Incidentmanagement voor razendsnelle teams
Best practices voor incidentcommunicatie
Incidenten zijn altijd een feit geweest voor mensen in IT en Ops. Tegenwoordig volgen ook DevOps en klantenserviceteams een spoedcursus in incidentcommunicatie.
Incidentcommunicatie is het proces dat gebruikers waarschuwt als een service een storing heeft of verslechterde prestaties levert. Dit is vooral belangrijk voor web- en softwareservices waarvan verwacht wordt dat ze 24 uur per dag beschikbaar zijn.
Incidentcommunicatie op webschaal is complexer dan alleen het verzenden van een bulk-e-mail. Er zijn verschillende doelgroepen om te overwegen. Verschillende drempels voor berichten- en responsverwachtingen.
Aangezien enige downtime onvermijdelijk is, is het het beste om vooruit te plannen en ervoor te zorgen dat je team er klaar voor is.
Dit is onze gids voor best practices voor incidentcommunicatie. We behandelen:
- Waarom communicatie over incidenten belangrijk is
- Voorbereiden op communicatie over incidenten
- Hoe professionals op het gebied van incidentcommunicatie deze taak aanpakken
- Waarom de incidentcommunicatie niet stopt na het incident
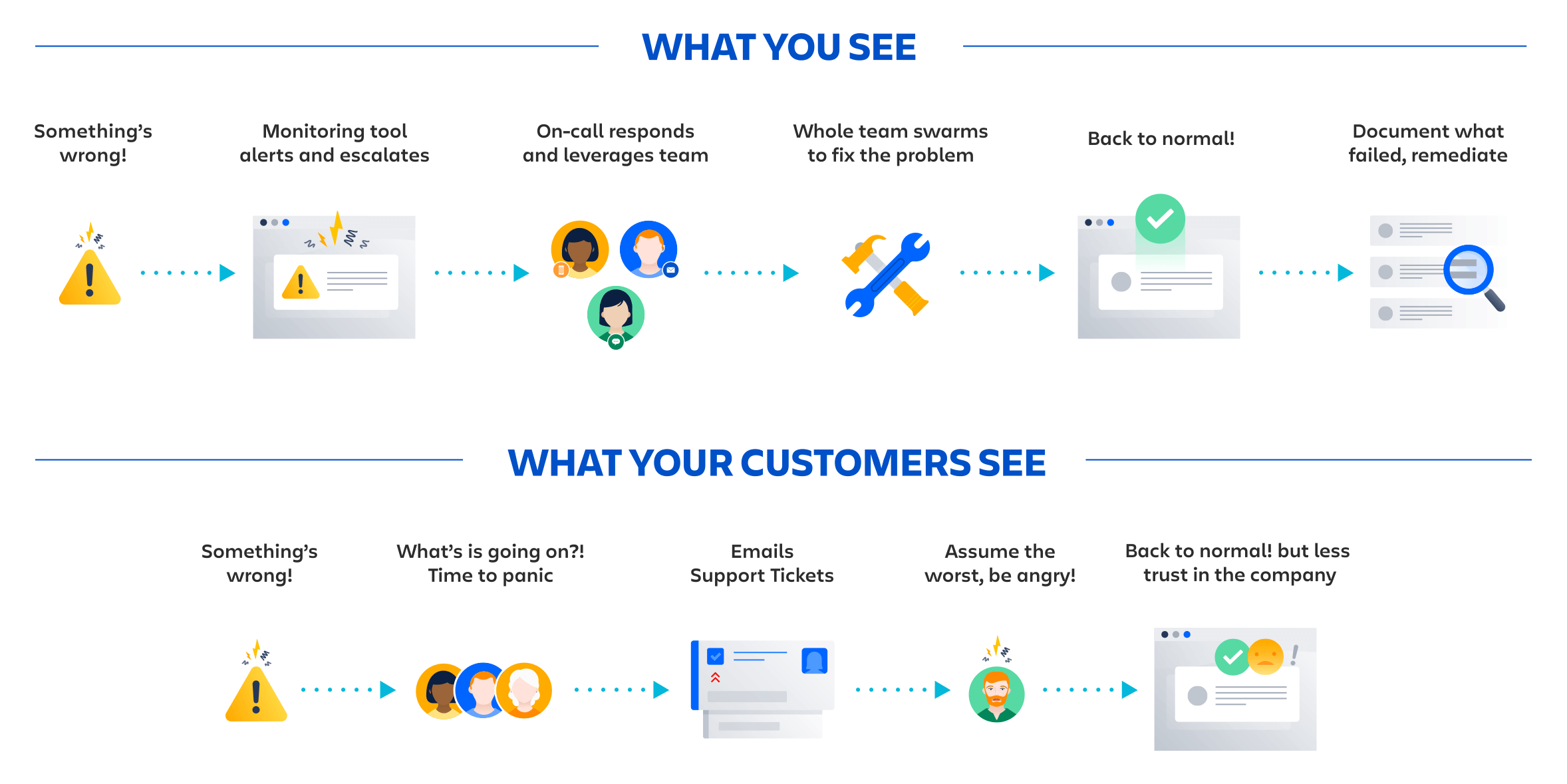
Communicatie over incidenten: wie boeit dat?
