klant doen en houden. En, net als bij andere statistieken, is het nog maar een beginpunt. Als je uptime niet 99,99% is, zal de vraag waarom meer onderzoek, gesprekken met je team en uitpluizen van je proces, structuur, toegang en technologie vergen.
Een waarschuwing over incidentanalyse
Het nadeel van KPI's is dat het eenvoudig is om te afhankelijk te worden van oppervlakkige gegevens. Als je weet dat je team incidenten niet snel genoeg oplost, kom daarmee niet vanzelf tot een oplossing. Omdat je nog steeds moet weten hoe en waarom het team problemen wel of niet oplost. Daarnaast moet je nog steeds weten of de problemen die je vergelijkt daadwerkelijk vergelijkbaar zijn.
KPI's kunnen je niet vertellen hoe je teams omgaan met lastige kwesties. Ze kunnen niet uitleggen waarom de tijd tussen je incidenten steeds korter wordt in plaats van langer. Ze kunnen je niet vertellen waarom incident A drie keer zo lang duurde als incident B.
Daarvoor heb je inzichten nodig. En hoewel de gegevens een startpunt kunnen zijn op weg naar die inzichten, kunnen ze ook een struikelblok vormen. Ze kunnen je het gevoel geven dat je genoeg doet, zelfs als deze statistieken niet verbeteren. Ze kunnen incidenten in een rijtje zetten die in feite heel verschillend zijn en die anders moeten worden aangepakt. Ze kunnen een negatieve invloed hebben op de ervaring van je teams en op de onderliggende complicaties van incidenten zelf.
"Incidenten zijn veel unieker dan klassieke wijsheid je zou doen geloven. Twee incidenten van dezelfde lengte kunnen twee drastisch verschillende niveaus van verrassing en onzekerheid hebben met betrekking op hoe iemand erachter komt wat er aan de hand is. Ze kunnen ook heel verschillende risico's met zich meedragen als het gaat om acties nemen die bedoeld zijn om de situatie te verlichten of verbeteren. Incidenten zijn geen widgets die worden gemaakt, waarbij beperkte variatie in fysieke afmetingen worden gezien als belangrijke kwaliteitskenmerken."
- John Allspaw in het artikel Moving Past Shallow Incident Data
Het punt is niet dat KPI's slecht zijn. We vinden dat je het kind niet met het badwater moet weggooien. Het punt is dat KPI's niet voldoende zijn. Ze zijn een beginpunt. Ze zijn een diagnostisch hulpmiddel. Ze zijn de eerste stap op een complexere weg naar echte verbetering.
Jira Service Management biedt rapportagefuncties zodat je team KPI's kan bijhouden en je methoden voor incidentmanagement kan monitoren en optimaliseren.
Een op afroep-rooster opstellen met Opsgenie
In deze tutorial leer je hoe je een op afroep-rooster instelt, overschrijfregels toepast, op afroep-meldingen configureert en meer, allemaal binnen Opsgenie.
Lees deze tutorialSjablonen en voorbeelden voor incidentcommunicatie
Bij het reageren op een incident zijn communicatiesjablonen van onschatbare waarde. Download de sjablonen die onze teams gebruiken, plus meer voorbeelden voor veelvoorkomende incidenten.
Lees dit artikel