Je klanten vinden het belangrijk. Je collega's vinden het belangrijk. Jij zou het belangrijk moeten vinden. Slecht afgehandelde downtime kan een hele slechte ervaring zijn voor je klanten en je teams, wat weer van invloed kan zijn op je bedrijfsresultaten. Een aantal van je klanten maken zich misschien zorgen dat ke meer slechte ervaringen in petto voor ze hebt en stappen over naar een concurrent. Je verliest toekomstige klanten door gebrek aan vertrouwen. Het moreel van het team kan eronder lijden en leiden tot een lagere productiviteit. En zeg maar vaarwel tegen al die geweldige mond-tot-mondreclame.
Gelukkig hoeft ongeplande downtime geen nachtmerrie voor de klantenservice te worden. Het blijkt dat als je je klanten gewoon op de hoogte houdt door te communiceren wat er gebeurt en wat je doet om het probleem op te lossen, ze het zullen begrijpen en een veel minder negatieve reactie op de hele situatie zullen hebben.
Voorbereiden op incidentcommunicatie
Een goede voorbereiding voorkomt slechte prestaties. Als dat een slogan is die goed genoeg is om de strijd aan te gaan, is het goed genoeg voor je incidentcommunicatiestrategie. Als je in middenin een incident zit, zul je jezelf dankbaar zijn dat je tijd besteedt aan incidentcommunicatie.
Definiëren wat je als incident beschouwt
Voordat we over incidenten kunnen communiceren, moeten we beslissen wat een incident is. Veel webbedrijven vertrouwen op een gestandaardiseerd 4-laags ernstdefinitiesysteem. Hier is een geweldige gids over ernstdefinities uit ons eigen incidentengids.
Wat jouw drempels ook zijn voor de ernst van incident, het is belangrijk om dit duidelijk te definiëren (idealiter rond een soort meetbare statistiek). Als je een incident aanwijst op Ernst 1, is het belangrijk dat iedereen in je team precies weet wat dat betekent.
Een ernstsysteem is ook nuttig om de inherente vaagheden die gepaard gaan met downtime te elimineren.
Het maakt niet uit welk systeem je kiest, we raden een zero-tolerance communicatieplan aan voor incidenten met beveiligingsproblemen of gegevensverlies.
Van tevoren je communicatieoplossingen, kanalen en berichtsjablonen kiezen
Professionele supportteams en technici voor de betrouwbaarheid van de site beslissen niet direct via welke kanalen ze moeten communiceren. Ze maken van tevoren een plan.
Er zijn zes belangrijke communicatiekanalen voor incidentcommunicatie:
- Een speciale statuspagina
- Geïntegreerde status
- E-mailadres
- Chattool op de werkplek
- Sociale media
- Sms
Een speciale statuspagina
We raden teams aan een speciale statuspagina te gebruiken als hun primaire oplossing voor incidentcommunicatie. Of je het nu zelf bouwt of kiest voor een gehoste oplossing zoals Statuspage, het is belangrijk om je klanten en collega's een duidelijke bron van waarheid te geven tijdens een incident. Statuspage geeft je gebruikers ook de mogelijkheid om zich te abonneren om updates te ontvangen op het moment dat ze gepubliceerd worden. Dit neemt de supportlast weg bij teams die het probleem bij de staart moeten pakken om het op te lossen.
Geïntegreerde status
Statuspage maakt het ook eenvoudig om statusinformatie rechtstreeks beschikbaar te maken op elke website die klanten gebruiken. We weten dat de meeste bezoekers waarschijnlijk de startpagina of supportpagina van een provider zullen controleren voordat ze op zoek gaan naar een statuspagina. De embedded widget (hier een voorbeeld) is een eenvoudige manier om die bezoekers te laten weten of er een incident aan de gang is. Bezoekers kunnen ook op widget doorklikken om naar de statuspagina te gaan.
E-mailadres
Je kunt je bezoekers de mogelijkheid geven om zich te abonneren op e-mailupdates met een product als Statuspage. Of je nou rechtstreeks vanuit je e-mailtool verzendt of een statuspagina gebruikt om e-mailverzendingen te activeren, e-mail een betrouwbaar kanaal voor incidentcommunicatie.
Chat-tools
Zorg voor minder contextwisselingen en informatiekloven voor medewerkers en agents met Jira Service Management-chat. Jira Service Management-chat synchroniseert gesprekken in Slack of Microsoft Teams met je tickets. Naadloze gesprekken tussen populaire chattools en support helpen een robuuste context voor een probleem te leveren, wat weer leidt tot een snellere oplossing.
Sociale media
Veel teams gebruiken sociale kanalen zoals Twitter als communicatiemiddel tijdens een incident. Het is goed om dit als onderdeel van je strategie te gebruiken, maar vertrouw er niet op als je enige communicatiemiddel.
Sms
Het ontvangen van een sms of tekstbericht, is vaak een directere manier om iemand te bereiken. En veel mensen geven er de voorkeur aan als het gaat om kritieke inkomende waarschuwingen zoals een aankondiging van downtime. Het is ook een kanaal waar mensen snel vermoeid kunnen raken en zich afmelden als ze te veel berichten krijgen die niet relevant voor hen zijn.
Geen van deze kanalen is een wondermiddel voor incidentcommunicatie. Ze hebben allemaal verschillende sterke punten en de echte kracht komt wanneer je ze gecombineerd gebruikt. Bij Atlassian plaatsen we bijvoorbeeld incidenten op een statuspagina, maar publiceren we die updates ook op Twitter. Een aankondiging over het incident is ook zichtbaar op onze Jira Service Management Management-portal. Deze berichten leiden de gebruiker vervolgens terug naar de statuspagina voor meer informatie over het incident. Het beheren van incidenten in Jira Service Management maakt meerdere communicatiepunten mogelijk zonder dat er verwarring optreedt of het vertrouwen van je klanten in de uitvoering verloren gaat.
Waarschuwingen en communicatie afstemmen op de juiste doelgroep
Wanneer zich een incident voordoet, moet je weten met wie je moet communiceren, hoe je hen kunt bereiken en hoe je dit moet doen door zo min mogelijk wrijving te veroorzaken en zo min mogelijk middelen te gebruiken om het ook voor de klantenservice soepel te laten verlopen en/of een communicatiemeltdown te voorkomen. Het is het beste om intern te beginnen met een team die direct reageert en door naar buiten toe te werken en berichten voor de juiste doelgroep samen te stellen.
Hoewel elke organisatie anders is, helpt het in het algemeen om deze doelgroepen te zien als vijf verschillende groepen waarmee gecommuniceerd moet worden:
- Het kernteam voor op afroep: de eersten die weten dat er iets mis is, vrijwel onmiddellijk na impact (meestal via bewakings- en waarschuwingstools). Interne teams werken achter de schermen om incidenten te detecteren, op te sporen, te contextualiseren en op te lossen met gezamenlijke communicatietools.
- Eerstelijns supportteam: degenen die tijdens het incident rechtstreeks vragen beantwoorden en klanten updates geven. Het is een ongelooflijk belangrijke rol, dus dit team moet de juiste informatie krijgen om door te geven aan eindgebruikers.
- Managers en uitvoerend team: het kernteam moet met deze groep communiceren, zodat ze weten wat er aan de hand is, wat de mogelijke impact is op de volgende twee groepen en zodat ze hopelijk een schatting kunnen maken van hoe lang het gaat duren.
- Algemeen personeel: werknemers moeten op de hoogte worden gehouden naarmate de diensten waarop ze vertrouwen, uitvallen en weer beschikbaar zijn. Proactief communiceren met deze gebruikers betekent dat je minder vaak hoort 'wat is de status van dit?', minder dubbele IT-supporttickets en meer focus om het probleem op te lossen.
- Externe klanten: als het incident externe klanten treft, moet er met hen worden gecommuniceerd om het probleem uit te leggen en wanneer ze een oplossing kunnen verwachten, of op zijn minst een update in vaste intervals. Voor problemen die momenteel nog steeds van invloed zijn op de mogelijkheid van je klanten om je product te gebruiken, raden we je updates met tussenpozen van nooit langer dan een uur te verzenden. Je moet ook altijd aangeven wanneer ze de volgende update kunnen verwachten. Als het een ernstig genoeg incident is, vooral een incident met betrekking tot beveiliging of gegevensverlies, wil je absoluut de externe communicatie versnellen en de nodige andere teams inschakelen (juridisch, HR, beveiliging enz.)
Sjablonen instellen voor communicatie over incident en uitval
Wanneer je middenin een incident zit, is het laatste waar je je zorgen over wilt maken hoe je een incidentaankondiging kunt schrijven. Het incident op de verkeerde manier verwoorden is een perfect doelwit voor niet-technische managers die misschien op zoek zijn naar een reden om kritiek te leveren op het responsproces van je team.
Bepaal van tevoren het gemeenschappelijke taalgebruik, laat deze goedkeuren door je managers en sla deze op in een sjabloon. Dit maakt het eenvoudig om de relevante gegevens in te vullen en in gevaal van een incident te publiceren.
Hier zijn twee van de incidentsjablonen die we gebruiken voor onze eigen statuspagina:
- De site wordt momenteel meer dan normaal geladen en kan ervoor zorgen dat pagina's traag zijn of niet reageren. We onderzoeken de oorzaak en zullen zo snel mogelijk een update geven.
- Onze opslagprovider voor openbare statistische gegevens ondervindt momenteel problemen met de infrastructuur. Updates zullen beschikbaar worden gesteld naarmate de situatie zich ontwikkelt of informatie aan ons wordt verstrekt.
Bekijk meer voorbeelden in onze bibliotheek met incidentsjablonen.
Communicatie beheren als een professional
De levenscyclus van een incident zal waarschijnlijk meerdere contactpunten omvatten. Als deze goed in elkaar zit is er een bekende structuur met drie fases aan een incident: eerste contact, updates tijdens het incident en oplossing en postmortem.
Proloog: gecentraliseerde interne teamcommunicatie
In de eerste plaats moeten interne teams aan de back-end van een incident een gevestigd communicatieplatform hebben en klaar staan om aan het werk te gaan wanneer zich een probleem voordoet.
Het centraliseren en filteren van waarschuwingen voor bewakings-, logging- en CI/CD-tools zorgt voor een snelle respons van je team. Met een platform als Jira Service Management kunnen teams snel een incident melden, context krijgen en contact houden gedurende de hele duur van een incident.
Deel 1: Eerste contact
De eerste update is het belangrijkste. Alles, van wat je zegt, tot hoe en wanneer je het zegt, zet de toon voor hoe je respons wordt ontvangen. Op dit moment helpt het echt om een sjabloon te hebben dat vooraf is ingesteld.
Je doel zou moeten zijn om de issue snel te erkennen, de bekende impact kort samen te vatten, verdere updates te beloven en, als je daartoe in staat bent, eventuele zorgen over beveiliging of gegevensverlies weg te nemen. Het is belangrijk om te erkennen dat er een issue is, zelfs als je de exacte details nog niet weet.
Deel 2: Regelmatige updates tijdens het incident
Communicatie halverwege incidenten is van cruciaal belang.
De SRE-teams van Google vermelden Communication Lead als een van de sleutelrollen die tijdens een incident moet overzien.
Uit Google's boek Site Reliability Engineering, over de rol van de communicatieleider:
"Deze persoon is het publieke gezicht van de incidentrespons-taskforce. De taken van deze rol omvatten sowieso het verstrekken van periodieke updates aan het incidentresponsteam en belanghebbenden (meestal via e-mail) en kunnen zich uitstrekken tot taken zoals het nauwkeurig en up-to-date houden van het incidentdocument."
Deze persoon is ook verantwoordelijk voor het blijven updaten van de statuspagina of het plaatsen van updates op andere kanalen naarmate de situatie verandert. Zelfs een update met de tekst 'We werken nog steeds aan het probleem, niets nieuws om te melden', is beter dan niets zeggen en je klanten laten hangen. Mensen die in het donker zijn achtergelaten, beginnen het ergste te verwachten.
Communicatie met getroffen gebruikers en andere belanghebbenden is absoluut noodzakelijk. Gebruik je vooraf bepaalde kanalen om gebruikers te vertellen wat er aan de hand is. Op de startpagina kan dit een Statuspage-waarschuwing zijn om klanten te tonen dat je team op de hoogte is van het probleem waardoor agents tijd besparen door niet iedere persoon apart te hoeven inlichten. Houd klanten op de hoogte via meerdere communicatiekanalen, waaronder sms, e-mail en mobiele pushmeldingen.
Welke tool je ook kiest, we raden je aan om er een te nemen als je primaire communicatiemiddel en iedereen daar vanaf de andere kanalen naartoe te leiden. Het beheren van incidentcommunicatie via Jira Service Management zorgt ervoor dat de juiste berichten bij de juiste mensen terechtkomen.
Deel 3: Resolutie, postmortem en wat er daarna komt
In 2010 leed Facebook de grootste uitval tot nu toe. Ongeveer 2,5 uur lang was het sociale netwerk niet beschikbaar voor miljoenen van de toen half miljard gebruikers.
De timing had niet slechter kunnen zijn voor de ontluikende techgigant, die zich nog in de begindagen van zijn explosieve gebruikersgroei bevond en nog steeds aan het bedrijfsleven moest bewijzen dat de service de hype waard was.
Toen het stof neerdaalde, plaatste een Facebook-engineer een samenvatting van 395 woorden op de technische blog van het bedrijf over het incident.
Uit de blog:
Begin vandaag was Facebook ongeveer 2,5 uur niet beschikbaar of onbereikbaar voor velen van jullie. Dit is de ergste uitval die we in meer dan vier jaar hebben gehad en we willen ons er allereerst voor verontschuldigen. We wilden ook veel meer technische details geven over wat er is gebeurd en een grote les delen die we hebben geleerd.
De grote lijnen van een postmortem zijn eenvoudig:
- Erken het probleem, leef mee met de getroffenen en verontschuldig je
- Leg uit wat er mis is gegaan en waarom
- Leg uit wat er is gedaan om het incident op te lossen en wat er is gedaan om volgende incidenten te voorkomen
- Erken, leef in met en bied nogmaals excuses aan
Er is geen behoefte aan bloemrijke taal of grandioze claims in communicatie als deze. Hou het simpel en praktisch. Zoals bijvoorbeeld het Facebook-blog:
We verontschuldigen ons nogmaals voor de uitval van de site en we willen dat je weet dat we de prestaties en betrouwbaarheid van Facebook zeer serieus nemen.
Taalgebruik als dit maakt het voor je klanten en collega's eenvoudig om erop te vertrouwen dat je een nuchter team leidt dat op het probleem gefocust blijft. Blader door onze eigen sjablonen voor incidentresponspostmortems voor meer ideeën.
De realiteit van altijd beschikbare services is dat dingen soms gewoon onverwacht kapot gaan. Effectief communiceren tijdens downtime kan daadwerkelijk vertrouwen opbouwen bij zowel collega's als klanten. Er goed op reageren kan het verschil maken. We hebben ook deze eenvoudige tool ontwikkeld om je te helpen snel effectief te communiceren tijdens incidenten.
Producten besproken

Houd je gebruikers eenvoudig in realtime op de hoogte.
Ontdek incidentcommunicatie met Statuspage
In deze tutorial laten we je zien hoe je incidentsjablonen kunt gebruiken om effectief te communiceren tijdens storingen. Aanpasbaar voor de vele soorten serviceonderbrekingen.
Lees deze tutorialSjablonen en voorbeelden voor incidentcommunicatie
Bij het reageren op een incident zijn communicatiesjablonen van onschatbare waarde. Download de sjablonen die onze teams gebruiken, plus meer voorbeelden voor veelvoorkomende incidenten.
Lees dit artikel